基于电力行业的智能读表系统--基于RK3399嵌入式设备部署
目录
- 前言
- 一、背景
- 二、系统架构
-
- 智能云读表系统
- 边缘智能读表系统
- 三、技术方案
-
- 面临的问题:
- 总体方案
- 目标检测
-
- 目标检测方案
- 目标检测模型训练
- 目标检测结果
- 语义分割
-
- 语义分割方案
- 语义分割模型训练与结果
- 语义分割训练中解决的问题
- 问题解决效果
- 读数后处理
- 四、边缘部署
-
- 总体方案
- 总体工作内容
- 模型优化
- Paddle-Lite安装
- 推理程序整体结构
- 推理程序开发
- 总结
前言
新基建
本文主要讲述,基于RK3399pro开发,C++实现工业落地。
一、背景
【需求】
1. 电力能源厂区存在很多传统的机械指针表具(原因:成本低,准确度高,工作范围比较广,比如高温等能比较好的工作,纯量占有比较大的数量)。与数字式仪表不同,机械表具无法将表具度数实时发送到监控系统,需要人工进行读数检查。
2. 电力能源厂区需要消耗大量的人力去现场读表巡检,增加了企业的人力成本,巡检周期长、频率低,更是让设备的质检、系统的稳定运行得不到有效保证。
3. 如果在非巡检期间表具度数到达异常区域,表具无法发送告警信息,异常无法被很快发现。
总结:电力能源厂区需要定期监测表计读数,以保证设备正常运行及厂区安全;
【现状】:
- 厂区分布分散,表计种类多、散
- 人工巡检耗时长,无法实时;
- 部分工作环境危险,且难以触达;
- 人工读表容易产生误差。
二、系统架构
智能云读表系统
服务端推理方案:
终端通过摄像头获取表计图像,通过网络将图像回传到云端服务,由云端服务器进行推理识别。该方案在GPU上推理进行。(如,直接使用Paddle Inference在GPU上进行推理)
以LoRa具体讲解就是:
- LoRa终端设备携带摄像头放置在仪表前获取仪表图像,并通过LoRa无线网络传输给普通的LoRa网关。
- LoRa网关通过LTE或者广域网络图片传输到CLAA的智能云服务平台,由智能云服务器进行表具读数识别,并将结果发送给各个用户应用服务器。
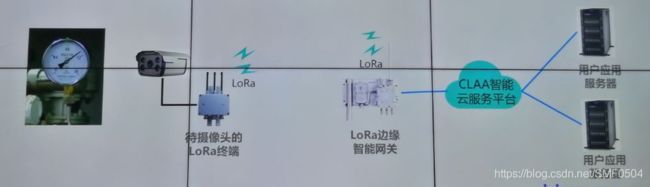
边缘智能读表系统
移动/嵌入式端推理方案:
终端通过摄像头获取表具图后通过自身附带的AI芯片在嵌入式系统进行推理。(如使用基于Paddle-lite开发对应的推理程序进行推理)
以LoRa具体讲解就是:
- LoRa终端设备携带摄像头放置在仪表前获取仪表图像,并通过LoRa无线网络传输给LoRa边缘智能网关设备。
- LoRa边缘智能网关内部署智能读表推理进程,输入仪表图片,输出仪表读数,并发送给用户应用服务器。
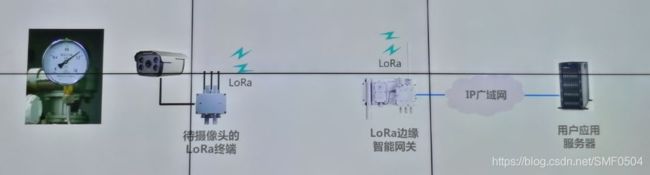
三、技术方案
面临的问题:
- 表具种类多(比如圆的、方的等),相似度大,样本采集困难,不易分类
外表高度相似,只有量程不同;
外表一致,刻度数目相同,只有单位不同;
表具单位被指针遮挡无法识别。 - 在复杂环境下,读数的精确度不容易保证
表具图片过小不清楚;刻度细小,无法完全识别。
表具图像倾斜角度大;指针高度导致读数误差。 - 室外环境恶劣导致读数难以识别
光源不确定,明暗差别大;
镜面反光或阴影强烈;
雨水或成图尘土;
污泥或异物遮挡。

总体方案
传统机械式指针表具无法将表具读数外传,需要人工进行读取,本项目使用深度学习方法实现传统机械式指针表具读数的自动读取。

针对推理部署,本项目提供了使用C++开发的,可以在RK3399Pro ARM64平台、linux系统上运行程序源码,以及程序运行所需要的针对ARM平台优化过的模型文件。
总体方案:目标检测+语义分割
表计读数方案共分为3个步骤:
第一步【检测表计】:使用目标检测算法检测待识别表具区域
第二步【分割指针&刻度】使用语义分割算法分割出表具的刻度和指针
第三步【计算读数】计算表具读数
三步骤技术实现具体如下:
-
目标检测:
平衡考虑算法的推理速度和检测效果,目标检测算法采用yolov3检测框架,主干网络使用MobileNetv2实现。目标检测部分只做检测,不对表具进行分类。 -
语义分割:
根据目标检测的结果,从原图中裁剪出表具区域图像,作为语义分割模型的输入,考虑到刻度和指针均为细小区域,采用分割效果较好的DeepLapv3+模型实现。(不过后来验证,将DeepLapv3+换成了U-Net,原因后续会提到) -
读数计算:
预先配置表具相关数据(单位、量程等),结合语意分割结果计算出表具最终读数。即,根据指针的相对位置和预知的量程计算出各表计的读数。
(注,表计多为分散安装,大多数情况每个摄像头只拍摄一个表计。在表计集中安装的情况下,多个表计基本为同类表计。需要识别表计种类(量程和单位)的场景很少。表计的单位量程等信息通过配置的形式输入给推理过程,结合分割结果计算表计读数)(拍摄完表的图片,就知道表的量程等信息了)
得到读数之后就处理业务相关的信息,比如报警等。
目标检测
目标检测方案
- 目标检测算法采用YOLOv3模型实现,被检测表具基本没有很小目标的情况,所以根据经验,人工重新设计了锚框的尺度,以便更加准确的预测目标区域。
- 目标检测部分只对表具进行检测,不进行分类识别,原因如下:
- 由于表具的种类繁多,且相似度很高,尤其是同一个厂家的同一种类表具,其只有量程或单位不同,对其进程分类是比较困难的,在单位被指针遮挡情况下根本无法识别到表具的单位。
- 厂矿表具多为分散安装,大多数情况每个摄像头质拍摄一个表具,在表具集中安装的场景下,多个表具基本为同类表具,所以需要识别表具种类(量程和单位)的场景很少。
- 表具的单位量程等信息,通过匹配的形式输入给推理进程,结合分割结果综合计算表具读数。
目标检测模型训练
模型: YOLOv3
训练:
模型选择: yolov3_darknet53 / MobileNetv2
预训练模型:Darknet53_pretrained.tar
原生YOLOv3效果:
- COCO数据集精度33.0
- 推理速度快于SSD3倍,快于RetinaNet 3.8倍(关于3.8倍,本人没有验证,只是他人告知)
YOLOv3设计:
- 骨干网络:更优的Darknet53(服务端推理方案);
MobileNetv2(移动端/嵌入式端,本文基于嵌入式端推理方案) - 每个anchor预测单独的类别,即输出通道数由B5+C,增加到为B(5+C)。
- 3个尺度上检测,提高召回率
- 分类激活函数:用sigmoid代替softmax
优化YOLOv3:
关于yolo系列的优化,它的主要思想就是利用trick的叠加,我之前有一篇博文分享了关于yolo系列优化的方案,可以参考用在此处,会使得模型精度和速度都会得到提升。

评估:评估程序进行评估。
目标检测结果

语义分割
常见分割模型:DeepLabv3+,U-Net, ICNet, PSPNet, HRNet, Fast-SCNN。
语义分割方案
- 目标检测表具图像区域作为语义分割模型的输入,避免语义分割的多尺度问题
- 表具刻度与指针都较为细小,采用效果较好的DeepLapv3+分割模型
- 如果原图检测出多个表具目标,则将多个表具区域图片以“batchsize=n”输入网络
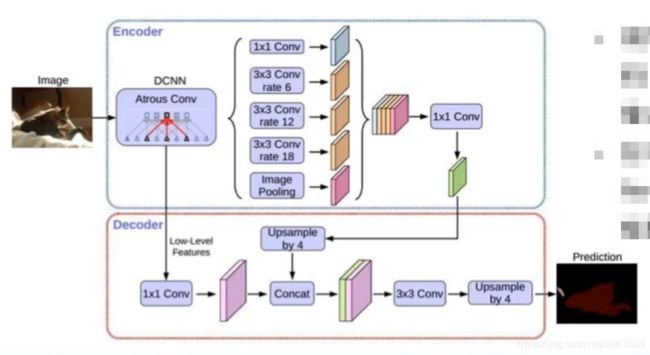

分割模型在经过卷积之后,输出的特征分辨率比较小,再赋到原图上面,分割的原图的精度就会下降。
解决:
- 采用Atrous Convolution(空洞卷积)(也就是在卷积核上插入0),在不增加计算量的情况下增大感受野;
- 在不同的卷积成中使用不同的Atrous Rate优化多尺度物体的检测效果。
简单的半监督只是蒸馏方案(SSLD)
应用背景:
- 大模型预测效果好,但预测速度太慢,速度不符合使用需求
- 小模型预测速度快,但预测效果差,精度不符合使用需求
知识蒸馏
- 对于需要训练的学生网络(较小),使用一个较大的教师网络(精度更高)去指导学生网络训练
把这两个模型组成一个网络,输出预测的输出,训练的过程中,教师模型梯度固定,学生模型可以反向,进行参数的更新。输出js的散度,就可以知道概率的相似度,使得这个小模型的概率会更好。经过训练之后,这个小模型就会有所提升。
目的
- 探索模型的性能边界
- 精度更高的预训练模型
- 有助于其他视觉任务的提升
考虑因素
- 教师网络、数据选择
- 数据分布、损失函数

语义分割模型训练与结果
模型: DeepLapv3+
训练:
模型选择: deeplap3p_xception65
预训练模型: 百度Paddle提供的deeplap3p_xception65_bn_coco
评估: 评估程序进行评估,DeepLabv3+语义分割算法的评估结果,刻度和指针的IOU达到了70%以上。
结果:

服务端:
考虑到刻度和指针均为细小区域,且主要在有GPU的设备上部署的话,所以语义分割模型选择预测效果更好的DeepLapv3+,骨干网络选择MobileNetV3-SSLD
语义分割训练中解决的问题
问题描述:
1. 刻度识别不全,有时无法识别出任务刻度和指针。
2. 侧向安装的仪表,表盘下方的刻度识别效果不好。
3. 图像尺度小的表盘,刻度识别的宽度很宽。
针对性的分析,提出优化策略:
1. 训练时加大batchsize值,可以明显提升识别效果,优化刻度识别不全问题,减少无法识别出任何刻度和指针的情况。
2. 数据增强,预处理阶段做旋转、裁剪、翻转、模糊颜色扰动等。其中,“旋转和翻转”对”表盘下方的刻度识别效果不好的问题“有很大改善。”模糊“对提高小尺寸图片识别效果作用很大。
3. 针对场景的,更细粒度的标注:开始使用labelme中的line方式对图片进行标注,该方式标注线固定为10个像素宽度,所以对于小尺寸仪表图像的刻度识别就很宽,而大尺寸仪表的识别就很窄,甚至刻度缺失。针对这个问题我们修改了生成真值图的方式,使相同尺寸的图片产生相同宽度的刻度标注线。

问题解决效果

读数后处理

- 对语义分割的预测类别图进行图像腐蚀操作,以达到刻度细分的目的;
- 把环形的表盘展开为矩形图像,根据图像中类别信息生成一维的刻度数组和一维的指针数组
- 计算刻度数组的均值,用均值对刻度数组进行二值化操作
- 定位指针相对刻度的位置,依据刻度根数获取预知的量程,将指针相对位置与量程做乘积得到读数
圆周长=圆半径×2×π
也就是说,表具外围展开一条直线。
四、边缘部署
总体方案
-
云端推理方案:非本文重点
该方案对应开遍提到的”智能云读表系统“部署方式,即终端通过摄像头获取表具图像,通过网络(LoRa)将图像回传到云端服务,由云端服务器进行推理识别。
该方案直接使用PaddleFluid在GPU上进行推理(Paddle Inference在GPU上进行推理) -
边缘推理方案:
该方案对应开篇提到的”边缘智能读表系统“部署方式,即终端通过摄像头获取表具图像,通过LoRa传送到”智能边缘网关“进行推理识别。(也就是说,终端通过摄像头获取表具图像后,通过自身附带的AI芯片在嵌入式系统基于Paddle-Lite开发对应的推理程序进行推理。)
”智能边缘网关“为ARM平台的嵌入式系统,需要使用Paddle-Lite进行针对平台的优化,并基于Paddle-Lite开发对应的推理程序。 -
目标平台: RK3399开发环境 CPU(ARMv8)
-
软件环境:
操作系统: Ubuntu16.04
基础软件: Paddle-Lite、Opencv等
开发语言: C++ -
推理模型:
PaddleDetection训练的YOLOv3模型
PaddleSeg训练的DeepLabv3+模型
由于需要在ARM环境下进行推理,所以选择使用PaddleLite进行推理部署
总体工作内容
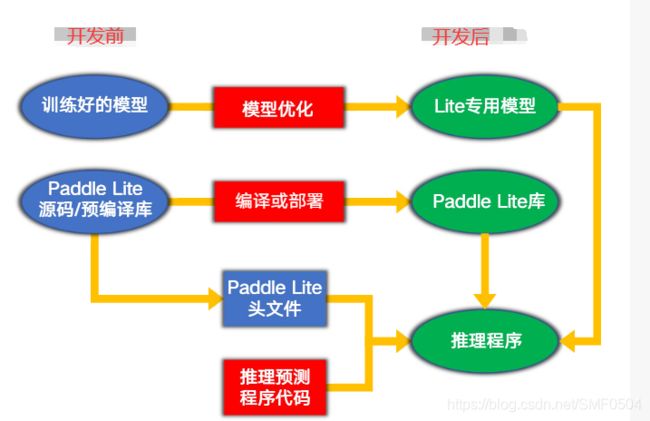
工程结构:
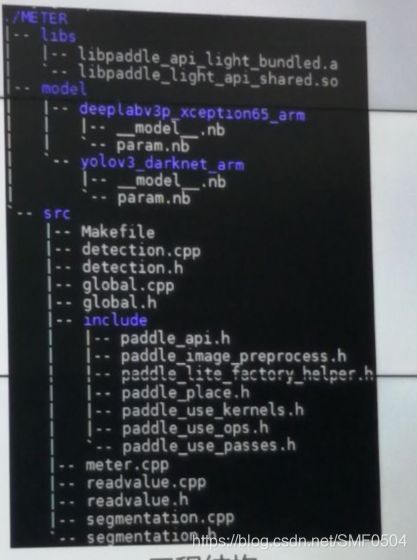
模型优化
如图:

非Paddle模型: 其他框架训练的模型 tensorflow、 caffe、onnx
Paddle模型的两种方式:
Combined:多个参数文件,一个模型结构文件
Seqerated: 一个参数文件”params";
一个模型结构文件”model“
opt工具的获取:
1. 在PaddleLite的github上下载编译好的opt工具。
2. 使用PaddleLite源码编译得到。
Paddle模型: model.nb param.nb
Paddle-Lite安装
确定优化目标:
推理平台: x86、 arm、GPU, NPU
优化类型: naive_buffer, protobuf
模型格式: Combined, Seperated
是否量化: 待优化模型是否为int8量化模型
查询算子信息:
使用opt工具查看待优化模型中的算子种类和支持这些算子的硬件平台,判断PaddleLite是否支持该模型在目标平台上运行。如下图所示:
优化工具命令:
./opt --model_file=./yolov3_darknet/__model__ --param_file=./yolov3_darknet/__params__ --optimize_out=naive_buffer --optimize_out=./yolov3_darknet_opt --valid_targets=arm
安装Paddle-Lite的最终目的是获取”库文件“和”头文件“,用于推理进程的编译和运行
预编译库:
Paddle-Lite针对常用环境预先编译了Paddle-Lite库以供下载,如果预编译的库符合用户的环境要求,用户可以直接下载使用。
下载预测时,根据需要进行选择时,注意选择”系统种类“、”arm版本“、”编译模式“。
源码编译:
如果用户找不到合适的预编译库,可以下载源码自行编译。Paddle-Lite文档中描述了不同系统下的编译方式。
编译时,注意选择”系统种类“、”arm版本“、”编译器“和”编译模式“,下载以RK3399为例说明编译方式。
./lite/tools/build.sh --arm_os=armlinux --arm_abi=armv8 --arm_lang=gcc tiny_publish
推理程序整体结构
初始化 --> 图像预处理 --> 模型输入与推理 --> 获取推理结果
# include "paddle_api.h"
using namespace paddle::lite_api;
// 初始化
// 1. set MobileConfig, model_file_path is the path to model file
MobileConfig config;
config.set_model_from_file(model_file_path);
// 2. Create PaddlePredictor by MobileConfig
std::shared_ptr<PaddlePredictor> predictor = CreatePaddlePredictor<MobileConfig>(config);
//图像预处理
std::unique_ptr<Tensor> input_tensor(std::move(predictor->GetInput(0)));
input_tensor->Resize({1, 3, 608, 608});
auto *input_data = input_tensor->mutable_data<float>();
for (int i=0; i< ShareProduction(input_tensor->shape()); i++) {
data[i] = 1;
}
//模型输入与推理
predictor->run();
// 获取推理结果
std::unique_ptr<const Tensor> output_tensor(std::move(predictor->GetOutput(0)));
// 转化为数据
auto output_data = output_tensor->data<float>();
推理程序开发
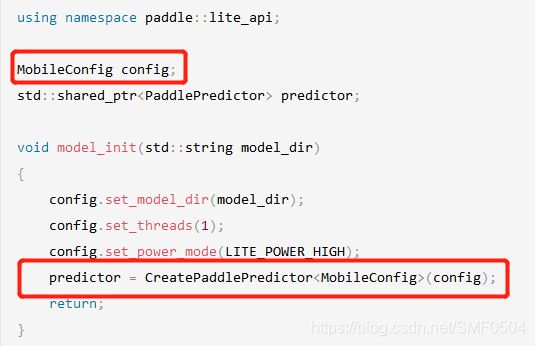
1. 初始化:
using namespace paddle::lite_api;
MobileConfig config;
std::shared_ptr<PaddlePredictor> predictor;
void model_init(std::string model_dir)
{
config.set_model_dir(model_dir);
config.set_threads(1);
config.set_power_mode(LITE_POWER_HIGH);
predictor = CreatePaddlePredictor<MobileConfig>(config);
return;
}
模型对应关系

PaddleLite编译模式 推理程序配置模式 opt输出模式
tiny_publish ----> MobileConfig ----> naive_buffer
full_publish ----> MobileConfig ----> naive_buffer
full_publish ----> CxxConfig ----> protobuf
2. 图像读取与预处理
图像的读取:
使用Opencv进行图像读取。
需要注意的是,使用Opencv的”cv::Mat“类读取的RGB图像是HWC的,如果训练的模型要求输入图片的格式是CHW的,那么需要进行格式转化。
图像的预处理
预处理主要包括:图像resize、归一化、减均值、除方差
均值和方差要与训练时使用的均值方差保持一致。如果使用预训练模型进行训练,则一般使用预训练数据的均值和方差。
代码如下:
void preprocess(cv::Mat &input_image,
const std::vector<float> &input_mean,
const std::vector<float> &input_std,
int width, int height, float *output_data)
{
cv::Mat im_temp;
cv::Size resize_size(width, height);
cv::resize(input_image, im_temp, resize_size, 0, 0, cv::INTER_LINEAR);
int channels = im_temp.channels();
int rw = im_temp.cols;
int rh = im_temp.rows;
for (int h = 0; h < rh; ++h) {
const unsigned char* uptr = im_temp.ptr<unsigned char>(h);
const float* fptr = im_temp.ptr<float>(h);
int im_index = 0;
// hwc转chw
for (int w = 0; w < rw; ++w) {
for (int c = 0; c < channels; ++c) {
int top_index = (c * rh + h) * rw + w;
float pixel;
// 以下两行为:归一化、减均值、除方差
pixel = static_cast<float>(uptr[im_index++]) / 255.0;
pixel = (pixel - input_mean[c]) / input_std[c];
output_data[top_index] = pixel;
}
}
}
return;
}

模型的输入和输出
如果时使用PaddleDetection或PaddleSeg训练的模型,建议先使用Netron查看模型结构,确认模型输入和输出的个数、数据类型等,根据查看结果编写输入输出的相关程序。



3. 图像数据输入与推理
3.1 检测模型输入:
先获取模型的输入数据接口,然后将处理后的数据赋值给模型的输入,再进行推理。
第一个数据入口:
std::unique_ptr<Tensor> input_tensor(std::move(predictor->GetInput(0)));
input_tensor->Resize({1, 3, 608, 608}); # 这里写的输入是608为例,实际中,我使用的是416,代表中如果输入将来有变化,可以写成变量传入的。
auto *input_data_1 = input_tensor->mutable_data<float>();
第二个数据入口:
std::unique_ptr<Tensor> input_tensor_2(std::move(predictor->GetInput(1)));
input_tensor->Resize({1, 2});
auto *input_data_2 = input_tensor_2->mutable_data<float>();
3.2 模型的推理
模型输入赋值完成之后,只需要调用接口函数即可实现推理。
predictor->run();
4. 获取推理结果:
与对输入的处理类似,获取推理输出结果也需要先获取模型的输出数据接口,然后能获取到输出数据。
std::unique_ptr<Tensor> output_tensor(std::move(predictor->GetOutput(0)));
//yolov3的输出;output_data:推理结果出口
float *output_data = output_tensor->mutable_data<float>();
5. 推理结果后处理
一般情况下,根据实际的业务需求,都需要对模型的输出结果再进行后处理,尤其时语义分割的识别结果。所以需要清楚模型输出结果的具体含义。
YOLOv3输出结果结构
struct DETECTION_RESULT {
float classid;
float score;
float left;
float top;
float right;
float buttom;
};
后处理计算读数:
首先展开成一维数组,接着二值化,然最后得到表的读数。

总结
模型选择:
1. 适应场景,适配部署环境
2. 多模型的配合与衔接
3. 是配图像的后处理(分割中后处理还是很重要的)
模型调优:
1. 数据集的优化
2. 训练时的数据增强方法
3. 超参数的调整
推理部署:
1. 推理平台与模型的适配
2. 模型优化(包括模型压缩)
3. 模型的输入与输出,推理程序的编写
当然大家也可以选择其他的框架,并非只有PaddleLite,比如说tensorflow-lite。
我的模型是由TF转过来的。关于yolo,我一般使用的训练框架是TF、darknet训练,然后看需要转为各自需要的模型。比如,使用darknet训练的yolo目标检测的模型转为caffe,然后caffe由它自己的量化工具转为海思相机支持的wk格式。方式很多,大家根据自己情况来选择,本文主要目的是为了让大家知道怎么来工业化落地。