强化学习蘑菇书第十二章模仿学习、以及DDQN、演员-评论家算法的一点补充
先分割线抒情一下哈哈。
大家好,今天一转眼datawhale的强化学习就到尾声了,一个月不到的时间,真的超快,伴随着两个多周的研究生暑校,只有晚上的时间读书学习,但幸运的是,还是坚持下来了。回首一下,第一遍虽然很多东西仓促也没有全部学懂,但是收获很大,至少,这一遍蘑菇书算是过了第一遍,有了第一遍,以后就会有第二遍、第三遍,而且,那种抵触的心理也不会再有了,感谢自己的每一点不放弃!这种感觉真好!以后还有继续努力的勇气和理由!
今天就是最后一次打卡任务了,不过,感觉日后会坚持下来写博客的这个习惯,不仅仅是一种记录吧,更是一种反思与收获,不管多忙也不能找借口,该打卡的一定要打卡,当天的任务必须当天完成,不能拖延。
上次说到稀疏奖励,按照蘑菇书纸质版的顺序的话,这一章节应该是十二章模仿学习。
模仿学习
Imitation learning,讨论问题是是假设我们没有奖励,怎么更新以及让智能体与环境进行交互?所以模仿学习又被称为示范学习、学徒学习和观察学习。无法给出明确的奖励时,可以收集专家的示范。在模仿学习中,主要学习介绍两个方法,行为克隆和逆强化学习。
这一章下面的重点都用概念给出:
行为克隆
人决定怎么样的时候,智能体也采取一样的动作,焦作行为克隆,智能体需要学会和专家一模一样的行为,如果说,当初曾一个监督学习问题的话,需要先收集很多行车记录器的数据,再收集人在具体情境下会采取什么样子的行为(训练数据)。
Question:这样只收集专家的示范是十分有限的,那么此时我们就需要结合数据集聚合的方法。(也能收集极端情况下的专家行为)
另外,行为克隆的问题还在于,训练数据与测试数据不匹配,这个时候我们也是要采用数据集聚和的方法,即train和test的时候,数据分布不一样,也就是说行为克隆可能存在问题,并不能完全解决魔方学习的问题,所以引出下一个方法,就是逆强化学习。
逆强化学习
使用逆强化学习技术的时候,机器是可以跟环境互动的。但它得不到奖励。也就是说,没有奖励函数,只有专家的示范,它的奖励必须要从专家那边推出来,有了环境和专家示范以后,去反推出奖励函数长什么样子。之前强化学习是由奖励函数反推出什么样的动作、演员是最好的。逆强化学习是反过来,我们有专家的示范,我们相信它是不错的,我就反推说,专家是因为什么样的奖励函数才会采取这些行为。你有了奖励函数以后,接下来,你就可以套用一般的强化学习的方法去找出最优演员。所以逆强化学习是先找出奖励函数,找出奖励函数以后,再去用强化学习找出最优演员。
把这个奖励函数学习出来,相较于原来的强化学习有什么样好处。一个可能的好处是也许奖励函数是比较简单的。也许,虽然这个专家的行为非常复杂,但也许简单的奖励函数就可以导致非常复杂的行为。一个例子就是也许人类本身的奖励函数就只有活着这样,每多活一秒,你就加一分。但人类有非常复杂的行为,但是这些复杂的行为,都只是围绕着要从这个奖励函数里面得到分数而已。有时候很简单的奖励函数也许可以推导出非常复杂的行为。

第三人称视角模仿学习
这块简单说的话,就是一种把第三人称视角所观察到的经验泛化为第一视角经验的技术。
演员-评论家算法
上次学的不深入,我们说,Actor-critic方法是TD方法,具有单独的内存结构,以明确表示独立于值函数的策略。策略结构被称为演员,因为它用于选择动作,而估计值函数被称为评论家,因为它评论演员所做的动作。学习总是在策略上进行:评论家必须了解并批评行为人目前正在遵循的任何政策。
Typically, the critic is a state-value function. After each action
selection, the critic evaluates the new state to determine whether
things have gone better or worse than expected.
Evaluation我们就说是TD error。
我们来看一下这个式子,其中,Vt是批评家在时间t执行的值函数。该 δ t \delta_{t} δt表示的是TD误差,这个量可用于评估刚刚选择的动作,即在状态St下采取的动作。如果TD误差为正,则表明未来应加强选择at的趋势,而如果TD误差为负,则表明应减弱趋势。
δ t = R t + 1 + γ V t ( S t + 1 ) − V ( S t ) \delta_{t}=R_{t+1}+\gamma V_{t}\left(S_{t+1}\right)-V\left(S_{t}\right) δt=Rt+1+γVt(St+1)−V(St)
假设动作由Gibbs-softmax方法生成,那么有:
π t ( a ∣ s ) = Pr { A t = a ∣ S t = s } = e H t ( s , a ) ∑ b e H t ( s , b ) \pi_{t}(a \mid s)=\operatorname{Pr}\left\{A_{t}=a \mid S_{t}=s\right\}=\frac{e^{H_{t}(s, a)}}{\sum_{b} e^{H_{t}(s, b)}} πt(a∣s)=Pr{At=a∣St=s}=∑beHt(s,b)eHt(s,a)
其中, H t ( s , a ) {H_{t}(s, a)} Ht(s,a)是参与者的可修改策略参数在时间t的值,指示在时间t的每个状态s中选择(偏好)每个动作a的趋势。然后,可以通过增加或减少 H t ( s t , a t ) {H_{t}(s_t, a_t)} Ht(st,at)来实现上述增强或减弱,例如:
H t + 1 ( S t , A t ) = H t ( S t , A t ) + β δ t H_{t+1}\left(S_{t}, A_{t}\right)=H_{t}\left(S_{t}, A_{t}\right)+\beta \delta_{t} Ht+1(St,At)=Ht(St,At)+βδt, 其中β是另一个正步长参数
下面这个图展示的就是,actor-critic算法的基本流程。

DDQN的实验
钟摆以随机位置开始,目标是将其摆动,使其保持向上直立。动作空间是连续的,值的区间为[-2,2]。每个step给的reward最低为-16.27,最高为0。
环境建立如下:
env = gym.make('Pendulum-v0')
env.seed(1) # 设置env随机种子
n_states = env.observation_space.shape[0] # 获取总的状态数
强化学习的基本接口:
rewards = [] # 记录总的rewards
moving_average_rewards = [] # 记录总的经滑动平均处理后的rewards
ep_steps = []
for i_episode in range(1, cfg.max_episodes+1): # cfg.max_episodes为最大训练的episode数
state = env.reset() # reset环境状态
ep_reward = 0
for i_step in range(1, cfg.max_steps+1): # cfg.max_steps为每个episode的补偿
action = agent.select_action(state) # 根据当前环境state选择action
next_state, reward, done, _ = env.step(action) # 更新环境参数
ep_reward += reward
agent.memory.push(state, action, reward, next_state, done) # 将state等这些transition存入memory
state = next_state # 跳转到下一个状态
agent.update() # 每步更新网络
if done:
break
# 更新target network,复制DQN中的所有weights and biases
if i_episode % cfg.target_update == 0: # cfg.target_update为target_net的更新频率
agent.target_net.load_state_dict(agent.policy_net.state_dict())
print('Episode:', i_episode, ' Reward: %i' %
int(ep_reward), 'n_steps:', i_step, 'done: ', done,' Explore: %.2f' % agent.epsilon)
ep_steps.append(i_step)
rewards.append(ep_reward)
# 计算滑动窗口的reward
if i_episode == 1:
moving_average_rewards.append(ep_reward)
else:
moving_average_rewards.append(
0.9*moving_average_rewards[-1]+0.1*ep_reward)
结果展示:

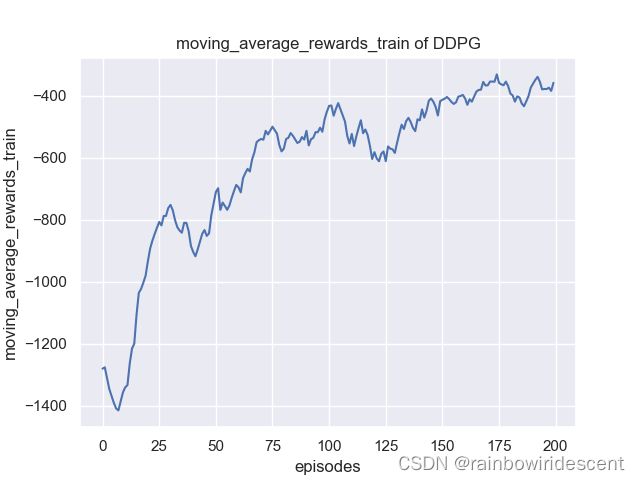
Reference:
【1】https://datawhalechina.github.io/easy-rl/#/
【2】https://zhuanlan.zhihu.com/reinforce
【3】SUTTON R S,BARTO AG.Reinforcement Learning:An introduction (second edition) [M].London: The MIT Press,2018
【4】邱锡鹏.神经网络与深度学习[M].北京:机械工业出版社,2020
【5】王琦等,Easy RL蘑菇书,强化学习教程