【Matting】MODNet:实时人像抠图模型-笔记
paper:MODNet: Real-Time Trimap-Free Portrait Matting via Objective Decomposition (AAAI 2022)
github:https://github.com/ZHKKKe/MODNet
抠图在线体验:CV案例
部署教程:
【Matting】MODNet:实时人像抠图模型-onnx python部署
【Matting】MODNet:实时人像抠图模型-onnx C++部署
NCNN 量化部署教程(模型大小降低为1/4):
【Matting】MODNet:实时人像抠图模型-NCNN C++量化部署
现有的Matting方法常常需要辅助的输入如tripmap才能获得好的效果,但是tripmap获取成本较高。MODNet是一个不需要Trimap的实时抠图算法。MODNet包含2种新颖的方法来提升模型效率和鲁棒性:
(1)e-ASPP(Efficient Atrous Spatial Pyramid Pooling)融合多尺度特征图;
(2)自监督SOC(sub-objectives consistency)策略使MODNet适应真实世界的数据。
MODNet在1080Ti上FPS为67。
抠图效果(官方提供的权重):
目录
一、MODNet
1、Semantic Estimation
2、Efficient ASPP (e-ASPP)
3、Detail Prediction
4、Semantic-Detail Fusion
二、SOC(sub-objectives consistency)
三、实验结果
一、MODNet
MODNet网络结构如图所示,主要包含3个部分:semantic estimation(S分支)、detail prediction(D分支)、semantic-detail fusion(F分支)。

1、Semantic Estimation
Semantic Estimation用来定位肖像的位置,这里仅使用了encoder来提取高级语义信息,这里的encoder可以是任意backbone网络,论文中使用mobilenetv2。这么做有2个好处:
(1)Semantic Estimation效率更高,因为没有decoder,参数减少了;
(2)得到的高级语义表示S(I)对后续分支有利;
将S(I)送入通道为1的卷积层,输出经过sigmoid得到Sp,与![]() 计算损失,
计算损失,![]() 由GT进行16倍下采样经过高斯模糊得到。使用L2损失,损失函数如下:
由GT进行16倍下采样经过高斯模糊得到。使用L2损失,损失函数如下:
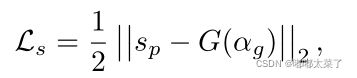
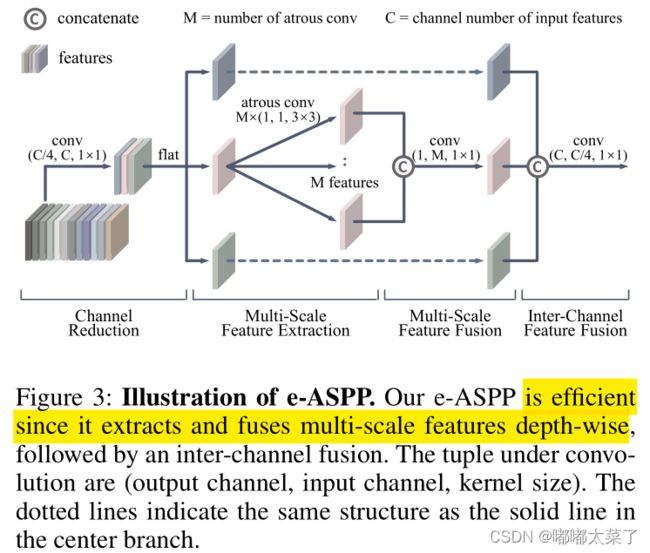
2、Efficient ASPP (e-ASPP)
DeepLab提出的ASPP已被证明可以显著提升语义分割效果,它利用多个不同空洞率的卷积来得到不同感受野的特征图,然后将多个特征图融合(ASPP可以参考这里)。
为了减少计算量,对ASPP进行以下修改:
(1)将每个空洞卷积改为depth-wise conv+point-wise conv;
(2)交换通道融合和多尺度特征图融合的顺序,ASPP是各个通道先计算,得到不同尺度特征图然后用conv融合,e-ASPP是每个通道不同空洞率的卷积,concat后融合(这里是参考论文理解的,源码没找到这部分);
(3)输入e-ASPP的特征图通道数减少为原来的1/4。
PS:这里结合图和论文看了一下,还是不太明白下图中的M是怎么来的,也有点没看到最右边的concat维度怎么回事,看了源码,好家伙,没有e-ASPP(我看错了??)。
3、Detail Prediction
Detail Prediction是高分辨率分支,它的输入由I、S(I)、S分支输出的低分辨率特征组成。D分支额外做了简化:
(1)与S分支相比,D的卷积层更少;
(2)D分支的卷积层通道数较少;
(3)分支D的所有特征图分辨率在前向传播时会降低以减少计算量;
分支D的输出是![]() ,它的目标是学习到肖像的边缘细节,它的损失函数是L1损失,如下式,其中
,它的目标是学习到肖像的边缘细节,它的损失函数是L1损失,如下式,其中![]() 是二值图,它的计算公式为
是二值图,它的计算公式为![]() 。
。

4、Semantic-Detail Fusion
分支F结合分支D和分支S的输出,预测 图,损失如下式,Lc是 compositional loss(论文传送门)
图,损失如下式,Lc是 compositional loss(论文传送门)

二、SOC(sub-objectives consistency)
发丝级的Matting数据标注成本非常高,常用的数据增强方法是替换背景,但是这样生成的图像和生活中的图像相差甚远,因此现有的trimap-free模型常常过拟合训练集,在真实场景下表现较差。
论文提出了一种自监督方法,不需要标注数据即可训练网络,使其适应真实世界的数据。MODNet分支S的输出为S(I),F的输出为F(S(I), D(S(I)))。S(I)是F(S(I), D(S(I)))的先验,可以利用这种关系实现自监督训练(有了预测结果F(S(I), D(S(I))),将其下采样然后模糊当作S(I)的标签)。
假设模型为M,有:

设计损失函数(和有监督的损失类似,不过这里用![]() 来代替
来代替![]() ):
):
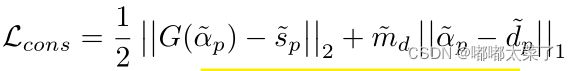
上面的损失函数后半部分如下,它存在一个问题:只需要模型不预测任何细节就可以使损失最小。

改进方法也比较简单,在自监督训练时,创建模型M的副本M',用M'预测的![]() 作为目标值(用
作为目标值(用![]() 替换上式的
替换上式的![]() )。因为M'也输出
)。因为M'也输出![]() ,在给细节分支加上正则化损失Ldd:
,在给细节分支加上正则化损失Ldd:
![]()
SOC优化过程中,使用Lcons+Ldd作为损失。
三、实验结果
1、PPM-100
在数据集PPM-100上表现如下。

2、真实世界Matting
OFD(One-Frame Delay):一个简单的视频抠图策略,对于连续的alpha图![]() \
\![]() \
\![]() ,如果
,如果![]() 和
和![]() 非常接近,且
非常接近,且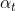 和它两差值大,那么说明可能存在抖动,将其移除并用
和它两差值大,那么说明可能存在抖动,将其移除并用![]() 代替。
代替。
为了让MODNet更适应真实数据,从400个视频裁剪了50000张图片,使用SOC自监督训练。下图蓝框为SOC训练后改进的结果,橙框为OFD的效果。
