Hadoop、Hbase安装教程保姆级教程
Hadoop、Hbase安装教程
-
-
-
- 准备Centos系统
-
- 设置网络
- 安装java环境
-
- 配置SSH免密登录
- 安装hadoop
-
- 修改Hadoop相关命令执行环境
- 修改Hadoop配置
- 运行和测试
- Web界面进行验证
- 测试案例
- 配置zookeeper
- 安装HBASE
-
-
准备Centos系统
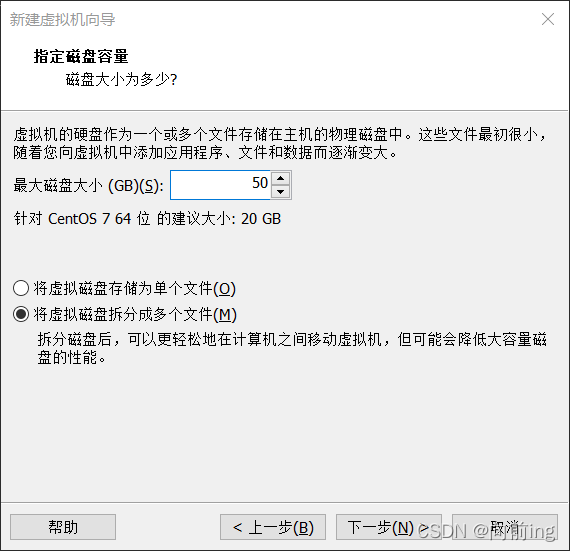
安装虚拟机安装Centos7时
硬盘设置大一些,如40G或更多
不要设置预先分配磁盘空间.
网络适配器设置为NAT连接
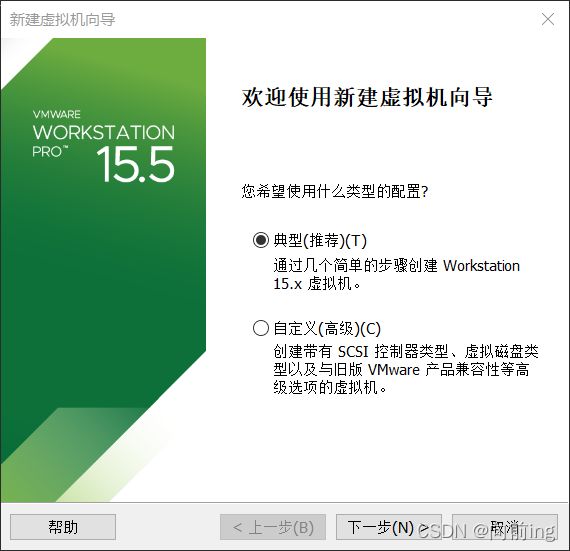
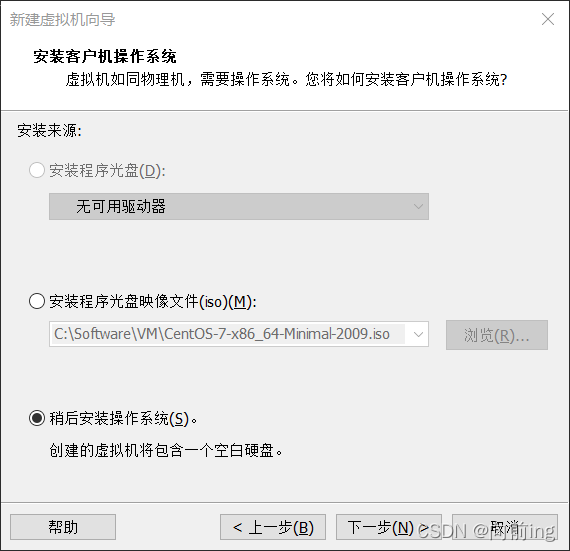




确定后就启动虚拟机,键盘上选择第一条install centos7 后回车



点一下其他图标等全部图标变成黑色后就会自动开始安装。

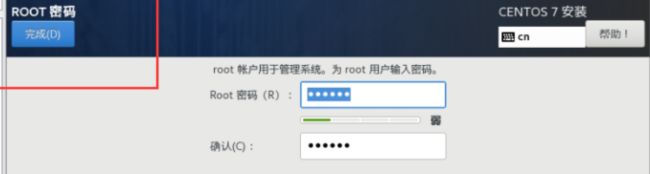

等待虚拟机打开后就输入用户名root和输入刚才设置的密码就可以进入。

创建新的用户:
[root@hadoop100 opt]useradd hadoop
切换到新的用户:
[root@hadoop100 opt]# su hadoop
给新用户权限:
[root@localhost] vi /etc/sudoers
(需要用root权限修改这个文件才可以)
在文件中加上一行:
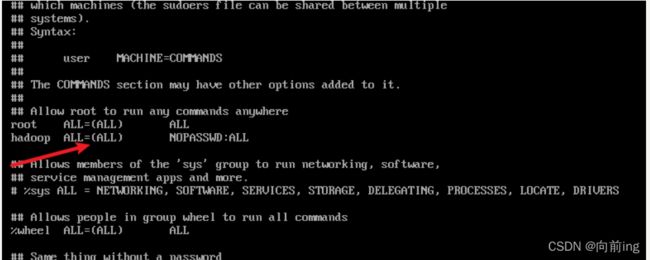
hadoop ALL=(ALL) NOPASSWD:ALL
设置网络
点击虚拟网络编辑器点击NAT设置并且记住NAT模式所在的虚拟网卡对应的子网IP,子网掩码以及网关IP.

进入虚拟机终端,设置静态IP:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
NAME="ens33"
TYPE="Ethernet"
DEVICE="ens33"
BROWSER_ONLY="no"
DEFROUTE="yes"
PROXY_METHOD="none"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
IPV6_PRIVACY="no"
UUID="b00b9ac0-60c2-4d34-ab88-2413055463cf"
ONBOOT="yes"
BOOTPROTO="static"
IPADDR="192.168.186.100"
PREFIX="24"
GATEWAY="192.168.186.2"
DNS1="223.5.5.5"
DNS2="8.8.8.8"
其中需要修改的是:
- ONTBOOT设置yes可以实现自动联网
- BOOTPROTO=“static” 设置静态IP,防止IP发生变化
- IPADDR的前三段要和NAT虚拟网卡的子网IP一致,且第四段在0~254之间选择,又不能和NAT虚拟网卡的子网掩码和其他相同网络中的主机IP重复.
- PREFIX=24是设置子网掩码的位数长度,换算十进制就是255.255.255.0,因此PREFIX=24也可以直接替换成NETMASK=“255.255.255.0”
- DNS1设置的是阿里的公共DNS地址"223.5.5.5",DNS2设置的是谷歌的公共DNS地址"8,8,8,8"
设置好了之后就重启网络后并且查看主机名:
sudo service network restart
sudo service network status
ip a

更改主机名:
hostnamectl --static set-hostname hadoop100
在hosts文件中配置主机名和本机ip之间的映射关系:
vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.186.100 hadoop100
最后重启虚拟机即可实现更改主机名。
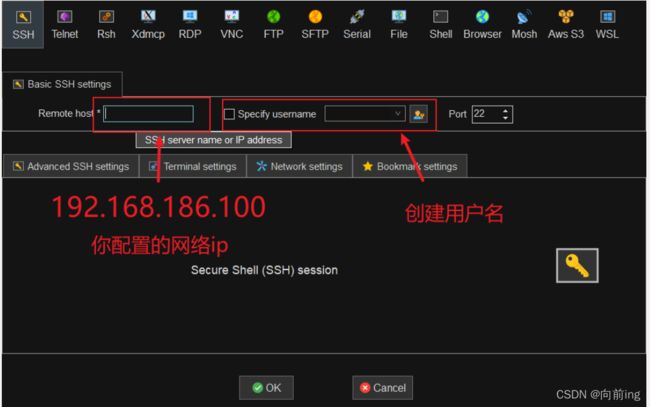
完成网络配置之后就可以用MobaXterm从外部连接虚拟机了。

点击SSH后输入你的主机ip,用户名可以创建也可以不创建:
输入登陆的账号和密码即可登陆:
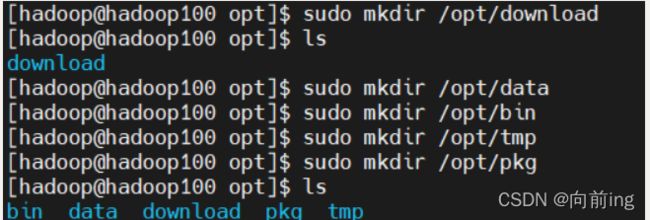
使用hadoop账户创建目录:
[hadoop@hadoop100 opt]$ sudo mkdir /opt/download
[hadoop@hadoop100 opt]$ sudo mkdir /opt/data
[hadoop@hadoop100 opt]$ sudo mkdir /opt/bin
[hadoop@hadoop100 opt]$ sudo mkdir /opt/tmp
[hadoop@hadoop100 opt]$ sudo mkdir /opt/pkg
为了使用方便更改opt下目录的用户及其所在用户组为hadoop:
[hadoop@hadoop100 /]$ sudo chown hadoop:hadoop -R /opt
[hadoop@hadoop100 /]$ ll
[hadoop@hadoop100 /]$ cd opt
[hadoop@hadoop100 opt]$ ls

修改完之后就可以直接将文件拖入MobaXterm左边栏就上传文件了:
链接:https://pan.baidu.com/s/1I6ZoSiSsHh_P77vUwtyhsQ
提取码:1234
安装java环境
[hadoop@hadoop100 download]$ tar -zxvf jdk-8u281-linux-x64.tar.gz
将解压的java包移动到另一个目录下:
[hadoop@hadoop100 download]$ mv jdk1.8.0_281/ /opt/pkg/java
配置环境变量:
编辑/etc/profile.d/hadoop.env.sh配置文件(没有则创建)
[hadoop@hadoop100 ~]$ sudo vi /etc/profile.d/hadoop.env.sh
在上面的文件中添加新的环境变量配置:
# JAVA JDK1.8
export JAVA_HOME=/opt/pkg/java
PATH=$JAVA_HOME/bin:$PATH
export PATH
使新的环境立即生效:
[hadoop@hadoop100 ~]$ source /etc/profile
检查环境是否配置成功:
[hadoop@hadoop100 ~]$ javac
[hadoop@hadoop100 ~]$ java -version
配置SSH免密登录
由于Hadoop集群的机器之间ssh通信默认需要输入密码,在集群运行时我们不可能为每一次通信都手动输入密码,因此需要配置机器之间的ssh的免密登录。单机伪分布式的Hadoop环境样需要配置本地对本地ssh连接的免密,流程如下:
首先ssh-keygen命令生成RSA加密的密钥对(公钥和私钥):
[hadoop@hadoop100 ~]$ ssh-keygen -t rsa(输入完后按三次回车键)
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:XI6S5Nm3XT5K9mAn8QfvDwqXbOPMr4T8zmBBJKEZ5R8 hadoop@hadoop100
The key's randomart image is:
+---[RSA 2048]----+
| ..+.. |
| = o |
| + . E |
| o = * . |
| = S = . o |
| . o * * o |
| B # * o|
| . / O = |
| .@oo +|
+----[SHA256]-----+
将生成的公钥添加到~/.ssh目录下的authorized_keys文件中:
[hadoop@hadoop100 ~]$ cd
[hadoop@hadoop100 ~]$ cd ~/.ssh
[hadoop@hadoop100 .ssh]$ ssh-copy-id hadoop100
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'hadoop100 (192.168.186.100)' can't be established.
ECDSA key fingerprint is SHA256:4//xb3Cx42SKtg9nGAV6XXYc4MSPTusnst1P3HUfjG8.
ECDSA key fingerprint is MD5:ba:e6:34:5b:d6:28:89:d6:4f:9e:db:21:ef:a3:6c:92.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@hadoop100's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop100'"
and check to make sure that only the key(s) you wanted were added.
[hadoop@hadoop100 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
[hadoop@hadoop100 .ssh]$ cat authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDbPSEI2ID5Ip6zeZ0krlbSILXILU5WMH2enazk5hQCPOxB1RpeHjwvuBna89e8muT3NgV34qHfzEXMw8DXJfMNnOeHkvgIFe5P4air+nhWJlMYyCzVhqzm1sO9Bmza91SQeLVvwuHVx0UsiE5iLKNc/FbDPZS5piEd3lY1gSO6zV5IAZj9CzYaIweJDFEKTVIdO8bkra5+tjS8cqSFOIeLysym9XglvqZMQmOnuUaDwaYi/KAjSung2gdPRoorTYChWoWSMtFioD+Ohxgbud9mRY/0bz4B0lmqgeZbU6n5GgAjrdkKL5Of3CxfxazhALbOI3wKqWIUASt/Wa90QXsH hadoop@hadoop100
[hadoop@hadoop100 .ssh]$ cat id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDbPSEI2ID5Ip6zeZ0krlbSILXILU5WMH2enazk5hQCPOxB1RpeHjwvuBna89e8muT3NgV34qHfzEXMw8DXJfMNnOeHkvgIFe5P4air+nhWJlMYyCzVhqzm1sO9Bmza91SQeLVvwuHVx0UsiE5iLKNc/FbDPZS5piEd3lY1gSO6zV5IAZj9CzYaIweJDFEKTVIdO8bkra5+tjS8cqSFOIeLysym9XglvqZMQmOnuUaDwaYi/KAjSung2gdPRoorTYChWoWSMtFioD+Ohxgbud9mRY/0bz4B0lmqgeZbU6n5GgAjrdkKL5Of3CxfxazhALbOI3wKqWIUASt/Wa90QXsH hadoop@hadoop100
[hadoop@hadoop100 .ssh]$ ll
总用量 16
-rw-------. 1 hadoop hadoop 398 2月 28 20:12 authorized_keys
-rw-------. 1 hadoop hadoop 1679 2月 28 20:10 id_rsa
-rw-r--r--. 1 hadoop hadoop 398 2月 28 20:10 id_rsa.pub
-rw-r--r--. 1 hadoop hadoop 187 2月 28 20:12 known_hosts
[hadoop@hadoop100 .ssh]$ ssh hadoop100
Last login: Mon Feb 28 19:51:28 2022 from 192.168.186.1
使用ssh命令连接本地终端,如果不需要输入密码则说明本地的SSH免密配置成功:
[hadoop@hadoop100 .ssh]$ ssh hadoop100
Last login: Mon Feb 28 19:51:28 2022 from 192.168.186.1
此时已经进入另外一个终端了(远程终端)我们要把它退出来回到原来的终端:
[hadoop@hadoop100 ~]$ tty
/dev/pts/1
[hadoop@hadoop100 ~]$ exit
登出
Connection to hadoop100 closed.
[hadoop@hadoop100 .ssh]$ tty
/dev/pts/0
安装hadoop
解压hadoop安装包并移动解压后的文件:
[hadoop@hadoop100 download]$ tar zxvf hadoop-3.1.4.tar.gz
[hadoop@hadoop100 download]$ mv hadoop-3.1.4 /opt/pkg/hadoop
编辑/etc/profile.d/env.sh配置文件,添加环境变量:
# HADOOP_HOME
export HADOOP_HOME=/opt/pkg/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使新的环境变量立刻生效:
[hadoop@hadoop100 download]$ sudo vi /etc/profile.d/hadoop.env.sh
[hadoop@hadoop100 download]$ source /etc/profile
检查是否配置成功环境变量:
[hadoop@hadoop100 download]$ hadoop
修改Hadoop相关命令执行环境
找到Hadoop安装目录下的hadoop/etc/hadoop/hadoop-env.sh文件,找到这一处将JAVA_HOME修改为真实JDK路径即可:
# export JAVA_HOME=
export JAVA_HOME=/opt/pkg/java
找到hadoop/etc/hadoop/yarn-env.sh文件,做同样修改:
export JAVA_HOME=/opt/pkg/java
找到hadoop/etc/hadoop/mapred-env.sh,做同样修改:
export JAVA_HOME=/opt/pkg/java

修改Hadoop配置
来到 hadoop/etc/hadoop/,修改以下配置文件。
(1)hadoop/etc/hadoop/core-site.xml – Hadoop核心配置文件:
[hadoop@hadoop100 hadoop]$ vi core-site.xml
在文件中加入以下内容
<configuration>
<!-- 指定NameNode的地址和端口. -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:8020</value>
</property>
<!-- 指定HDFS系统运行时产生的文件的存储目录. -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/pkg/hadoop/data/tmp</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整;默认值4096 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟;默认值0 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
注意:主机名要修改成本机的实际主机名。
hadoop.tmp.dir十分重要,此目录下保存hadoop集群中namenode和datanode的所有数据。
(2)hadoop/etc/hadoop/hdfs-site.xml – HDFS相关配置:
[hadoop@hadoop100 hadoop]$ vi hdfs-site.xml
在文件中添加下面内容:
<configuration>
<!-- 设置HDFS中的数据副本数. -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 设置Hadoop的Secondary NameNode的主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop100:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop100:9870</value>
</property>
<!-- 是否检查操作HDFS文件系统的用户权限. -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
dfs.replication默认是3,为了节省虚拟机资源,这里设置为1
全分布式情况下,SecondaryNameNode和NameNode 应分开部署
dfs.namenode.secondary.http-address默认就是本地,如果是伪分布式可以不用配置
dfs.permissions权限设置为不检查
(3)hadoop/etc/hadoop/mapred-site.xml – mapreduce 相关配置
[hadoop@hadoop100 hadoop]$ vi mapred-site.xml
在文件中添加以下内容:
<configuration>
<!-- 指定MapReduce程序由Yarn进行调度. -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- Mapreduce的Job历史记录服务器主机端口设置. -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop100:10020</value>
</property>
<!-- Mapreduce的Job历史记录的Webapp端地址. -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop100:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/pkg/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/pkg/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/pkg/hadoop</value>
</property>
</configuration>
mapreduce.jobhistory相关配置是可选配置,用于查看MR任务的历史日志。
这里主机名(hadoop100)千万不要弄错,不然任务执行会失败,且不容易找原因。
需要手动启动MapReduceJobHistory后台服务才能在Yarn的页面打开历史日志。
(4) 配置 yarn-site.xml
[hadoop@hadoop100 hadoop]$ vi yarn-site.xml
在文件中添加以下内容:
<configuration>
<!-- 设置Yarn的ResourceManager节点主机名. -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop100</value>
</property>
<!-- 设置Mapper端将数据发送到Reducer端的方式. -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否开启日志手机功能. -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间(7天). -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 如果vmem、pmem资源不够,会报错,此处将资源监察置为false -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
(5)workers DataNode 节点配置
[hadoop@hadoop100 hadoop]$ vi workers
文件内容修改成如下(主机名),原本是localhost,不改也没关系。
hadoop100

格式化名称节点
[hadoop@hadoop100 hadoop]$ hdfs namenode -format
格式化成功后会出现以下内容:
2022-02-28 20:56:14,269 INFO common.Storage: Storage directory /opt/pkg/hadoop/data/tmp/dfs/name has been successfully formatted.
2022-02-28 20:56:14,342 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/pkg/hadoop/data/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2022-02-28 20:56:14,465 INFO namenode.FSImageFormatProtobuf: Image file /opt/pkg/hadoop/data/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 0 seconds .
2022-02-28 20:56:14,481 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2022-02-28 20:56:14,487 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2022-02-28 20:56:14,487 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop100/192.168.186.100
************************************************************/

运行和测试
启动Hadoop环境,刚启动Hadoop的HDFS系统后会有几秒的安全模式,安全模式期间无法进行任何数据处理,这也是为什么不建议使用start-all.sh脚本一次性启动DFS进程和Yarn进程,而是先启动dfs后过30秒左右再启动Yarn相关进程。
(1)启动所有DFS进程:
[hadoop@hadoop100 hadoop]$ start-dfs.sh
Starting namenodes on [hadoop100]
Starting datanodes
Starting secondary namenodes [hadoop100]
[hadoop@hadoop100 hadoop]$ jps
2545 SecondaryNameNode
2258 NameNode
2363 DataNode
2685 Jps
[hadoop@hadoop100 hadoop]$
(2)启动所有YARN进程:
[hadoop@hadoop100 hadoop]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[hadoop@hadoop100 hadoop]$ jps
2545 SecondaryNameNode
3217 Jps
2258 NameNode
2363 DataNode
2795 ResourceManager
2910 NodeManager
[hadoop@hadoop100 hadoop]$
(3)启动MapReduceJobHistory后台服务 – 用于查看MR执行的历史日志
[hadoop@hadoop100 hadoop]$ mr-jobhistory-daemon.sh start historyserver
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
[hadoop@hadoop100 hadoop]$ jps
2545 SecondaryNameNode
2258 NameNode
2363 DataNode
2795 ResourceManager
3309 JobHistoryServer
3549 Jps
2910 NodeManager
Web界面进行验证
首先在本机进行主机映射,按照路径找到hosts的文件:

加入这一行配置映射:

之后就可以用主机名加上端口号进行访问。
也可以直接用ip地址进行访问web界面 192.168.186.100:9870 192.168.186.100:50070


需要注意的用web访问之前需要先停止防火墙!!
#停止防火墙
[hadoop@hadoop100 ~]$ systemctl stop firewalld.service
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root
Password:
polkit-agent-helper-1: pam_authenticate failed: Authentication failure
==== AUTHENTICATION FAILED ===
Failed to stop firewalld.service: Access denied
See system logs and 'systemctl status firewalld.service' for details.
[hadoop@hadoop100 ~]$ systemctl stop firewalld.service
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
# 查看防火墙状态
[hadoop@hadoop100 ~]$ systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: inactive (dead) since 一 2022-02-28 21:28:26 CST; 15s ago
Docs: man:firewalld(1)
Process: 687 ExecStart=/usr/sbin/firewalld --nofork --nopid $FIREWALLD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 687 (code=exited, status=0/SUCCESS)
# 开机自启“禁用”
[hadoop@hadoop100 conf]$ systemctl stop firewalld.service
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
[hadoop@hadoop100 conf]$ systemctl disable firewalld.service
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-unit-files ===
Authentication is required to manage system service or unit files.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
==== AUTHENTICATING FOR org.freedesktop.systemd1.reload-daemon ===
Authentication is required to reload the systemd state.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
测试案例
使用官方自带的示例程序测试Hadoop集群
启动DFS和YARN进程,找到测试程序的位置:
[hadoop@hadoop100 data]$ cd /opt/pkg/hadoop/share/hadoop/mapreduce/
[hadoop@hadoop100 mapreduce]$ ls
hadoop-mapreduce-client-app-3.1.4.jar hadoop-mapreduce-client-hs-plugins-3.1.4.jar hadoop-mapreduce-client-shuffle-3.1.4.jar lib
hadoop-mapreduce-client-common-3.1.4.jar hadoop-mapreduce-client-jobclient-3.1.4.jar hadoop-mapreduce-client-uploader-3.1.4.jar lib-examples
hadoop-mapreduce-client-core-3.1.4.jar hadoop-mapreduce-client-jobclient-3.1.4-tests.jar hadoop-mapreduce-examples-3.1.4.jar sources
hadoop-mapreduce-client-hs-3.1.4.jar hadoop-mapreduce-client-nativetask-3.1.4.jar jdiff
准备输入文件并上传到HDFS系统
[hadoop@hadoop100 data]$ vi wc.txt
文件内容如下:
hadoop hadoop hadoop
hi hi hi hello hadoop
hello world hadoop
[hadoop@hadoop100 mapreduce]$ hadoop fs -mkdir /wcinput
[hadoop@hadoop100 mapreduce]$ hadoop fs -put /opt/data/wc.txt /wcinput
运行官方示例程序wordcount,并将结果输出到/output/wc之中
[hadoop@hadoop100 mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.1.4.jar wordcount /wcinput /wcoutput
控制台输出:
2022-02-28 22:02:51,968 INFO client.RMProxy: Connecting to ResourceManager at hadoop100/192.168.186.100:8032
2022-02-28 22:02:53,112 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1646054452694_0001
2022-02-28 22:02:53,487 INFO input.FileInputFormat: Total input files to process : 1
2022-02-28 22:02:54,469 INFO mapreduce.JobSubmitter: number of splits:1
2022-02-28 22:02:55,223 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1646054452694_0001
2022-02-28 22:02:55,224 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-02-28 22:02:55,480 INFO conf.Configuration: resource-types.xml not found
2022-02-28 22:02:55,480 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-02-28 22:02:56,061 INFO impl.YarnClientImpl: Submitted application application_1646054452694_0001
2022-02-28 22:02:56,168 INFO mapreduce.Job: The url to track the job: http://hadoop100:8088/proxy/application_1646054452694_0001/
2022-02-28 22:02:56,169 INFO mapreduce.Job: Running job: job_1646054452694_0001
2022-02-28 22:03:09,586 INFO mapreduce.Job: Job job_1646054452694_0001 running in uber mode : false
2022-02-28 22:03:09,588 INFO mapreduce.Job: map 0% reduce 0%
2022-02-28 22:03:17,740 INFO mapreduce.Job: map 100% reduce 0%
2022-02-28 22:03:25,864 INFO mapreduce.Job: map 100% reduce 100%
2022-02-28 22:03:26,884 INFO mapreduce.Job: Job job_1646054452694_0001 completed successfully
2022-02-28 22:03:27,018 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=66
FILE: Number of bytes written=443475
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=164
HDFS: Number of bytes written=40
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=5728
Total time spent by all reduces in occupied slots (ms)=5239
Total time spent by all map tasks (ms)=5728
Total time spent by all reduce tasks (ms)=5239
Total vcore-milliseconds taken by all map tasks=5728
Total vcore-milliseconds taken by all reduce tasks=5239
Total megabyte-milliseconds taken by all map tasks=5865472
Total megabyte-milliseconds taken by all reduce tasks=5364736
Map-Reduce Framework
Map input records=3
Map output records=11
Map output bytes=107
Map output materialized bytes=66
Input split bytes=101
Combine input records=11
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=66
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=206
CPU time spent (ms)=2040
Physical memory (bytes) snapshot=322527232
Virtual memory (bytes) snapshot=5471309824
Total committed heap usage (bytes)=165810176
Peak Map Physical memory (bytes)=210579456
Peak Map Virtual memory (bytes)=2732216320
Peak Reduce Physical memory (bytes)=111947776
Peak Reduce Virtual memory (bytes)=2739093504
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=63
File Output Format Counters
Bytes Written=40
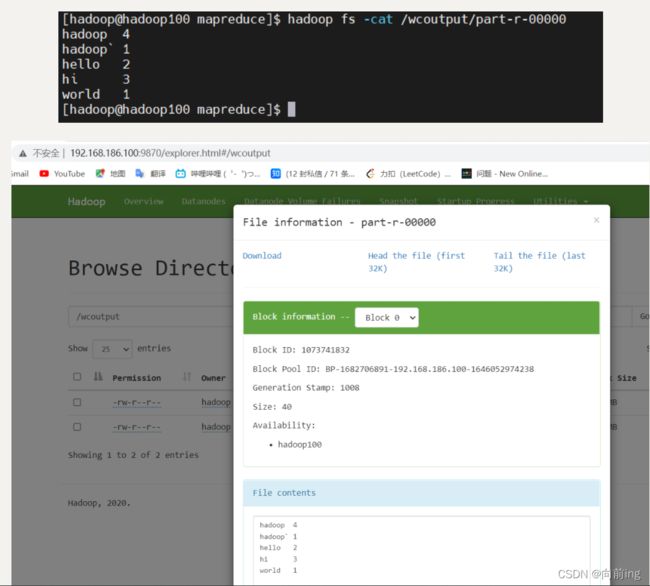
查看结果:
[hadoop@hadoop100 mapreduce]$ hadoop fs -cat /wcoutput/part-r-00000
hadoop 4
hadoop` 1
hello 2
hi 3
world 1
关闭集群:
[hadoop@hadoop100 mapreduce]$ stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as hadoop in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [hadoop100]
Stopping datanodes
Stopping secondary namenodes [hadoop100]
Stopping nodemanagers
Stopping resourcemanager
[hadoop@hadoop100 mapreduce]$ mr-jobhistory-daemon.sh stop historyserver
WARNING: Use of this script to stop the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon stop" instead.
[hadoop@hadoop100 mapreduce]$ jps
4481 Jps
[hadoop@hadoop100 mapreduce]$
搭建到这一步可以进行快照拍摄:

关闭电脑之前必须将虚拟机挂起或者关闭,这样虚拟机才不容易坏。
创建一个启动集群的脚本
[hadoop@hadoop100 bin]$ touch start-cluster.sh
[hadoop@hadoop100 bin]$ chmod u+x start-cluster.sh
[hadoop@hadoop100 bin]$ vi start-cluster.sh
文件内容如下:
start-dfs.sh
sleep 30
start-yarn.sh
sleep 20
mr-jobhistory-daemon.sh start historyserver
执行脚本文件启动集群:
[hadoop@hadoop100 bin]$ ./start-cluster.sh
Starting namenodes on [hadoop100]
Starting datanodes
Starting secondary namenodes [hadoop100]
Starting resourcemanager
Starting nodemanagers
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
[hadoop@hadoop100 bin]$ jps
5795 JobHistoryServer
5013 SecondaryNameNode
5384 NodeManager
4811 DataNode
5259 ResourceManager
5851 Jps
4703 NameNode
配置zookeeper
解压安装包并且移动到其他目录下:
[hadoop@hadoop100 download]$ tar zxvf apache-zookeeper-3.5.9-bin.tar.gz
[hadoop@hadoop100 download]$ mv apache-zookeeper-3.5.9-bin /opt/pkg/zookeeper
修改zookeeper配置文件:
[hadoop@hadoop100 bin]$ cd /opt/pkg/zookeeper/conf/
[hadoop@hadoop100 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[hadoop@hadoop100 conf]$ mv zoo_sample.cfg zoo.cfg
[hadoop@hadoop100 conf]$ vi zoo.cfg
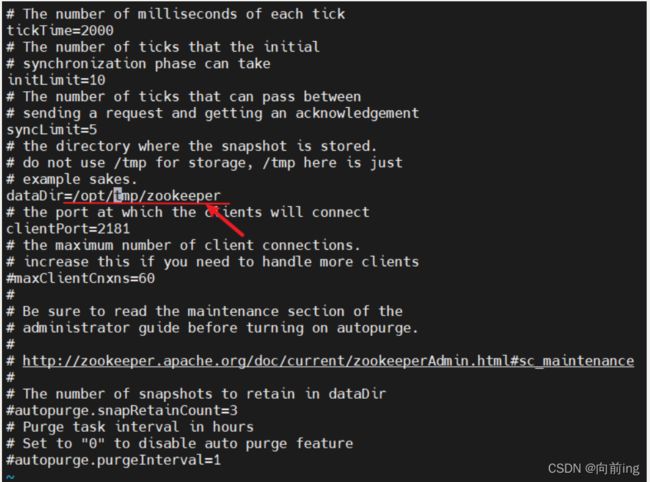
因为是单机因此只需要修改一个位置:
dataDir=/opt/tmp/zookeeper
启动zookeeper:
[hadoop@hadoop100 zookeeper]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop100 zookeeper]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone
上面配置的是单机的zookeeper,但是一般单机zookeeper没用要配置多个zookeeper集群才方便使用,要求zookeeper是奇数,3台5台这样的。因此接下来配置单机上的虚假zookeeper集群:
[hadoop@hadoop100 zookeeper]$ cd conf
[hadoop@hadoop100 conf]$ cp zoo.cfg zoo1.cfg
[hadoop@hadoop100 conf]$ vi zoo1.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/tmp/zk1(zk2|zk3)
# the port at which the clients will connect
clientPort=2181(2|3)
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=hadoop100:2888:3888
server.2=hadoop100:2889:3889
server.3=hadoop100:2890:3890
接下来两个配置文件也是一样的方式修改:
[hadoop@hadoop100 conf]$ cp zoo1.cfg zoo2.cfg
[hadoop@hadoop100 conf]$ cp zoo1.cfg zoo3.cfg
[hadoop@hadoop100 conf]$ vi zoo2.cfg
[hadoop@hadoop100 conf]$ vi zoo3.cfg
配置zookeeper环境:
[hadoop@hadoop100 bin]$ sudo vi /etc/profile.d/hadoop.env.sh
加入以下内容在文件中:
# ZOOKEEPER 3.5.9
export ZOOKEEPER_HOME=/opt/pkg/zookeeper
PATH=$ZOOKEEPER_HOME/bin:$PATH
[hadoop@hadoop100 bin]$ source /etc/profile
标记每个服务器中存放的对应服务器的数据:
[hadoop@hadoop100 bin]$ mkdir /opt/tmp/zk1
[hadoop@hadoop100 bin]$ mkdir /opt/tmp/zk2
[hadoop@hadoop100 bin]$ mkdir /opt/tmp/zk3
[hadoop@hadoop100 bin]$ echo 1 > /opt/tmp/zk1/myid
[hadoop@hadoop100 bin]$ echo 2 > /opt/tmp/zk2/myid
[hadoop@hadoop100 bin]$ echo 3 > /opt/tmp/zk3/myid
启动三个zookeeper集群:
[hadoop@hadoop100 bin]$ zkServer.sh start $ZOOKEEPER_HOME/conf/zoo1.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo1.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop100 bin]$ zkServer.sh start $ZOOKEEPER_HOME/conf/zoo2.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo2.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop100 bin]$ zkServer.sh start $ZOOKEEPER_HOME/conf/zoo3.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo3.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop100 bin]$ zkServer.sh status $ZOOKEEPER_HOME/conf/zoo1.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo1.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[hadoop@hadoop100 bin]$ zkServer.sh status $ZOOKEEPER_HOME/conf/zoo2.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo2.cfg
Client port found: 2182. Client address: localhost. Client SSL: false.
Mode: leader
[hadoop@hadoop100 bin]$ zkServer.sh status $ZOOKEEPER_HOME/conf/zoo3.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo3.cfg
Client port found: 2183. Client address: localhost. Client SSL: false.
Mode: follower
[hadoop@hadoop100 bin]$
继续修改上面创建的运行集群脚本:
[hadoop@hadoop100 bin]$ cd /opt/bin
[hadoop@hadoop100 bin]$ vi start-cluster.sh
文件内容如下:
start-dfs.sh
sleep 30
start-yarn.sh
sleep 20
mr-jobhistory-daemon.sh start historyserver
zkServer.sh start $ZOOKEEPER_HOME/conf/zoo1.cfg
zkServer.sh start $ZOOKEEPER_HOME/conf/zoo2.cfg
zkServer.sh start $ZOOKEEPER_HOME/conf/zoo3.cfg
sleep 6
zkServer.sh status $ZOOKEEPER_HOME/conf/zoo1.cfg
zkServer.sh status $ZOOKEEPER_HOME/conf/zoo2.cfg
zkServer.sh status $ZOOKEEPER_HOME/conf/zoo3.cfg
查看集群进程:
[hadoop@hadoop100 bin]$ jps
2369 NodeManager
2259 ResourceManager
3222 QuorumPeerMain
1816 DataNode
2024 SecondaryNameNode
3272 QuorumPeerMain
3336 QuorumPeerMain
1705 NameNode
2778 JobHistoryServer
3503 Jps
安装HBASE
解压hbase安装包并且移动都固定目录下:
[hadoop@hadoop100 bin]$ cd /opt/download/
[hadoop@hadoop100 download]$ tar zxvf hbase-2.2.3-bin.tar.gz
[hadoop@hadoop100 download]$ mv hbase-2.2.3 /opt/pkg/hbase
添加到环境变量:
[hadoop@hadoop100 download]$ sudo vi /etc/profile.d/hadoop.env.sh
[hadoop@hadoop100 download]$ source /etc/profile
添加以下内容在文件中:
# HBASE 2.3.3
export HBASE_HOME=/opt/pkg/hbase
PATH=$HBASE_HOME/bin:$PATH
查看hbase版本:
[hadoop@hadoop100 download]$ hbase version
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/pkg/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/pkg/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase 2.2.3
Source code repository git://hao-OptiPlex-7050/home/hao/open_source/hbase revision=6a830d87542b766bd3dc4cfdee28655f62de3974
Compiled by hao on 2020年 01月 10日 星期五 18:27:51 CST
From source with checksum 097925184b85f6995e20da5462b10f3f
需要解决一下出现hadoop和hbase的jar包冲突,删除冲突的jar包:
[hadoop@hadoop100 ~]$ cd /opt/download/
[hadoop@hadoop100 download]$ cd $HBASE_HOME
[hadoop@hadoop100 hbase]$ cd lib/client-facing-thirdparty/
[hadoop@hadoop100 client-facing-thirdparty]$ rm slf4j-log4j12-1.7.25.jar
再次查看hbase版本就不会出现冲突了:
[hadoop@hadoop100 client-facing-thirdparty]$ hbase version
HBase 2.2.3
Source code repository git://hao-OptiPlex-7050/home/hao/open_source/hbase revision=6a830d87542b766bd3dc4cfdee28655f62de3974
Compiled by hao on 2020年 01月 10日 星期五 18:27:51 CST
From source with checksum 097925184b85f6995e20da5462b10f3f
修改hbase-env.sh文件
[hadoop@hadoop100 conf]$ cd ../conf/
[hadoop@hadoop100 conf]$ ls
hadoop-metrics2-hbase.properties hbase-env.cmd hbase-env.sh hbase-policy.xml hbase-site.xml log4j-hbtop.properties log4j.properties regionservers
[hadoop@hadoop100 conf]$ vi hbase-env.sh
在文件中加入下面一句话:
export JAVA_HOME=/opt/pkg/java
export HBASE_MANAGES_ZK=false (不使用hbase自带的zookeeper集群)

修改hbase-site.xml文件:
[hadoop@hadoop100 conf]$ vi hbase-site.xml
文件内容为:
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop100:8020/hbase</value>
</property>
<!-- 指定hbase是否分布式运行 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zookeeper的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop100:2181,hadoop100:2182,hadoop100:2183</value>
</property>
<!--指定hbase管理页面-->
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<!-- 在分布式的情况下一定要设置,不然容易出现Hmaster起不来的情况 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
修改regionservers配置文件,指定HBase的从节点主机名:
[hadoop@hadoop100 conf]$ vi regionservers
文件内容为:hadoop100
启动HBase前需要提前启动HDFS及ZooKeeper集群:
如果没开启hdfs,请在运行命令:start-dfs.sh
如果没开启zookeeper,请运行命令: zkServer.sh start conf/zoo.cfg
检查是否成功开启前提条件:
[hadoop@hadoop100 conf]$ jps
2369 NodeManager
2259 ResourceManager
3222 QuorumPeerMain
1816 DataNode
2024 SecondaryNameNode
3272 QuorumPeerMain
3336 QuorumPeerMain
1705 NameNode
2778 JobHistoryServer
3886 Jps
执行以下命令启动HBase集群:
[hadoop@hadoop100 conf]$ start-hbase.sh
running master, logging to /opt/pkg/hbase/logs/hbase-hadoop-master-hadoop100.out
hadoop100: running regionserver, logging to /opt/pkg/hbase/logs/hbase-hadoop-regionserver-hadoop100.out
[hadoop@hadoop100 conf]$ jps
2369 NodeManager
4050 HMaster
2259 ResourceManager
4372 Jps
3222 QuorumPeerMain
1816 DataNode
2024 SecondaryNameNode
3272 QuorumPeerMain
3336 QuorumPeerMain
1705 NameNode
2778 JobHistoryServer
4204 HRegionServer
查看web界面:192.168.186.100:16010

进入hbase:
[hadoop@hadoop100 conf]$ hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.3, r6a830d87542b766bd3dc4cfdee28655f62de3974, 2020年 01月 10日 星期五 18:27:51 CST
Took 0.0182 seconds
hbase(main):001:0> status
1 active master, 0 backup masters, 1 servers, 0 dead, 2.0000 average load
Took 1.1952 seconds
测试创建一个表:
hbase(main):002:0> list
TABLE
0 row(s)
Took 0.0477 seconds
=> []
hbase(main):003:0> create 'test','cf'
Created table test
Took 2.4675 seconds
=> Hbase::Table - test
hbase(main):004:0> put 'test','rowid001','cf:c1','1010'
Took 0.4597 seconds
hbase(main):005:0> scan 'test'
ROW COLUMN+CELL
rowid001 column=cf:c1, timestamp=1646071482951, value=1010
1 row(s)
Took 0.0829 seconds
hbase(main):006:0> exit
[hadoop@hadoop100 conf]$
