pytorch官方demo
model.py:
class LeNet(nn.Module):
def __init__(self):#初始化
super(LeNet, self).__init__()#多继承问题super 函数调用父类
module.py:
def __init__(self) -> None:
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters: Dict[str, Optional[Parameter]] = OrderedDict()
self._buffers: Dict[str, Optional[Tensor]] = OrderedDict()
self._non_persistent_buffers_set: Set[str] = set()
self._backward_hooks: Dict[int, Callable] = OrderedDict()
self._is_full_backward_hook = None
self._forward_hooks: Dict[int, Callable] = OrderedDict()
self._forward_pre_hooks: Dict[int, Callable] = OrderedDict()
self._state_dict_hooks: Dict[int, Callable] = OrderedDict()
self._load_state_dict_pre_hooks: Dict[int, Callable] = OrderedDict()
self._load_state_dict_post_hooks: Dict[int, Callable] = OrderedDict()
self._modules: Dict[str, Optional['Module']] = OrderedDict()网络设置:
def __init__(self):#初始化
super(LeNet, self).__init__()#多继承问题
self.conv1 = nn.Conv2d(3, 16, 5)#定义卷积层1
self.pool1 = nn.MaxPool2d(2, 2)#池化层1
self.conv2 = nn.Conv2d(16, 32, 5)#卷积层2
self.pool2 = nn.MaxPool2d(2, 2)#池化层2
self.fc1 = nn.Linear(32*5*5, 120)#全连接1
self.fc2 = nn.Linear(120, 84)#全连接2
self.fc3 = nn.Linear(84, 10)#输出层 10为类别图片分辨率为 32x32
1.卷积层1:
nn.Conv2d(3,16,5) —— Conv2d(in_channels,out_channels,kernel_size...) —— Conv2d(通道RGB三个,16个卷积核,卷积核规模5x5)
输出矩阵尺寸计算:
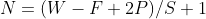
W:图片大小 F:卷积核规模 P:像素 S:步长
计算 N=(32-5+0)/1+1=28 输出矩阵大小 28x28
output=[16,28,28]
2.池化层1:
nn.MaxPool2d(2,2):池化核 2x2,步距 2
output=[16,14,14]
池化层影响图片高、宽,不影响深度
3.卷积层2:
nn.Conv2d(16,32,5): 第二个卷积层采用32个卷积核
N=(14-5+0)/1+1=10
output=(32,10,10)
4.池化层2:
nn.MaxPool2d(2,2)
output=[32,5,5]
图片宽高减半
5.全连接层1
self.fc1 = nn.Linear(32*5*5, 120)#全连接132x5x5为输入,120为全连接层节点个数
6.全连接层2
nn.Linear(120,84) :第二层全连接采用84个节点
7.输出层
nn.Linear(84,10):输出10位one-hot编码,代表类别
前向传播:
def forward(self, x):#正向传播
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return xx=[batch,channel,height,width] tensor通道排列顺序
x = x.view(-1, 32*5*5) 将数据展开成一维向量,‘-1’维度自适应,32x5x5为展平后节点个数
train.py
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#三个通道均值标准差对图像的预处理,transforms.ToTensor将PIL或numpy图像(Height*Weight*Channel)范围(0,255)转化为tensor数据类型(Channel*Height*Weight)范围(0,1)
transforms.Normalize将图像三通道标准化,(原值-均值)/标准差=输出
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)root为下载后数据集目录,将train改为true下载训练集,下载时将download改为true
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)将训练集分批次训练,batch_size=36,每一批随机训练36张图片,shuffle定义是否打乱随机选取,num_workers windows下为0。
def imshow(img):
img=img/2+0.5 #反标准化
nping=img.numpy()
plt.imshow(np.transpose(nping,(1,2,0))) #(0,1,2) cxhxw(tensor)转换成hxwxc(plt和numpy数据格式)
plt.show()
#print labels
print(' '.join('%5s'% classes[val_label[j]] for j in range(4)))
#show images
imshow(torchvision.utils.make_grid(val_image)) #val_image为tensor数据类型将图片进行反标准化,反预处理显示
transpose用法:二维 transpose(1,0)交换x,y轴
三维 transpose(1,2,0) 交换x,y和y,z
join:' '.join 以空格形式连接字符串
训练过程
for epoch in range(5):训练集迭代五次
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):初始化损失值,遍历训练集,返回步长index和数据data(图像和标签)
optimizer.zero_grad()清零历史损失梯度:每计算一个batch_size就要调用一次,batch_size设置越大,训练效果越好,但受硬件限制,内存不足,只能通过一次计算多个小batch_size损失梯度,得到一个大batch_size的梯度,如不清零,会对计算的历史梯度进行累加。
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0with上下文管理器,“在使用pytorch时,并不是所有的操作都需要进行计算图的生成(计算过程的构建,以便梯度反向传播等操作)。而对于tensor的计算操作,默认是要进行计算图的构建的,在这种情况下,可以使用with torch.no_grad(),强制之后的内容不进行计算图构建。”
使用with torch.no_grad()使梯度计算为FALSE,不占用内存。
predict_y = torch.max(outputs, dim=1)[1]输出为outputs=[batch,10],第0个维度为batch,第一个为输出节点数,在第一个维度输出节点上找出最大值,判断图片最可能属于哪类,并返回标签index
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
.sum()得到预测正确的个数(tensor类型,非数值),.item()获取数值,val_label.size(0)为总的验证集数据(batch)
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)保存模型
predict.py
net.load_state_dict(torch.load('Lenet.pth'))下载权重文件
transform = transforms.Compose(
[transforms.Resize((32, 32)),#缩放图片
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#标准化处理resize规范预测图片大小为32*32
im = Image.open('1.jpg')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]#增加维度打开图片,预处理,增加batch维度
关于dim=1及numpy():
torch.max(outputs, dim=1)[1].numpy()试运行
predict = torch.max(outputs, dim=1)[1].numpy()
print(torch.max(outputs, dim=1)) output=tensor([[ 4.6519, -5.5569, 2.6880, -0.3982, -4.0505, -2.3412, -4.2065, -4.3898,
2.3575, -6.6056]])
输出:
torch.return_types.max(
values=tensor([4.6519]),
indices=tensor([0]))运行:
print(torch.max(outputs, dim=1)[1])输出:
tensor([0])运行:
print(torch.max(outputs, dim=1)[1].numpy())输出:
[0].numpy()将Tensor数据转换成数组
总结:
output是个一维数组,在一维度上返回max,输出一个含最大值索引和数值的tuple,取出索引值,利用numpy()将tensor类型转化成数组