【YOLO】基于Pytorch实现视频中的各种类型的车流量检测(利用GPU加速)
文章目录
- 车流量检测
-
- 导言
-
- 环境要求
-
- Anaconda
- CUDA
- cudnn
- YOLO
- Pytorch
- Pycharm
- 步骤
-
- 1.训练模型得到权重文件
-
- 数据集
- 2.视频处理
- 3.目标跟踪方法
- 4.虚拟线圈算法
- 流程图
- 核心代码
- 结果展示
车流量检测
导言
环境要求
Anaconda
安装见:https://blog.csdn.net/qq_43529415/article/details/100847887
CUDA
cudnn
CUDA 和cudnn的安装见:https://blog.csdn.net/qq_44824148/article/details/120875736
YOLO
Pytorch
Pycharm
步骤
1.训练模型得到权重文件
数据集
BITVehicle_Dataset
链接:https://pan.baidu.com/s/1TiY-T9NKFrgSiDqLIkvMbw
提取码:h09m
2.视频处理
使用yoloV3模型进行目标检测
3.目标跟踪方法
使用sort算法,其中使用卡尔曼滤波器对目标位置进行估计,利用匈牙利算法进行目标关联。
4.虚拟线圈算法
利用虚拟线圈的思想实现车辆目标的计数,完成车流量的统计。
流程图
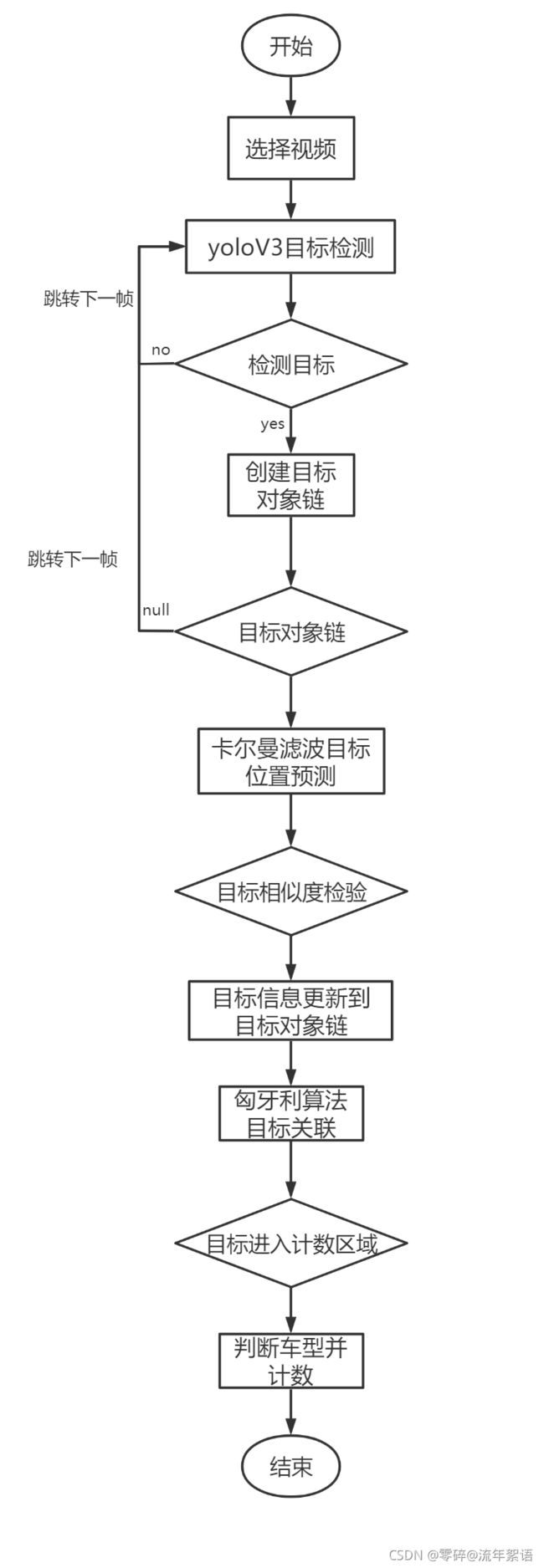
核心代码
进行目标对象的选框,以及目标对象中心坐标的存取
def cls_draw_bbox(self, output, orig_img):
"""
1. predict vehicle's attributes based on bbox of vehicle
2. draw bbox to orig_img
"""
print("3.2")
labels = []
pt_1s = []
pt_2s = []
types=[]
directions=[]
centers = [] #当前帧的检测框中心点
center_ys=[]
classID = [] #当前帧的种类ID
# 1
for det in output:
# rectangle points
pt_1 = tuple(det[1:3].int()) # the left-up point
pt_2 = tuple(det[3:5].int()) # the right down point
# print("p1", pt_1)
# print(type(pt_1))
# print("p2", pt_2)
p1_1 = pt_1[0].item()
p1_2 = pt_1[1].item()
p2_1 = pt_2[0].item()
p2_2 = pt_2[1].item()
(center_x,center_y)=(int((p1_1+p2_1)/2),int((p1_2+p2_2)/2))
centers.append((center_x,center_y))
# classID.append()
print(centers)
pt_1s.append(pt_1)
pt_2s.append(pt_2)
# print("det:", det)
# turn BGR back to RGB
# print(type(orig_img[pt_1[1]: pt_2[1], pt_1[0]: pt_2[0]][:, :, ::-1]))
# print(orig_img[pt_1[1]: pt_2[1],pt_1[0]: pt_2[0]][:, :, ::-1])
orig_list = orig_img[pt_1[1]: pt_2[1], pt_1[0]: pt_2[0]][:, :, ::-1]
if (orig_list.size == 0):
return 1
ROI = Image.fromarray(orig_img[pt_1[1]: pt_2[1], pt_1[0]: pt_2[0]][:, :, ::-1])
# print("ROI:",ROI)
# ROI.show()
# call classifier to predict
car_color, car_direction, car_type = self.classifier.predict(ROI)
label = str(car_color + ' ' + car_direction + ' ' + car_type)
labels.append(label)
types.append(car_type)
center_ys.append(center_y)
directions.append(car_direction)
print('=> predicted label: ', label)
print("center_ys:",center_ys)
# print("directions:",directions)
# print("types:",types)
# print("labels:",labels)
# print("centers:",centers)
# 2
color = (0, 215, 255)
for i, det in enumerate(output ):
pt_1 = pt_1s[i]
pt_2 = pt_2s[i]
# draw bounding box
cv2.rectangle(orig_img, pt_1, pt_2, color, thickness=2)
print("pt_1:", pt_1)
print("pt_2:", pt_2)
# get str text size
txt_size = cv2.getTextSize(
label, cv2.FONT_HERSHEY_PLAIN, 2, 2)[0]
# pt_2 = pt_1[0] + txt_size[0] + 3, pt_1[1] + txt_size[1] + 5
pt_2 = pt_1[0] + txt_size[0] + 3, pt_1[1] - txt_size[1] - 5
# draw text background rect
cv2.rectangle(orig_img, pt_1, pt_2, color, thickness=-1) # text
# draw text
cv2.putText(orig_img, labels[i], (pt_1[0], pt_1[1]), # pt_1[1] + txt_size[1] + 4
cv2.FONT_HERSHEY_PLAIN, 2, [225, 255, 255], 2)
# center_ys=list(center_ys)
# directions=list(directions)
# types=list(types)
# print("type",type(center_ys))
# print("type", type(directions))
# print("type", type(types))
if isinstance(center_ys, list) and isinstance(directions,list) and isinstance(types,list):
return center_ys,directions,types
else:
center_ys.append(1000)
directions.append('front')
types.append('sss')
return center_ys, directions, types
当前帧目标的跟踪框集合
def update(self, dets):
self.frame_count += 1
# 在当前帧逐个预测轨迹位置,记录状态异常的跟踪器索引
# 根据当前所有的卡尔曼跟踪器个数(即上一帧中跟踪的目标个数)创建二维数组:行号为卡尔曼滤波器的标识索引,列向量为跟踪框的位置和ID
trks = np.zeros((len(self.trackers), 5)) # 存储跟踪器的预测
to_del = [] # 存储要删除的目标框
ret = [] # 存储要返回的追踪目标框
# 循环遍历卡尔曼跟踪器列表
for t, trk in enumerate(trks):
# 使用卡尔曼跟踪器t产生对应目标的跟踪框
pos = self.trackers[t].predict()[0]
# 遍历完成后,trk中存储了上一帧中跟踪的目标的预测跟踪框
trk[:] = [pos[0], pos[1], pos[2], pos[3], 0]
# 如果跟踪框中包含空值则将该跟踪框添加到要删除的列表中
if np.any(np.isnan(pos)):
to_del.append(t)
# numpy.ma.masked_invalid 屏蔽出现无效值的数组(NaN 或 inf)
# numpy.ma.compress_rows 压缩包含掩码值的2-D 数组的整行,将包含掩码值的整行去除
# trks中存储了上一帧中跟踪的目标并且在当前帧中的预测跟踪框
trks = np.ma.compress_rows(np.ma.masked_invalid(trks))
# 逆向删除异常的跟踪器,防止破坏索引
for t in reversed(to_del):
self.trackers.pop(t)
# 将目标检测框与卡尔曼滤波器预测的跟踪框关联获取跟踪成功的目标,新增的目标,离开画面的目标
matched, unmatched_dets, unmatched_trks = associate_detections_to_trackers(dets, trks)
# 将跟踪成功的目标框更新到对应的卡尔曼滤波器
for t, trk in enumerate(self.trackers):
if t not in unmatched_trks:
d = matched[np.where(matched[:, 1] == t)[0], 0]
# 使用观测的边界框更新状态向量
trk.update(dets[d, :][0])
# 为新增的目标创建新的卡尔曼滤波器对象进行跟踪
for i in unmatched_dets:
trk = KalmanBoxTracker(dets[i, :])
self.trackers.append(trk)
# 自后向前遍历,仅返回在当前帧出现且命中周期大于self.min_hits(除非跟踪刚开始)的跟踪结果;如果未命中时间大于self.max_age则删除跟踪器。
# hit_streak忽略目标初始的若干帧
i = len(self.trackers)
for trk in reversed(self.trackers):
# 返回当前边界框的估计值
d = trk.get_state()[0]
# 跟踪成功目标的box与id放入ret列表中
if (trk.time_since_update < 1) and (trk.hit_streak >= self.min_hits or self.frame_count <= self.min_hits):
ret.append(np.concatenate((d, [trk.id + 1])).reshape(1, -1)) # +1 as MOT benchmark requires positive
i -= 1
# 跟踪失败或离开画面的目标从卡尔曼跟踪器中删除
if trk.time_since_update > self.max_age:
self.trackers.pop(i)
# 返回当前画面中所有目标的box与id,以二维矩阵形式返回
if len(ret) > 0:
print("321a:", np.concatenate(ret))
return np.concatenate(ret)
print("123a:", np.empty((0, 5)))
return np.empty((0, 5))
结果展示