3D 池化(MaxPool3D) 和 3D(Conv3d) 卷积详解
3D 池化(MaxPool3D) 和 3D(Conv3d) 卷积详解
池化和卷积的过程是类似的,只是池化没有权重,相比起来更容易说明计算的过程。这里从 3D 池化开始详细介绍 MaxPool3D 和 Conv3d 的过程,并尝试通过 2D 和 1D 的池化来实现 3D 池化的过程。
3D (池化或者卷积)相比 2D 增加了一个维度,但是大致过程依然和 2D 类似,所以在看 3D 之前应该确保已经清楚 2D 的过程了,如果对 2D 不熟悉的朋友,可以参考 动图详细讲解 LeNet-5 网络结构,里面有动图演示。
3D 操作在视频处理中比较常见。通常模型的输入尺寸为 [N, C, H, W],在视频中通常会加入时间维度也就是输入多帧图像,输入尺寸为 [N, C, F, H, W],其中 F 为 帧数。
1. 3D 池化(MaxPool3D)
下面是调用 pytorch 中的 MaxPool3d,具体的 API 可以参考官方文档: torch.nn.MaxPool3d。
maxpool = torch.nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2), padding=(1, 0, 0))
参数也都是三维的,分别对应 F, H, W。相比 2D 就是多了 F 维。这里重点关注第 0 维(也就是 F)的意义。
- kernel_size
F 维的 kernel_size 为 2,说明在 F 维的覆盖的 frame 数为 2,也就是每次有 2 个 frame 加入运算。
- stride
F 维的 stride 为 2,说明每次的跨度为 2。
- padding
F 维的 padding 为 1,说明需要在 F 维做 padding,也就是会在输入的输入之前和之后各做 1 个 frame 的padding。
比如对于上面的 maxpool 的输入为 [1, 2, 3, 4, 4]。如下所示。

3D pooling 的计算过程如下。Frame0 和 Frame4 是填充的 frame。kernel 每次覆盖两个 frames。对应图中的结果应该是 6。依次遍历,直到 Frame 0 和 1 遍历完成。

由于 stride 为 2,所以当 Frame 0 和 1 遍历完成后,跳到 Frame 2 和 3。
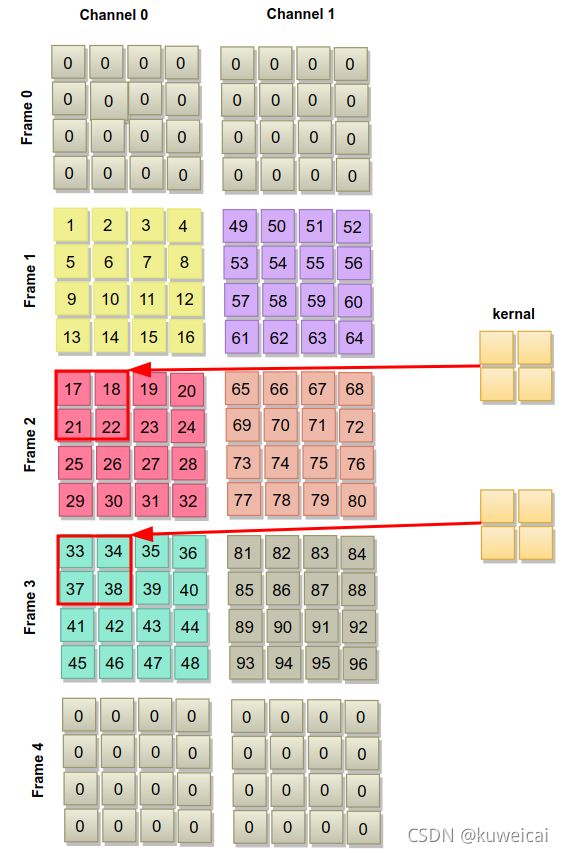
最后的计算结果如下。
tensor([[[[[ 1., 3., 4.],
[ 9., 11., 12.],
[13., 15., 16.]],
[[33., 35., 36.],
[41., 43., 44.],
[45., 47., 48.]]],
[[[49., 51., 52.],
[57., 59., 60.],
[61., 63., 64.]],
[[81., 83., 84.],
[89., 91., 92.],
[93., 95., 96.]]]]])
结合上面的计算过程,利用 MaxPool2d 和 MaxPool1d 实现 MaxPool3d 的功能。代码如下。
# input 4D: n*f c h w, n == 1
class my_pool3d(torch.nn.Module):
def __init__(self,kernel_size, stride, padding=(0, 0, 0)):
super(my_pool3d, self).__init__()
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.max_pool_2d = torch.nn.MaxPool2d(kernel_size[1:], self.stride[1:], padding[1:])
self.max_pool_1d = torch.nn.MaxPool1d(kernel_size=kernel_size[0]) # stride is kernal_size
def get_size(self, input_size):
# out_d0 = int((input_size[0] + 2 * self.padding[0] - self.kernel_size[0])/self.stride[0]) + 1
out_d1 = input_size[1]
out_d2 = int((input_size[2] + 2 * self.padding[2] - self.kernel_size[2])/self.stride[2]) + 1
out_d3 = int((input_size[-1] + 2 * self.padding[-1] - self.kernel_size[-1])/self.stride[-1]) + 1
return (-1, out_d1, out_d2, out_d3)
def forward(self, x):
input_size = x.shape #
out_size = self.get_size(input_size)
if self.padding[0]:
padding = torch.zeros((1, input_size[1], input_size[2], input_size[3]))
for _ in range(self.padding[0]):
x = torch.cat((padding, x), dim=0)
x = torch.cat((x, padding), dim=0)
f = int(x.shape[0]// self.stride[0]) * self.stride[0]
x = x[:f, :, :, :]
x = self.max_pool_2d(x) # 2d max pool
x = x.transpose(1, 0) # c n h w
x = x.reshape(x.shape[0], x.shape[1], -1) # reshape to [c n h*w]
x = x.permute(0, 2, 1) # cn(h*w) -> c(h*w)n
x = self.max_pool_1d(x) # 1d max pool
x = x.transpose(2, 1) # c(h*w)n -> cn(h*w)
x = x.reshape(out_size) # reshape to out_size
return x
# size: list
def gen_data(size):
total = reduce(mul, size)
tensor = torch.arange(1, total + 1, step=1)
return tensor.reshape(size).float()
if __name__ == '__main__':
input_size = (1, 2, 3, 4, 4) # n c f h w
input = gen_data(input_size)
model = torch.nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2), padding=(1, 0, 0))
# release below code to run my_pool3d
# input = input.squeeze(0).transpose(1, 0) # n c f h w -> f c h w
# model = my_pool3d((2, 2, 2), (2, 2, 2), padding=(1, 1, 1))
# export_onnx(model)
print(input)
output = model(input)
print(output)
print('\noutput shape: ', output.shape)
pass
2. Conv3d
相比 MaxPool3D, Conv3d 的计算过程是一样的,唯一的区别在于 Conv3d 有权重,如果要改写的话,需要注意将原来的权重重新分配到 Conv2d 和 Conv1d 中,这里不再赘述。