2022/10/30周报
目录
摘要
一、文献阅读
1、题目
2、背景以及问题的提出
3、数据处理
4、模型构建
5、结果分析
6、与传统方法的对比
7、讨论
二、工程项目
1、从控制器传数据到视图上
2、数据从视图传到控制器上
三、深度学习
1、创建图、启动图
2、变量
3、Fetch和Feed
4、简单示例
总结
摘要
在文献阅读方面,我阅读了一篇基于卷积神经网络的地震震级测定研究的论文,将卷积神经网络应用于地震震级的预测,对比传统的方法,卷积神经网络更加占优势,可以做出更高可靠的预测。在工程项目上面,学习了如何在控制器和视图之间相互传递数据。在深度学习上,决定系统的学习tensorflow代码,完善自身的代码能力。
In terms of literature reading, I read a paper on the study of earthquake magnitude measurement based on convolutional neural network. The paper applied convolutional neural network to earthquake magnitude prediction. To compare with traditional methods, convolutional neural network is more dominant and can make more reliable predictions. In the project, I learned how to pass data between controllers and views. In terms of deep learning, I will learn the code of tensorflow systematacially and improve my own coding ability.
一、文献阅读
1、题目
基于卷积神经网络的地震震级测定研究
doi:10.6038/cjg2021O0370
2、背景以及问题的提出
地震预警震级的快速测定是地震学家面临的挑战性难题,其难度在于所利用的台站既少又离震中较近,而且只能 利用P波触发后几秒钟的信息,而此时P波的发育还不充分,难以准确测定震级,尤其是大震震级。在现有的测定方法中,最具代表性的是是利用周期和位移峰值测定震级的方法。单一的幅值或周期参数在一定程度上能够较好映射出地震的规模,但较难反映出地震的全部特征,从而导致地震震级测定的精度不足。在此文章中设计以地震三分量波形数据作为输入,震级类别作为输出,训练出3s样本的CNN震级预测模型。
3、数据处理
选取不同震级样本,并且截取P波到时前0.2s至P波到时后2.8s的数据段(带有振幅信息)作为训练数据。
不同震级的3s样本波形存在较大差异,如ML2.0样本波形含有较为丰富的高频信息,ML6.1样本波形的长周期成分较强,即随着震级增加,波形的优势周期增大,为深度神经网络的学习奠定重要基础。
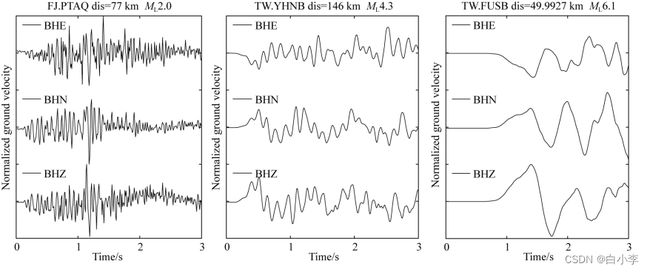
将地震震级进行分类,2-2.2的为第一类,2.3-2.5的为第二类,2.6-2.8为第三类,诸如此类划分下去,直到最后一类为大于7.6的,总共有20类数据。
震级公式
![]()
A为水平向的峰值振幅;R(Δ)为仪器的量规函数,随震中距变化的函数,其物理意义是补偿地震波随距离的衰减;S为台站场地校正项.为了测定震级,需要获取平均衰减模型和场地函数.神经网络可以从训练数据中学习到这些关系。
文章设计了针对带振幅信息输入的卷积神经网络,将震级输出划分为20个不同震级类别,降低了震级输出的离散性,提高了 每组类型判别的样本数量.另外,通过在卷积层中增 加 RELU激发函数以及采用 ADAM优化算法使模型参数值更加稳定,解决了输入未归一化数据容易引起梯度变化过大的问题,提高模型的识别效果。
4、模型构建
相关原理
模型框架针对地震波三通道检测,采 用卷积核 1✖3,每层卷积通道数为 64道,选 用 128批 次 和RELU 激活函数.另一方面根据实测数据的调参试验获得最优模型参数。
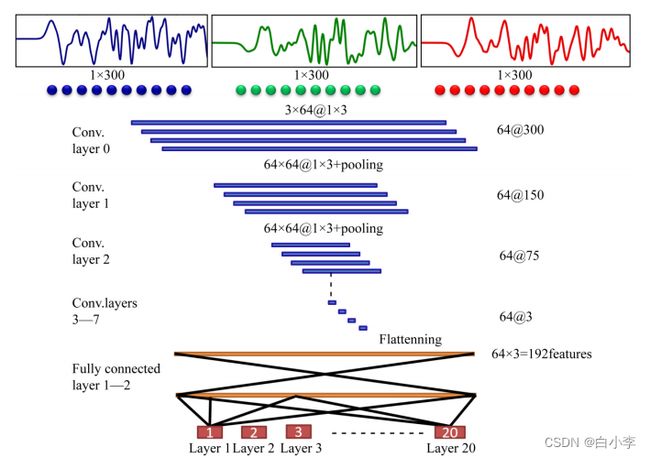
训练过程采用小批次随机梯度下降法(SGD)算法、增加L2正 则 化 防 止 过 拟 合、以 及ADAM 优 化算 法,学 习 率 取0.001,训 练 的 目 标 误 差 为0.08,迭代10000次进行学习训练。
5、结果分析
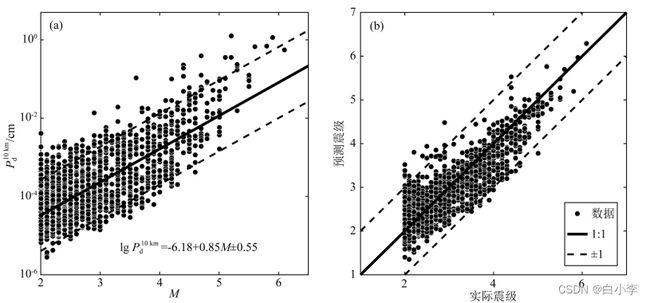
将训练集数据通过卷积神经网络进行仿真预测,得 到训练集的预测震级与实际震级的关系(图a);将 测试集数据进行仿真预 测,得到测试集的预测震级与实际震级的关系(图b)。可以看出训练集的离散度较小,几乎都 集 中1:1的对角线上,震级偏差的标准差为0.106;而测试集的离散度较大些,震级偏差的标准差为0.231。
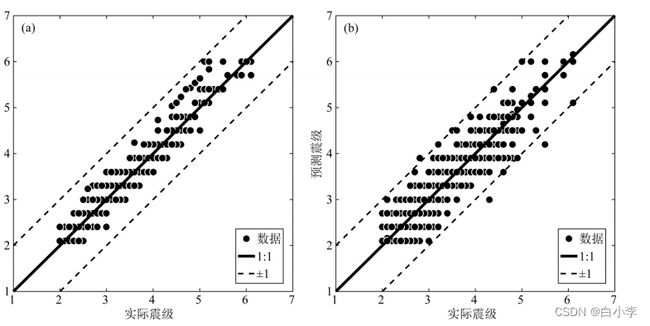
接下来将模型预测的震级值于实际震级值进行对比,由预测值减去真实值,允许的误差范围为前后0.3。对比公式如下。
![]()
测试结果的震级偏差整体呈正态分布,平均震级偏差为0.028,标准差为 0.231,最大震级偏差为-1.3。其 中 预测值与 真实值震级偏差控制在±0.3以 内的占85.6%,预测值与 真实值震级偏差控制在±0.5以内高达95.7%。
在有较多震例上,模型的预测效果很好,但在震例较少的预测结果上,与真实值存在较大的误差,并且由于例如震源较远,地理环境较为其它区域更加复杂的情况下,预测结果不如预期值。
6、与传统方法的对比
周期特征类τc 方法提 取出每条台站记录P波段的周期特征参数,再采用 M=a+blg(τc)形式拟合,得到τc特征参数与地震震级间的关系:
![]()
与CNN对比获得两者震级偏差的标准差为0.79个震级单位。
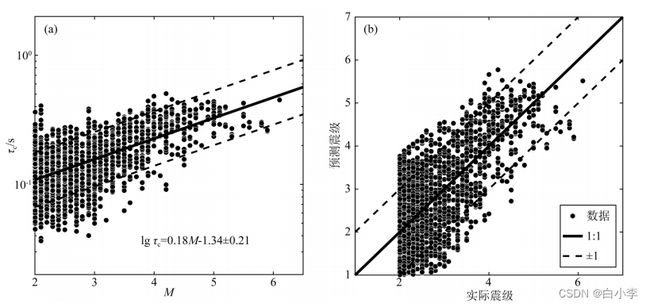
根据幅值特征类Pd方法提取出经过高通滤波器(低 频 截 至 频 率 为0.075HZ) 滤波的位移幅值特征参数,再采用 M=a+blg(R)+clg(Pd)形式拟合,得到 Pd 特征参数与地震震级间的关系:
![]()
与CNN对比两者震级偏差的标准差为0.40
综上,可以看出τc 方法和Pd方法还 不够稳定,既有好的预测效果,也有差的预测效果. CNN模型在样本充足的情况下可以做出高可靠的预测,因此在实际应用中有必要将多种方法联合分析,更大程度的发挥新技术带来的优势。
7、讨论
地震震级测定是一个非常难的问题,其受地震震源深度、区域衰减、台站场地等多种因素的影响.根据地震震源深度的不同,震级度量方法也不同.对 于浅源地震,通常选用里氏震级Ml和面波震级Ms;对于深源地震,通常采 用体波震级mb。考虑区域衰减的影响,主要体现在量规函数项,即补偿量随震中距的变化函数,不同地区的量规函数会存在一定的差异但不会太大。
文章的训练数据虽然有增加部分川滇地区 Ml>5.0的地震记录,并进行了大震样本增强处理,但是大震样本数量还是比较有限,今后可收集全国各地域的大震记录加入模型训练,并探究模型在不同地区的适用能力.随着地震数据量不断积累,网络模型不断加深和优化,在3s样本的基础上再训练出5s、8s、10s、20s等样本的震级预测模型,以满足地震预警震级连续测定的要求,进一步提高预警震级的精度和可靠度。
二、工程项目
1、从控制器传数据到视图上
第一种方法
ViewBag属于动态类型,获取动态视图数据字典
//控制器方法
public ActionResult Index()
{
//一般存放一些不主要的数据
ViewBag.Content = "这是Controller里的数据";
ViewBag.Name = "张三";
ViewBag.Age = 20;
ViewData["Age"] = 40;
return View();
}
在前端代码上通过显示
@ViewBag.Content第二种方法TempData,可以跨页面,但只能读取一次,在此方法中,数据是从Demo传到Demo2中,如果单纯刷洗Demo2是不会出现数据的。
public void Demo()
{
TempData["Hello"] = "world";
Response.Redirect("~/Home/Demo2");
}
public ActionResult Demo2()
{
return View();
}前端通过@TempData["Hello"]展示出来。
通过View来传递数据,第一个参数指定视图,第二个指定模板页,第三个数据
public ActionResult ShowData()
{
return View("ShowData2", "_Layout1",new Student()
{
Id = 1,
Name = "张三",
Age = 20
});
}Student类
public class Student
{
public int Id { get; set; }
public string Name { get; set; }
public int Age { get; set; }
}前端页面
@model WebApplication1.Models.Student
@{
ViewBag.Title = "ShowData";
}
ShowData
@Model.Id
@Model.Name
@Model.Age2、数据从视图传到控制器上
通过表单提交数据给控制器
public ActionResult ShowForm()
{
return View();
}
// GET: Demo
public ActionResult Index(string name)
{
return Content(name);
}前端代码
通过类的方法提交
public ActionResult Login(Models.LoginViewModel model)
{
if (model.Email == "admin" && model.Password == "123")
{
return Content("ok");
}
else
return Content("no");
}
public class LoginViewModel
{
[Display(Name = "电子邮件")]
[EmailAddress(ErrorMessage = "邮件名有误")]
[Required, StringLength(10, MinimumLength = 2)]
public string Email { get; set; }
[Display(Name = "密码")]
[DataType(DataType.Password)]
[Required,MinLength(6)]
public string Password { get; set; }
}
注:ASP.NETMVC有很强的生成框架功能,在类中限定好数据类型及大小,通过直接生成视图可以节省一大笔编辑前端代码的时间。
三、深度学习
在实践代码上,计划对tensorflow展开系统的学习,之前的都是需要用什么才去学什么,导致这里缺一些,那里缺一些,因此系统的学习十分重要。
1、创建图、启动图
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
#创建一个常量op
m1 = tf.constant([[3,3]])
m2 = tf.constant([[2],[3]])
#矩阵乘法,m1✖m2
product = tf.matmul(m1,m2)
print(product)
#定义一个会话,启动默认的图
sess = tf.compat.v1.Session()
#调用sess的run方法来执行矩阵乘法op
#run(product)触发了图中3个op
result = sess.run(product)
print(result)
sess.close()
with tf.compat.v1.Session() as sess:
result = sess.run(product)
print(result)输出后的结果
tf.Tensor([[15]], shape=(1, 1), dtype=int32)
[[15]]
问题:电脑安装的是tensorflow2.0,因此使用1.0版本的Session需要通过tf.compat.v1.Session()来调用以及tf.compat.v1.disable_eager_execution()语句保证run的正常运行
2、变量
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
x = tf.Variable([1,2])
a = tf.constant([3,3])
sub = tf.subtract(x,a)
add = tf.add(x,sub)
init = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:
sess.run(init)
print(sess.run(sub))
print(sess.run(add))
state = tf.Variable(0,name='counter')
new_value = tf.add(state, 1)
#复制op
update = tf.compat.v1.assign(state, new_value)
#初始化变量
init = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:
sess.run(init)
print(sess.run(state))
for _ in range(5):
sess.run(update)
print(sess.run(state))运行结果
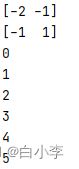
问题:在用Variable创建变量的时候,在Session使用前应该通过init = tf.compat.v1.global_variables_initializer()初始化,以及在Session的赋值操作中是调用接口,而不是简单的等于。
3、Fetch和Feed
Fetch 在会话中可以同时执行多个op,Feed创建占位符后,在Session中以字典的形式输入数据。
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
#Fetch 在会话中可以同时执行多个op
input1 = tf.constant(3.0)
input2 = tf.constant(2.0)
input3 = tf.constant(5.0)
add = tf.add(input2, input3)
mul = tf.multiply(input1,add)
with tf.compat.v1.Session() as sess:
result = sess.run([mul,add])
print(result)
#Feed
#创建占位符
input4 = tf.compat.v1.placeholder(tf.float32)
input5 = tf.compat.v1.placeholder(tf.float32)
output = tf.multiply(input4, input5)
with tf.compat.v1.Session() as sess:
#Feed的数据以字典的形式传入
print(sess.run(output,feed_dict={input4:[7.0],input5:[2.0]}))运行结果:[21.0, 7.0]
[14.]
4、简单示例
import tensorflow.compat.v1 as tf
import numpy as np
tf.disable_v2_behavior()
#使用nump生成100个随机的点
x_data = np.random.rand(100)
y_data = x_data*0.1 + 0.2
#构造一个线性模型
b = tf.Variable(0.)
k = tf.Variable(0.)
y = k*x_data + b
#二次代价函数
loss = tf.reduce_mean(tf.square(y_data-y))
#定义一个梯度下降法来进行训练的优化器
optimizer = tf.train.GradientDescentOptimizer(0.2)
tf.disable_eager_execution()
#最小化代价函数
train = optimizer.minimize(loss, var_list=[k,b])
init = tf.global_variables_initializer()
with tf.compat.v1.Session() as sess:
sess.run(init)
for step in range(201):
sess.run(train)
if step%20 == 0:
print(step, sess.run([k,b]))运行结果,一步步逼近0.1和0.2 。

问题:在tensorflow1.0和2.0不兼容的问题下,通过import tensorflow.compat.v1 as tf和 tf.disable_v2_behavior()两句话让pycharm自行的进行版本兼容问题。
总结
经过这周的学习,下周计划对CNN的变形模型进行学习,并且尝试复现代码出来。在工程项目上继续深入学习,以及对于代码方面,继续上机练习,理论联系实践才能有更好的效果。