YOLO v2原理与代码解析
目录
YOLO v1的缺点
YOLO v2相比于v1做的改进
Darknet-19
Loss
Reference
论文 《YOLO9000: Better, Faster, Stronger》
代码 https://github.com/allanzelener/YAD2K
YOLO v1的缺点
- 定位错误多
- 召回率低
YOLO v2相比于v1做的改进
-
Batch Normalization. 作者为所有的卷积层都加上了BN层,得到了2%的mAP提升。
- High Resolution Classifer. YOLO v1是先用224
 224的输入在ImageNet数据集上进行预训练,然后将输入改成448448再在检测任务上微调。这样在检测任务上微调时网络既要转而学习物体位置信息同时还要适应新的输入大小。YOLO v2改成先用224224的输入在ImageNet上训练160个epoch,然后将输入调整到448448继续在ImageNet上训练10个epoch,然后再用448448的输入微调检测任务,这样有利于网络顺利适应输入分辨率的改变。这一做法得到了4%的mAP提升。
224的输入在ImageNet数据集上进行预训练,然后将输入改成448448再在检测任务上微调。这样在检测任务上微调时网络既要转而学习物体位置信息同时还要适应新的输入大小。YOLO v2改成先用224224的输入在ImageNet上训练160个epoch,然后将输入调整到448448继续在ImageNet上训练10个epoch,然后再用448448的输入微调检测任务,这样有利于网络顺利适应输入分辨率的改变。这一做法得到了4%的mAP提升。 - Convolutional With Anchor Boxes. 作者借鉴Faster RCNN的思想引入anchor。首先删掉了全连接层和最后一个pooling层,使得网络输出有更高的分辨率。然后将网络输入从448448缩减到416416,这样做是为了使输出feature map的宽高是奇数,从而feature map只有一个中心点。作者发现待检测的物体尤其是大的物体大都会占据图片的中间位置,用feature map的1个中心点而不是附近的4个来预测这类物体效果会更好。YOLO v2的网络最终输出的下采样步长为32,因此输入为416416的情况下输出为1313。YOLO v1直接根据空间位置即每个网格来预测类别和objectness(objectness预测的是ground truth box和proposal box之间的IOU),YOLO v2针对每个anchor都会预测类别和objectness。使用anchor box预测准确度会有微小的下降,但召回率会有大幅提升。不用anchor box的情况下模型会得到69.5的mAP和81%的recall,用anchor box则会得到69.2的mAP和88%的recall,召回率的大幅提升意味着模型还有更多可提升的空间。
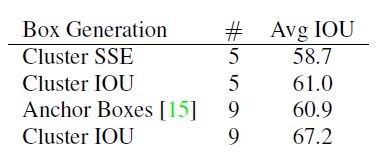
- Dimension Clusters. 作者在用anchor box的时候遇到两个问题,第一个是anchor的尺寸是手工挑选的,虽然通过训练网络可以学习到anchor box和ground truth box之间的偏差,但如果一开始能选出更合适的尺寸的anchor会更有助于网络的学习,所以作者采用k-means算法对训练集的ground truth box做聚类来自动挑选出更合适的anchor。同时作者发现如果采用以欧式距离衡量差异的标准的k-means算法,大的box相比于小的box会产生更多误差,而实际要选的anchor是希望和ground truth产生更大IOU score而和anchor的大小无关,因此采用如下的距离指标:

通过实验,通过聚类挑选的5个anchor与ground truth的平均IOU就能达到Faster RCNN手工挑选的9个anchor的效果,如果是9个anchor则平均IOU大幅超过后者。因此通过聚类得到的先验框比手动设置的更易于网络学习。
-
Direct location prediction. 用anchor box遇到的第二个问题是模型不稳定,尤其是训练的开始阶段。作者认为不稳定主要来源于预测box的中心坐标
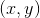 。Region proposal network中预测
。Region proposal network中预测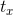 和
和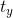 并通过如下式子得到预测box的真实中心坐标的
并通过如下式子得到预测box的真实中心坐标的
(注意论文中是减号是错误的)。当
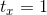 时意味着将anchor box的中心点向右偏移这个anchor box的宽度即得到预测box的真实中心
时意味着将anchor box的中心点向右偏移这个anchor box的宽度即得到预测box的真实中心 坐标。这个式子对预测位置未加限制导致任意位置的anchor box对应的预测框可以落在图片中的任意位置,随机初始化的网络需要很长时间才能稳定地预测出正确的偏差。因此作者沿用YOLO v1的方法,预测box的中心点相对于对应cell的左上角位置的偏移,这使得ground truth的值在0到1之间,作者使用了sigmoid激活函数使得网络的最终预测结果也在0到1之间。网络最终输出1313的feature map即有1313个cell,每个cell有5个anchor box来预测5个bounding box,每个bounding box预测
坐标。这个式子对预测位置未加限制导致任意位置的anchor box对应的预测框可以落在图片中的任意位置,随机初始化的网络需要很长时间才能稳定地预测出正确的偏差。因此作者沿用YOLO v1的方法,预测box的中心点相对于对应cell的左上角位置的偏移,这使得ground truth的值在0到1之间,作者使用了sigmoid激活函数使得网络的最终预测结果也在0到1之间。网络最终输出1313的feature map即有1313个cell,每个cell有5个anchor box来预测5个bounding box,每个bounding box预测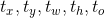 共5个值。如果某个cell相对于图片左上角的偏移为
共5个值。如果某个cell相对于图片左上角的偏移为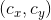 ,这个cell的其中1个anchor的宽高为
,这个cell的其中1个anchor的宽高为 ,则根据网络的预测值由如下转换可得到预测box的实际位置和大小
,则根据网络的预测值由如下转换可得到预测box的实际位置和大小

相比于直接使用anchor box,dimension clusters结合direct location prediction获得了5%的mAP提升。
-
Fine-Grained Features. 修改后的YOLO v2是在13
13的输出feature map上做预测,这对于预测大目标足够了,但如果能融合网络浅层的特征则更有利于小目标的检测。Faster R-CNN和SSD是通过在不同层的feature map上做预测来得到不同大小的proposal,YOLO v2则是通过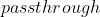 层实现浅层与深层特征的拼接。具体是将
层实现浅层与深层特征的拼接。具体是将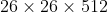 的特征图在spatial方向进行隔点采样分为4个
的特征图在spatial方向进行隔点采样分为4个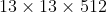 的特征图,并在channel方向进行拼接得到
的特征图,并在channel方向进行拼接得到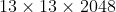 的特征图然后再与
的特征图然后再与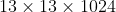 的浅层特征图进行拼接得到
的浅层特征图进行拼接得到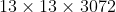 的输出,然后在该特征图上进行预测。通过passthrough层模型得到了1%的提升。
的输出,然后在该特征图上进行预测。通过passthrough层模型得到了1%的提升。 -
Multi-Scale Training. 由于网络只有卷积和池化层,网络的输入不用固定,可以在训练中进行改变。为了使模型对不同尺寸的输入图片检测效果更加鲁棒,作者引入了多尺度训练,即每迭代一定次数就改变网络的输入大小。由于网络输出下采样了32倍,因此选用32的倍数作为输入大小,共{320, 352, ..., 608}10种尺寸,即最小
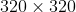 ,最大
,最大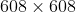 。(紧接着作者又说在
。(紧接着作者又说在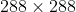 的输入上能超过90FPS)
的输入上能超过90FPS)
Darknet-19
为了使模型更快,作者设计了一个新的网络Darknet-19,由19个卷积层和5个maxpooling层组成。对于1张224224大小的图片,VGG-16一次前向推导需要30.69 billion次浮点运算,YOLO v1需要8.52 billion次浮点运算,而Darknet-19只需要5.58 billion次浮点运算。用于分类训练的Darknet-19结构如下图所示

用于目标检测训练的网络在Darket-19的基础上移除了最后一层卷积层并添加了3个331024的卷积层以及1层num_out11的卷积层,对于VOC数据集每个cell预测5个box,每个box包含5个坐标值和20个类别score,则num_out = 5(5+20) = 125。同时从最后一个33512的卷积层到倒数第二层之间添加了一个passthrough层,具体结构如下图所示

Loss
论文里并没有提到loss,对C语言不熟也没去看官方darknet框架的实现,只能通过看别人的博客来做个整理。大多采用的是以下两个版本

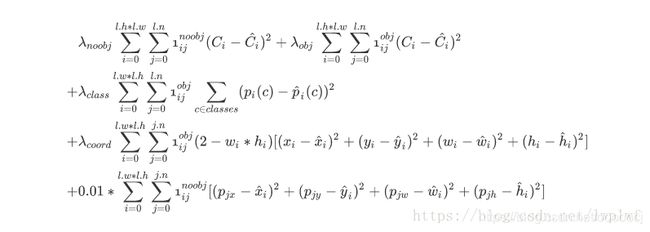
首先应该明确哪些预测框需要计算损失,对于网络输出的所有预测框,每个预测框都与各个ground truth计算IOU值,在这些IOU值中取最大值就是Max IOU。然后根据Max IOU和是否匹配ground truth可以把预测框分为三类并计算损失。
- 如果某一个预测框的Max IOU小于0.6(说明它预测背景)且不匹配ground truth, 则这个预测框计算置信度损失。
- 如果某一个预测框的Max IOU大于0.6,但是不和ground truth匹配,我们忽略其损失。
- 如果某一个预测框匹配ground truth。那么我们就要对这个预测框计算坐标、置信度和类别概率损失。
首先看一下这里的匹配ground truth的意思,和YOLO v1一样ground truth box的中心点落入哪个cell,那个cell就负责这个目标的检测。找到负责的cell后,每个cell有5个anchor分别与这个目标计算IOU,最大的那个anchor即和这个目标匹配。每个anchor会输出一个对应的预测框,网络最终会输出13135个预测框,假设一张图片中有4个ground truth,那么这13135个输出中只有4个预测框与这4个ground truth匹配。注意在找匹配anchor的过程中计算IOU时只考虑形状而不考虑具体位置,即先将anchor和ground truth box的中心对齐后(比如代码中是将中心都移到坐标原点)再进行计算。
detectors_mask, matching_true_boxes = preprocess_true_boxes(boxes, anchors, [416, 416]) # (4,5),(5,2)
# (13,13,5,1),(13,13,5,5)YAD2K中上面这行代码即是找匹配anchor的,这里输入boxes的shape为(4,5),即这张图片中有4个待检测目标,5是归一化后的每个目标中心点的坐标、宽高和类别。anchors的shape为(5,2),即5个anchor在1313的输出特征图上对应的宽高。输出detectors_mask和matching_true_boxes的shape分别为(13,13,5,1)、(13,13,5,5),这里的detectors_mask中只有4个位置值为1其余全为0,这4个位置即为上面所说的匹配的anchor,matching_true_boxes在这对应的4个位置处放着anchor与ground truth中心点坐标和宽高的偏差以及类别。
每个cell中的每个anchor都会输出一个预测框,网络最终会输出13135个预测框,每个预测框都会与所有ground truth计算IOU,然后取最大的Max IOU,注意这里计算IOU时要考虑位置,即直接按实际位置计算,因此IOU可能会小于0。
object_detections = K.cast(best_ious > 0.6, K.dtype(best_ious))
no_object_weights = (no_object_scale * (1 - object_detections) * (1 - detectors_mask))
no_objects_loss = no_object_weights * K.square(-pred_confidence)上面best_ious即为每个预测框和4个ground truth最大的Max IOU,1 - object_detection即为预测框的Max IOU小于0.6,1 - detectors_mask即为不匹配ground truth,- pred_confidence实际为0 - pred_confidence,这里计算的是no object的置信度,对应上面所说的三类预测框的第一点。
第三点所说的如果一个预测框匹配ground truth,那么我们就要对这个预测框计算坐标、置信度和类别概率损失。也就是说只有4个预测框会参与计算,只要乘以detectors_mask就可以了。
if rescore_confidence:
objects_loss = (object_scale * detectors_mask *
K.square(best_ious - pred_confidence))
else:
objects_loss = (object_scale * detectors_mask *
K.square(1 - pred_confidence))这里计算的是匹配ground truth的预测框的置信度误差,YOLO v2中有一个控制参数rescore,如果rescore是False,那么target取1。如果rescore为True,target取预测框与ground truth的IOU值。
上面两个版本的loss中,版本1的第一行计算的是no object的置信度loss,第四行计算的是object的置信度loss。版本2的第一行计算的是no object和object的置信度loss。
接下来分类Loss和坐标Loss都比较简单,采用的都是均方误差
# Classification loss for matching detections.
# NOTE: YOLO does not use categorical cross-entropy loss here.
matching_classes = K.cast(matching_true_boxes[..., 4], 'int32') # (?,13,13,5)
matching_classes = K.one_hot(matching_classes, num_classes) # (?,13,13,5,20)
classification_loss = (class_scale * detectors_mask *
K.square(matching_classes - pred_class_prob))
# Coordinate loss for matching detection boxes.
matching_boxes = matching_true_boxes[..., 0:4]
coordinates_loss = (coordinates_scale * detectors_mask *
K.square(matching_boxes - pred_boxes))
# 这里缺了coordinate_scale * (2 - true_w * true_h),起到类似于yolo v1平方根的作用但需要注意的是在计算box的坐标误差时,YOLO v1中采用的是平方根以降低boxes的大小对误差的影响,而YOLO v2是直接计算,但是根据ground truth的大小对权重系数进行修正 coord_scale (2 - truth_w truth_h),这样对于尺度较小的box其权重会更大一些,起到和YOLO v1计算平方根相似的效果。但是YAD2K这个实现中并没有加上这个权重系数。
还有一点需要注意,Loss函数版本1中的第二行和版本2中的最后一行是计算不负责预测物体的anchor的坐标损失,回归目标是anchor本身的中心位置和宽高,且只在前12800步计算。这个Loss看了很多博客还是没有搞清楚,引用其它博客的一个讲解,感觉这个讲的是最详细的一个了

YAD2K中也没有加上这个Loss。
Reference
https://blog.csdn.net/lwplwf/article/details/82895409
https://www.leiphone.com/news/201708/7pRPkwvzEG1jgimW.html
https://www.jianshu.com/p/e6582dfa6bb3
https://zhuanlan.zhihu.com/p/82099160