跟李沐学AI part2
reference:
https://www.bilibili.com/video/BV1K64y1Q7wu/?spm_id_from=333.788.recommend_more_video.0
https://zh-v2.d2l.ai/
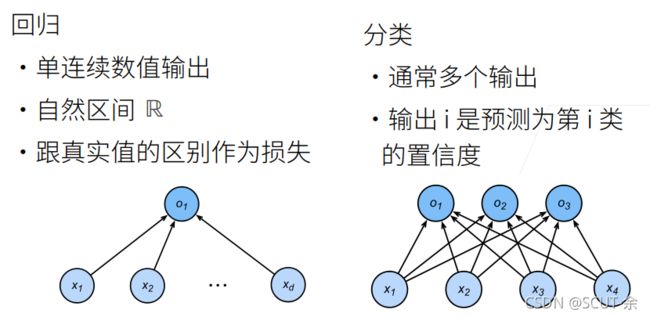
1.分类和回归
回归:最后得到的是经过预测函数所得到的一个预测结果
分类:最后得到的是数量为要分类的总物体品种的数量的置信度。比如计划是分十个类别,那么经过预测函数(网络)后最后得到的是是个置信度,比如mnist分类,对应的类别有【0,1,2,3,4,5,6,7,8,9】,通过预测函数后最后的输出结果是【0.2,0.13,0.25,0.72,0.40,0.23,0.12,0.08,0.48,0.19】,作者写的更明白些,【‘0’:0.2,‘1’:0.13,‘2’:0.25,‘3’:0.72,‘4’:0.40,‘5’:0.23,‘6’:0.12,‘7’:0.08,'8’0.48,‘9’:0.19】,可见最大的置信度为3对应的0.72,那么这个的预测就是3
1.1
但是实际上可以认为分类是回归的一种应用的拓展,目前的方法是
1.构建预测函数,记结果为o1,o2…
2.将这些oi丢入softmax函数当中,结果为 y_hat
3.对 y_hat做个归一化,来保证总和是1
4.y_hat中的最大值对应的字符就是预测结果
5.至于loss_function,这边选用的是更加偏向概率角度(我感觉,非李沐原话)的交叉熵,这让我想起来我那篇手写逻辑分类器的改良



1.2 softmax 手写版
注:原代码多有bug和新知识点,并且都大量的新东西
https://blog.csdn.net/m0_46861439/article/details/120578616
有疑惑可以参考上面那个
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from torchvision.datasets import FashionMNIST as FM
from d2l import torch as d2l
from IPython import display
import matplotlib.pyplot as plt
def get_fashion_mnist_labels(labels):
text_labels=['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[i] for i in labels]
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
fig_size=(num_cols*scale, num_rows*scale)
fig,axes=d2l.plt.subplots(num_rows,num_cols,figsize=fig_size)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
plt.show()
return axes
def load_data_FM(batch_size,resize=None):
'''正式的提供数据集'''
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans=transforms.Compose(trans)
mnist_train = FM(root='D:\datasets_for_pytorch', train=True,
transform=trans, download=False)
mnist_test = FM(root='D:\datasets_for_pytorch', train=False,
transform=trans, download=False)
return (data.DataLoader(mnist_train,batch_size,shuffle=True,num_workers=0),
data.DataLoader(mnist_test, batch_size, shuffle=True, num_workers=0)
)
batch_size=256
train_iter,test_iter=load_data_FM(batch_size)
num_inputs=784
num_outputs=10
#x=1*784,784=28*28, w=784*10,y_hat=1*10--> x*w=1*784*784*10=1*10
w=torch.normal(0,0.01,size=(num_inputs,num_outputs),requires_grad=True)
b=torch.zeros((1,num_outputs),requires_grad=True)
def softmax(x):
x_exp=torch.exp(x)
total_x=x_exp.sum(1,keepdim=True)
result=x_exp/total_x
return result
def net(x):
#原文是使用X.reshape((-1, W.shape[0]),但按照我的理解用flatten应该也行
x=x.reshape((-1, w.shape[0]))
y=torch.matmul(x,w)+b
result=softmax(y)
return result
def cross_entropy(y_hat,y):
#原文是y_hat[range(len(y_hat)), y]
result_i=-torch.log(y_hat)
result=result_i.sum(1,keepdim=True)
return result
#y_hat=n*10
#y=n*1
def accuracy(y_hat,y):
y_hat=y_hat.argmax(axis=1)
y_hat=y_hat.type(y.dtype)
cmp=(y_hat==y)
#cmp=n*1,dtype=bool,这里的dtype要被处理
result=float(cmp.type(y.dtype).sum())
return result
class Accumulator: #@save
"""在`n`个变量上累加。"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def evaluate_accuracy(net,data_iter):
if isinstance(net,torch.nn.Module):
net.eval()
#可以认为是创建了一个1*2的数组,然后下面的操作都是对应位置上的操作
metric=Accumulator(2)
for x,y in data_iter:
metric.add(accuracy(net(x),y),y.numel())
return metric[0]/metric[1]
class Animator: #@save
"""在动画中绘制数据。"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
"""使用svg格式在Jupyter中显示绘图。"""
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
plt.plot(x,y,c='dodgerblue',label=r'$w1$')
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
plt.show()
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)。"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.backward()
updater.step()
metric.add(float(l) * len(y), accuracy(y_hat, y),
y.size().numel())
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练准确率
return metric[0] / metric[2], metric[1] / metric[2]
def train(net,train_iter,test_iter,num_epochs,loss,updater):
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.01, 0.99],legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
d2l.plt.show()
return 0
lr = 0.1
def updater(batch_size):
return d2l.sgd([w, b], lr, batch_size)
num_epochs = 10
train(net, train_iter, test_iter, num_epochs,cross_entropy, updater)
1.2.2 softmax API版
import torch
from torch import nn
from d2l import torch as d2l
from torchvision import transforms
from torchvision.datasets import FashionMNIST as FM
from torch.utils import data
batch_size=128
def load_data_FM(batch_size,resize=None,Num_Workers=0):
'''正式的提供数据集'''
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans=transforms.Compose(trans)
mnist_train = FM(root='D:\datasets_for_pytorch', train=True,
transform=trans, download=False)
mnist_test = FM(root='D:\datasets_for_pytorch', train=False,
transform=trans, download=False)
return (data.DataLoader(mnist_train,batch_size,shuffle=True,num_workers=Num_Workers,pin_memory=True),
data.DataLoader(mnist_test, batch_size, shuffle=True, num_workers=Num_Workers,pin_memory=True)
)
train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
#这里表示这两层级联
net=nn.Sequential(nn.Flatten(),nn.Linear(784,10))
net.apply(init_weights)
loss=nn.CrossEntropyLoss()
trainer=torch.optim.SGD(net.parameters(),lr=0.01)
num_epoch=10
if __name__=='__main__':
d2l.train_ch3(net, train_iter, test_iter, loss, num_epoch, trainer)
print('ok')
2.多层感知机(MLP)

选用上面那张图作为例子来说一下个人的理解,按照李沐的说法,单层感知机的一大缺点是不能做到’拐弯‘分类,就是它做区分只能是一个直线,比如上图里面的样子,所以考虑了多层感知机器,将特征聚合到上一层的感知机里头,做到更好的分类结果。
比如: 蓝色: y1=sgn(x)+0y
黄色 : y2=sgn(y)+0x
灰色: y3=y1+y2
复杂点的情况就是下面这张图的样子

之所以要整一个激活函数(非线性),是为了达到’拐弯‘的效果,比如打个圈圈
2.1 激活函数
2.1.1 sigmoid
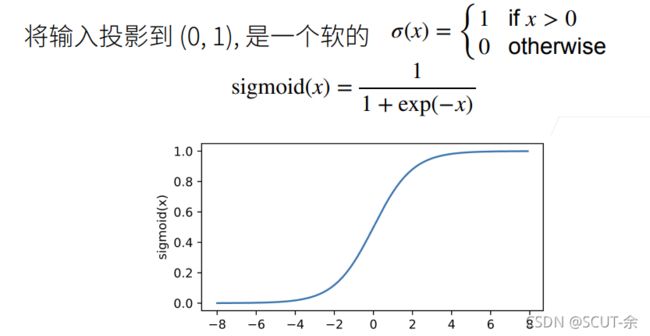
y = torch.sigmoid(x)
2.1.2 ReLu
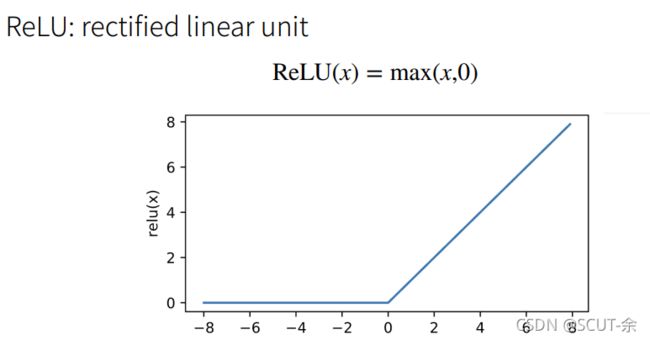
按照李沐的说法,其实relu是最好的,因为其他的(这里指本文提到的其他激活函数)都涉及到指数运算,对算量小号较高
y = torch.relu(x)
2.1.3 tanh
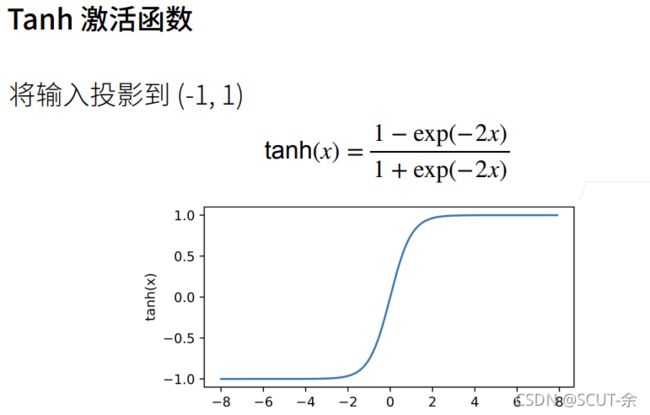
y = torch.tanh(x)
2.2 构造映像
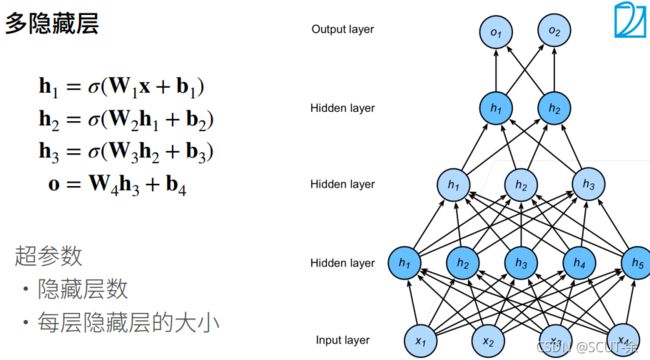
每一个激活函数都能是的分类达到更好的’拐弯‘效果
先 Linear, 再来个激活函数,再Linear,再激活函数
2.3 实践
import torch
from torch import nn
from d2l import torch as d2l
#级联
net=nn.Sequential(
nn.Flatten(),
nn.Linear(784,256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,10)
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size=256
lr=0.01
num_epochs=10
loss=nn.CrossEntropyLoss()
trainer=torch.optim.SGD(net.parameters(),lr=lr)
train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size)
if __name__=='__main__':
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)