【pytorch图像分类】AlexNet网络结构
目录
1、前言
2、网络创新
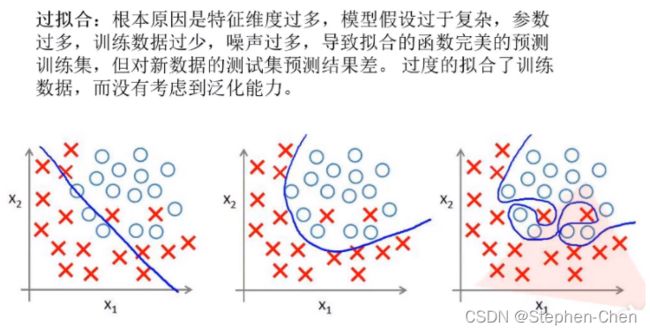
过拟合:
LRN:Local Response Normalization
归一化
3、网络结构图:
4.代码实现
5.总结
1、前言
AlexNet 是 2012 年 ISLVRC2012 (Image Large Scale Visual Recognition Challenge) 竞赛的冠军网络,原始论文为ImageNet Classification with Deep Convolutional Neural Networks。
当时传统算法已经达到性能瓶颈,然而 AlexNet 将分类准确率由传统的 70%+ 提升到 80%+。它是由 Hinton 和他的学生 Alex Krizhevsky 设计的。也就是在那年之后,每年的 ImageNet LSVRC 挑战赛都被深度学习模型霸占着榜首,深度学习开始迅速发展。
注:ISLVRC2012 包括以下三部分:
- 训练集:1281167 张已标注图片
- 验证集:50000 张已标注图片
- 测试集:100000 张未标注图片
2、网络创新
首次利用GPU进行网络加速训练,两块GPU并行运算
使用ReLU激活函数,而不是sigmoid或者Tanh,
LRN对局部的特征进行归一化,结果作为ReLU激活函数的输入能有效降低错误率
全连接层的前连层使用了Dropout随机失活神经元操作,防止过拟合
过拟合:

LRN:Local Response Normalization
是AlexNet中首次引入的归一化方法,但是在BatchNorm之后就很少使用这种方法了,这里对其概念进行简单理解


归一化
(1)为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。
(2)为了程序运行时收敛加快。 下面图解。
(3)同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
(4)避免神经元饱和。啥意思?就是当神经元的激活在接近0或者1时会饱和,在这些区域,梯度几乎为0,这 样,在反向传播过程中,局部梯度就会接近0,这会有效地“杀死”梯度。
(5)保证输出数据中数值小的不被吞食。
3、网络结构图:
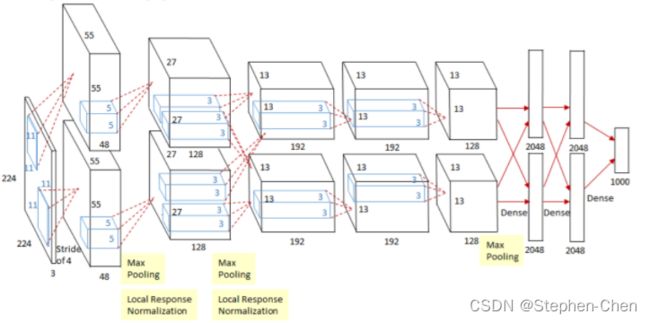
Conv1:
input_Size : [224,224,3]
kernels:48*2=96
Kernel_size:11
stride:4
padding :[1,2] (上下1列0,左右2列0)推理出来的 出现的原因是下面的公式计算出来有小数
output_size:[55,55,96]
Maxpool1:
只改变特征层的高度和宽度,深度不会改变
input_Size : [55,55,96] Kernel_size:3 padding =0 stride = 2 output_size: [27,27,96]
Conv2:
input_Size : [27,27,96] kernels:128*2=256 Kernel_size:5 padding = [2,2] stride = 1 output_size: [27,27,256]
Conv3:
input_Size : [13,13,256] kernels:128*2=192*2 Kernel_size:3 padding = [1,1] stride = 1 output_size: [13,13,384]
Conv4:
input_Size : [13,13,384] kernels:128*2=192*2 Kernel_size:3 padding = [1,1] stride = 1 output_size: [13,13,384]
Conv5:
input_Size : [13,13,384] kernels:128*2=128*2 =256 #输出通道 Kernel_size:3 padding = [1,1] stride = 1 output_size: [13,13,256]
Maxpool3 :
input_Size : [13,13,256] kernels:128*2=256 Kernel_size:3 padding = 0 stride = 2 output_size: [6,6,256]
4.代码实现
import torch
from torch import nn
from torch.nn import Flatten
class AlexNet(nn.Module):
def __init__(self,num_class=1000,init_weight=False):
super(AlexNet,self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=48,kernel_size=11,stride=4,padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2) ,
nn.Conv2d(in_channels=48,out_channels=128,kernel_size=5,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(in_channels=128,out_channels=192,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=192,out_channels=192,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=192,out_channels=128,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128*6*6 , 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048,2048),
nn.ReLU(inplace=True),
nn.Linear(2048,num_class),
)
if init_weight:
self._initialize_weights()
def forward(self,x):
x = self.features(x)
# self.flatten = nn.Flatten(start_dim=1,end_dim=-1) #0维是batch_size,所以不用拉平,即从第二维拉平
# x = self.flatten(x)
# print(x.size())
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
5.总结
AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集。
今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
尽管AlexNet的代码只比LeNet多出几行,但学术界花了很多年才接受深度学习这一概念,并应用其出色的实验结果。这也是由于缺乏有效的计算工具。
Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤。