【计算机毕业设计】深度学习的驾驶行为检测
前言
大四是整个大学期间最忙碌的时光,一边要忙着准备考研,考公,考教资或者实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
本次分享的课题是
深度学习的驾驶行为检测
课题背景与意义
驾驶汽车是一项复杂的任务,需要全神贯注。分心驾驶是指使驾驶员的注意力从道路上移开的任何活动。多项研究已确定了三种主要的干扰类型:视觉干扰(驾驶员的眼睛不在路上),手动干扰(驾驶员的手从方向盘移开)和认知干扰(驾驶员的注意力在驾驶任务上)。
美国国家公路交通安全管理局(NHTSA)报告称,2018年有36,750人死于机动车事故,其中12%是由于分心驾驶所致。发短信是最令人担忧的干扰。发送或阅读文本会使视线离开道路5秒钟。时速55英里/小时,这就像闭着眼睛开车穿越整个足球场一样。
现在许多州都制定了禁止发短信,打手机和其他开车时分心的法律。计算机视觉可以防止因分心驾驶而导致的事故。算法会自动检测驾驶员分心的活动并发出警报。设想将这种产品嵌入汽车中,以防止因分心驾驶而导致事故。
课题实现技术思路
数据
获取了StateFarm数据集,其中包含安装在汽车中的摄像头捕获的视频的快照。训练集具有22.4 K标记的样本,这些样本在各类之间平均分配,还有79.7 K的未标记的测试样本。有10类图像:
https://www.kaggla.com/c/state-farm-distracted-driver-detection

图:来自训练数据的样本图像
评估指标
在继续构建模型之前,重要的是选择正确的度量标准来衡量其性能。 准确性是想到的第一个指标。但是准确性不是分类问题的最佳指标。准确性仅考虑预测的正确性,即预测的标签是否与真实标签相同。但是将驾驶员的行为分类为分散注意力的信心对于评估模型的性能非常重要。值得庆幸的是,有一个指标可以捕捉到这一数据-Log Loss。
对数损失(与交叉熵有关)用于衡量分类模型的性能,其中预测输入为0到1之间的概率值。机器学习模型的目标是最小化该值。理想模型的对数损失为0,并且随着预测概率与实际标签的偏离而增加。因此,当实际观察标签为1时预测0.3的概率将导致较高的对数损失

图:评估指标
数据泄露
了解了需要实现的目标后,从头开始构建了CNN模型。添加了通常的可疑对象-卷积批处理规范化,最大池化和密集层。结果—在3个时间段内进行验证时,损失0.014,准确性为99.6%。

图:初始模型结果
考虑了一下意外构建世界上最好的CNN架构的一秒钟。因此使用此模型预测了未标记测试集的类。
关键时刻

图:模型的类别预测
因此对可能出了问题的地方进行了更深入的研究,发现训练数据具有类中同一个人的多个图像,并且角度和/或高度或宽度发生了细微变化。这也导致了数据泄漏问题,因为相似的图像也正在验证中,即模型已被训练了许多试图预测的相同信息。
数据泄漏解决方案
为了解决数据泄漏的问题,根据人员ID分割图像,而不是使用80-20随机分割。
现在,将模型与修改后的训练和验证集进行拟合时,将看到更现实的结果。实现了1.76的损失和38.5%的准确性。

图:应对数据泄漏后的模型拟合
为了进一步改善结果,探索并使用了久经考验的深度神经网络体系结构。
迁移学习
迁移学习是一种方法,其中为相关任务开发的模型被重用为第二个任务上的模型的起点。可以重用针对标准计算机视觉基准数据集开发的预训练模型的模型权重,例如ImageNet图像识别挑战。通常将替换具有softmax激活的最后一层以适合数据集中的类数。在大多数情况下,还会添加额外的层以针对特定任务定制解决方案。
考虑到开发用于图像分类的神经网络模型所需的大量计算和时间资源,它是深度学习中的一种流行方法。此外这些模型通常在数百万个图像上进行训练,这在训练量较小时尤其有用。这些模型体系结构中的大多数都是公认的赢家-利用的VGG16,RESNET50,Xception和Mobilenet模型在ImageNet挑战中取得了非凡的成绩。
图像增强
datagen = ImageDataGenerator(height_shift_range = 0.5,width_shift_range = 0.5,zoom_range = 0.5,rotation_range = 30)#datagen.fit(X_train)data_generator = datagen.flow(X_train,y_train,batch_size = 64)
图:图像增强的示例代码
由于训练图像集只有约22K图像,因此希望从训练集中综合获取更多图像,以确保模型不会因神经网络具有数百万个参数而过拟合。图像增强是一种通过执行诸如移动宽度和/或高度,旋转和缩放之类的动作从原始图像创建更多图像的技术。

图:在数据集中实现的图像增强类型
对于项目,“图像增强”还具有其他一些优势。有时来自两个不同类别的图像之间的差异可能非常细微。在这种情况下,通过不同角度对同一幅图像进行多次查看会有所帮助。如果看下面的图片,看到它们几乎相似,但是在第一张图片中,类别是“打电话”,第二张图片属于“头发和化妆”类别。

图:图像类混淆示例(i)接电话(ii)头发和化妆
额外的层
为了使迁移学习的价值最大化,添加了一些额外的层来帮助模型适应我们的用例。每层的目的:
-
全局平均池化层仅保留每个补丁中值的平均值
-
辍学层有助于控制过度拟合,因为它会丢弃一部分参数(提示:尝试使用不同的辍学值是个好主意)
-
批处理归一化层将输入归一化到下一层,从而可以进行更快,更灵活的训练
-
密集层是具有特定激活功能的常规完全连接层
需要训练哪些层次?
在进行迁移学习时,第一个问题是是否应该只训练添加到现有架构中的额外层,还是应该训练所有层。从使用ImageNet权重开始,并且仅训练新层,因为要训练的参数数量会更少,而模型会训练得更快。验证设置的准确性在25个时期后稳定在70%。但是,通过训练所有层,能够获得80%的精度。因此,决定继续训练所有层次。
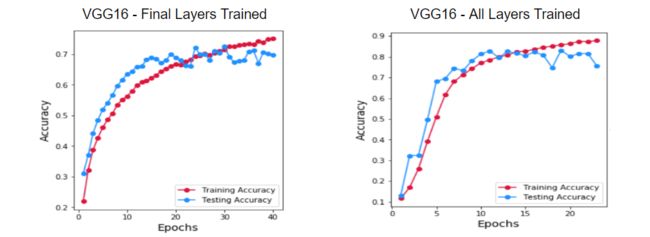
图:最终层和所有训练层的模型精度比较
使用哪个优化程序?
优化器通过在目标函数wrt与参数的梯度相反的方向上更新参数来最小化由模型的参数参数化的目标函数。
深度学习世界中最流行的算法是Adam,它结合了SGD和RMS Prop,在大多数问题上,其性能始终优于其他优化器。但,在案例中,当SGD正在逐渐学习时,Adam表现出下降的不稳定模式。通过进行一些文献调查,发现在少数情况下SGD优于Adam,因为SGD的泛化效果更好(link)。由于SGD提供了稳定的结果,因此将其用于所有模型。
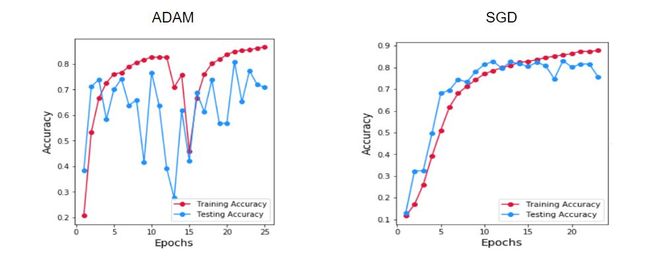
图:使用(i)亚当(ii)SGD跨时期的精度
集成模型
现在有了7个最佳模型,这些模型之间的后验概率差异很大,尝试了多种集成技术来进一步改善对数损失。
-
均值组合:这是最简单,使用最广泛的组合方法,其中后验概率被计算为组件模型中预测概率的平均值。
-
均值修整:这是均值拼合,是通过从每个图像的组件模型中排除最大和最小概率来实现的。它有助于进一步平滑我们的预测,从而降低对数损失值。
-
集成的KNN:由于在驾驶员从事分散注意力的活动或驾驶时,所有图像均从视频片段中捕获,因此有很多相同类别的图像相似。在此前提下,找到相似的图像并在这些图像上平均概率有助于平滑每个类别的预测概率。
为了找到10个最近的邻居,使用了VGG16传输学习模型倒数第二层的输出作为验证集的特征。

图:KNN的输出— 10个最近的邻居
海浪学长的作品示例:
大数据算法项目
机器视觉算法项目


微信小程序项目
Unity3D游戏项目
最后
为帮助大家节省时间,如果对开题选题,或者相关的技术有不理解,不知道毕设如何下手,都可以随时来问学长,我将根据你的具体情况,提供帮助。