Part2 深度学习实践 --- 1 AI框架使用(Pytorch)
1 AI框架使用(Pytorch)
本博客与代码已同步到github当中,欢迎各位读者为此项目提供宝贵的issue
每小节都有对应的可执行notebook文件。
1.1 基本数据操作
由于本人能力有限,不可能将所有Pytorch的操作都进行讲解。因此强烈建议读者遇到问题时候查阅Pytorch的官方文档和参与一些论坛社区的讨论。
1.1.1 安装
对Pytorch的安装,这里也不做过多的展开介绍。可以来看沐神的视频来进行学习。
1.1.2 张量与基本运算
为此我们首先导入torch
import torch
# 为了后续方便我顺便将下面这些库也导入
import numpy as np
Tensor的创建
可以通过我们熟悉的List或者Numpy来进行创建
list_form = [[1, -1], [2, -2]]
x1 = torch.tensor(list_form) # 从list中创建
x2 = torch.from_numpy(np.array(list_form)) # 从numpy中创建
x1, x2
当然tensor也可以转换为numpy
x = x1.numpy()
x
其他类型tensor的创建
- arange来进行创建
x = torch.arange(12)
print(x)
x.shape, x.numel() # 形状,数量
- 空Tensor(size为 3 × 4 3 \times 4 3×4)
x = torch.empty(3, 4)
x
- 随机初始化
x = torch.rand(3, 4) # 元素在(0, 1)之间
x
- 单位tensor(元素全为1)
x = torch.ones(3, 4)
x
- 指定元素类型的tensor
x = torch.ones(3, 4, dtype=torch.long) # 指定long类型
x, x.dtype
- 借助现有tensor创建tensor
此方法会默认重用输入Tensor的一些属性,如数据类型等
x = torch.randn_like(x, dtype=torch.float) # 正态分布,size与x一致
x
x = x.new_ones(3, 4, dtype=torch.float) # size为(3, 4)的单位tensor
x
基本运算操作
- 简单四则运算,这里以加法为例
x = x.new_ones(3, 4, dtype=torch.float)
y = torch.rand(3, 4)
x + y
z = torch.add(x, y)
z
add_代表inplace版本。pytorch其他函数也类似如x.copy_(y), x.t_()
y.add_(x)
y == z
- 索引与形状
y = x[0, :]
y += 1
y == x[0, :] # 结果为True。证明源tensor也会改变
view和reshape是常用的改变tensor.shape的函数
y = x.view(12)
z = x.view(-1, 6) # -1所指的维度可以根据其他维度的值推出来
x.size(), y.size(), z.size() # x.size开始时候为(3, 4)
深拷贝
x += 1
x, y # True, y的值也会跟着改变, 即使他们的shape不同。
因此如果我们想得到一个真正的副本而不是像上边那样共享内存,可以考虑使用reshape()函数。还有另外一个解决方案就是使用clone创建一个副本再使用view
x_cp = x.clone().view(12)
x -= 1
x, x_cp # x_cp不会跟着x改变
- Squeeze/Unsqueeze去除(增加)长度为1的指定维度(具体更多的参数可以看官方文档)
- squeeze 去除
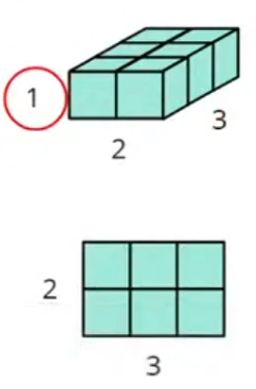
x = torch.zeros([1, 2, 3])
print(f'former shape:', x.shape) # (1, 2, 3)
x.squeeze_(0) # 可以指定维度,也可以不指定
print(f'shape after squeeze:', x.shape)
- 增加
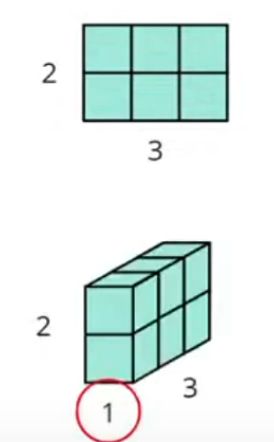
x = torch.zeros([2, 3])
print(f'former shape:', x.shape)
x = x.unsqueeze(1) # 在维度为1处添加
print(f'shape after unsqueeze:', x.shape)
- 张量转置
x = torch.zeros([2, 3])
x = x.transpose(0, 1) # 转置的维度
x.shape
- 连接多个tensor
x = torch.zeros([2, 1, 3])
y = torch.zeros([2, 2, 3])
z = torch.zeros([2, 3, 3])
a = torch.cat([x, y, z], dim=1) # 根据维度1来进行连接
a.shape # (2, 6, 3)
1.1.3 广播机制(Broadcasting) 和内存问题
广播机制
即先适当复制元素使这两个Tensor形状相同后再按元素运算。
x = torch.arange(1, 3).view(1, 2)
print(x)
y = torch.arange(1, 4).view(3, 1)
y, x + y
内存问题
使用pytorch自带的id函数:
- 如果两个实例的ID一致,那么它们所对应的内存地址相同
- 反之则不同
x = torch.tensor([1, 2])
y = torch.tensor([3, 4])
id_before = id(y)
y = y + x
id(y) == id_before # False
如果想指定结果到原来的y的内存,我们可以使用前面介绍的索引来进行替换操作。
我们把x + y的结果通过[:]写进y对应的内存中
x = torch.tensor([1, 2])
y = torch.tensor([3, 4])
id_before = id(y)
y[:] = y + x # 仅仅改写元素
id(y) == id_before # True
还可以使用运算符全名函数中的out参数或者自加运算符+=(也即add_())达到上述效果,如:
torch.add(x, y, out=y)
*
y.add_(x)y += x
x = torch.tensor([1, 2])
y = torch.tensor([3, 4])
id_before = id(y)
torch.add(x, y, out=y) # y += x, y.add_(x) # 仅仅改写元素
id(y) == id_before # True
需要注意的是,虽然view返回的Tensor与源Tensor是共享data的,但是依然是一个新的Tensor(因为Tensor除了包含data外还有一些其他属性),二者id(内存地址)并不一致。
tensor的运算(利用广播机制)
- 累计求和,特别注意axis参数
a = torch.arange(20).reshape(5, 4)
print(f'a:', a)
b = a.sum(axis=0)
print(f'b:', b)
c = a.sum(axis=0, keepdim=True) # 可以用广播机制,保留那个求和的维度
print(f'c:', c)
print(f'a/c:', a/c)
# 累加求和
print(f'a累加求和:', a.cumsum(axis=0))
- 矩阵乘法
- 矩阵乘向量
mv函数
A = torch.rand(5, 4)
x = torch.rand(4)
A, x, A.shape, x.shape, torch.mv(A, x)
- 矩阵相乘
mm函数
B = torch.ones(4, 3)
torch.mm(A, B)
- 范数
- l 2 l2 l2范数
∥ x ∥ 2 = ( ∣ x 1 ∣ 2 + ∣ x 2 ∣ 2 + ∣ x 3 ∣ 2 + ⋯ + ∣ x n ∣ 2 ) 1 / 2 \|x\|_{2}=\left(\left|x_{1}\right|^{2}+\left|x_{2}\right|^{2}+\left|x_{3}\right|^{2}+\cdots+\left|x_{n}\right|^{2}\right)^{1 / 2} ∥x∥2=(∣x1∣2+∣x2∣2+∣x3∣2+⋯+∣xn∣2)1/2
u = torch.tensor([3., -4.])
torch.norm(u)
- l 1 l1 l1范数
∣ ∣ x ∣ ∣ 1 = ∣ x 1 ∣ + ∣ x 2 ∣ + ∣ x 3 ∣ + ⋯ + ∣ x n ∣ || x||_{1}=\left|x_{1}\right|+\left|x_{2}\right|+\left|x_{3}\right|+\cdots+\left|x_{n}\right| ∣∣x∣∣1=∣x1∣+∣x2∣+∣x3∣+⋯+∣xn∣
u = torch.tensor([3., -4.])
torch.abs(u).sum()
- 矩阵 F r o b e n i u s Frobenius Frobenius范数( F F F范数,即元素平方和开根)
∥ X ∥ F = def ∑ i ∑ j X i , j 2 \|X\|_{F} \stackrel{\text { def }}{=} \sqrt{\sum_{i} \sum_{j} X_{i, j}^{2}} ∥X∥F= def ∑i∑jXi,j2
torch.norm(torch.ones(4, 9))
1.1.4 其他操作
将tensor存放在GPU当中
首先,你需要确保你的Win/Linux机器拥有英伟达(NVIDIA)的显卡。[cuda的安装地址](https://developer.nvidia.cn/zh-
cn/cuda-toolkit)
在后面章节的模型训练中,不要频繁出现tensor在gpu和cpu之间跳转,否则训练时间会大大增加。
if torch.cuda.is_available(): # 查看是否有cuda的设备
device = torch.device("cuda") # GPU
y = torch.ones_like(x, device=device) # 直接创建一个在GPU上的Tensor
x = x.to(device) # 等价于 .to("cuda")
z = x + y
print(z)
print(z.to("cpu", torch.double)) # to()将tensor转移回去cpu,同时可以更改数据类型。
1.2 数据集与训练
为了能用深度学习来解决现实世界的问题,我们经常从预处理原始数据开始,
而不是从那些准备好的张量格式数据开始。在Python中常用的数据分析工具中,我们通常使用pandas软件包。
像庞大的Python生态系统中的许多其他扩展包一样,pandas可以与张量兼容。
这里,将简要介绍使用pandas预处理原始数据,并将原始数据转换为张量格式。当然数据处理的方法还有很多,可以自行找相关资料,版块也会在后面对相关内容进行扩展。
1.2.1 数据预处理
我们首先创建一个数据集csv文件,存放在本地文件夹,以其他格式存储的数据也可以通过类似的方式进行处理。
下面我们将数据集按行写入CSV文件中。
import os
os.makedirs(os.path.join('../..', 'data'), exist_ok=True)
data_file = os.path.join('../..', 'data', 'house_price.csv')
# 重写这个文件(会覆盖掉开始的结果)
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
下面使用pandas进行相关数据处理
# 下面一行代码可以帮助你的机器安装pandas
# !pip install pandas
import pandas as pd
import numpy as np
data = pd.read_csv(data_file)
data
- 处理缺失值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
inputs
下面将NaN视为一个类别。 由于巷子类型(Alley)列只接受两种类型的类别值Pave和NaN,
pandas可以自动将此列转换为两列Alley_Pave和Alley_nan。
巷子类型为Pave的行会将Alley_Pave的值设置为1,Alley_nan的值设置为0。
缺少巷子类型的行会将Alley_Pave和Alley_nan分别设置为0和1。
inputs_fillna = pd.get_dummies(inputs, dummy_na=True)
print(inputs_fillna)
- 删除和插值
# 删除有空的那一整行
drops = inputs.isnull().any(axis=1)
inputs_dropna = inputs[~drops]
inputs_dropna
interpolate为插值函数,其相关参数可以查阅pandas官方文档
# 插值
inputs_interpolate = inputs.interpolate(limit_direction='both')
inputs_interpolate # 如果是str类型的仍然是无法填充的
- 转换为张量形式,传入pandas的values属性即可转换未完成
import torch
X, y = torch.tensor(inputs_fillna.values), torch.tensor(outputs.values)
X, y
1.2.2 数据集构建
为了后续使用pytorch求梯度更加方便
from torch.utils.data import Dataset, DataLoader
# 继承Dataset类
class MyDataset(Dataset):
def __init__(self, data):
"""读取数据和其他预处理操作"""
self.data = data
def __getitem__(self, index):
"""每次获取一个样本"""
return self.data[index]
def __len__(self):
"""返回数据集的size"""
return len(self.data)
dataset = MyDataset((X, y))
# shuffle在训练期间一般为True,测试时候为false
dataloader = DataLoader(dataset, batch_size=1, shuffle=True) # shuffle参数为True代表先扰乱数据集顺序
# 转成python的iter
next(iter(dataloader))
1.2.3 训练过程
神经网络
- 模型定义
# 模型定义
from torch import nn
# 单层线性神经网络
net_single = nn.Sequential(nn.Linear(2, 1)) # input数位2,output数位1
# 定义多层感知机
net_multi = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10)) # Relu为激活函数,接下来会讲解到
- 激活函数,常见的有:
- Relu
- sigmoid
- tanh
- softplus
下面对四种激活函数画出其图像。
import torch.nn.functional as F
import matplotlib.pyplot as plt
# 给定数据
x = torch.linspace(-3, 3, 100)
x_np = x.data.numpy()
y_relu = torch.relu(x).data.numpy()
y_sigmoid = torch.sigmoid(x).data.numpy()
y_tanh = torch.tanh(x).data.numpy()
y_softplus = F.softplus(x).data.numpy()
plt.figure(1, figsize=(8, 6))
plt.subplot(221)
plt.plot(x_np, y_relu, c='red', label='relu')
plt.ylim(-1, 5)
plt.legend(loc='best')
plt.subplot(222)
plt.plot(x_np, y_sigmoid, c='red', label='sigmoid')
plt.ylim(-0.2, 1.2)
plt.legend(loc='best')
plt.subplot(223)
plt.plot(x_np, y_tanh, c='red', label='tanh')
plt.ylim(-1.2, 1.2)
plt.legend(loc='best')
plt.subplot(224)
plt.plot(x_np, y_softplus, c='red', label='softplus')
plt.ylim(-0.2, 6)
plt.legend(loc='best')
plt.show()
- 损失函数,更多损失函数使用可以查阅[pytorch的官方文档](https://pytorch.org/docs/stable/nn.html#loss-
functions)
-
rmse:
r m s e = 1 m ∑ i = 1 m ( y i − y i ) 2 rmse = \sqrt{\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}-y_{i}\right)^{2}} rmse=m1∑i=1m(yi−yi)2 -
crossentropy:
H ( p , q ) = − ∑ x ( p ( x ) log q ( x ) H(p, q)=-\sum_{x}(p(x) \log q(x) H(p,q)=−∑x(p(x)logq(x)
rmse = nn.MSELoss()
ce = nn.CrossEntropyLoss()
- 自定义神经网络
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
"""初始化你的模型,并且定义你的层"""
super().__init__()
self.net = nn.Sequential(
nn.Linear(10, 32),
nn.Sigmoid(),
nn.Linear(32, 1),
)
def forward(self, X):
"""前向传播计算你的神经网络"""
return X - X.sum()
device = torch.device("cpu") # 默认使用cpu
if torch.cuda.is_available(): # 查看是否有cuda的设备
device = torch.device("cuda") # GPU
model = MyModel().to(device=device)
model(torch.ones(2, 10))
print('parameters is on:', model.net[0].weight.data.device)
- 模型参数保存和加载
path = '../../data/model_pa'
# 保存
torch.save(model.state_dict(), path)
# 加载
loading = torch.load(path)
model.load_state_dict(loading)
- 无参数的自定义层
# 无参数自定义层
class CenteredLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return X - X.sum()
layer = CenteredLayer()
layer(torch.FloatTensor([1, 2, 3, 4, 5]))
# 合并到更加复杂网络当中
net = nn.Sequential(nn.Linear(8, 128), CenteredLayer())
Y = net(torch.rand(4, 8))
Y.shape
- 带参数自定义层
# 带参数自定义层
class MyLinear(nn.Module):
def __init__(self, in_units, units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, units))
self.bias = nn.Parameter(torch.randn(units,))
def forward(self, X):
linear = torch.matmul(X, self.weight.data) + self.bias.data
return F.relu(linear)
dense = MyLinear(5, 3)
print(f'dense weight:', dense.weight)
net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1))
Y = net(torch.rand(2, 64))
Y.shape
模型训练
使用下面代码展示:



1.3 自动微分与简单训练实例
1.3.1 自动微分
在1.1当中已经引入过自动求导的相关代码实现。在深度学习框架当中,会根据我们设计的模型,系统会构建一个计算图(computational graph),
来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 自动微分使系统能够随后反向传播梯度。意味着跟踪整个计算图,填充关于每个参数的偏导数。
下面我们通过pytorch来实现一个简单的实例:
import torch
x = torch.arange(4.0)
x
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值为None
计算 y = 2 X T X y = 2 X^TX y=2XTX
y = 2 * torch.dot(x, x)
y
下面通过调用反向传播函数来自动计算 y y y关于 X X X每个分量的梯度
y.backward()
x.grad
显然结果和我们的数学推导 ∂ y ∂ X = ∂ ( 2 X T X ) ∂ X = 4 X \frac{\partial y}{\partial X} = \frac{\partial (2X^TX)}{\partial X} = 4X ∂X∂y=∂X∂(2XTX)=4X是一致的
x.grad == 4 * x # True
当计算关于 X X X的另一个函数的梯度时候,在默认情况下,PyTorch会累积梯度,我们需要使用x.grad_zero_()清除之前的值。
x.grad.zero_()
y = x.sum()
y.backward()
x.grad
当然,对非标量的变量也可以进行反向传播
x.grad.zero_()
y = x * x
y
- 这里的目的不是计算微分矩阵,而是单独计算批量中每个样本的偏导数之和
*
对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。
在下面例子中,只想求偏导数的和,所以传递一个1的梯度是合适的:
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad
有时候,我们希望将某些计算移动到记录的计算图之外。
例如,假设 y y y是作为 x x x的函数计算的,而 z z z则是作为 y y y和 x x x的函数计算的。我们想计算 z z z关于 x x x的梯度,但由于某种原因,我们希望将 y y y视为一个常数,
并且只考虑到 x x x在 y y y被计算后发挥的作用。
下面例子在反向传播过程中将 u u u当做一个常数进行处理:
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
简单验证一下:
x.grad.zero_()
y.sum().backward()
x.grad == 2 * x
即使在控制流语句下,梯度计算仍然可以正常工作:
d = f ( a ) = k ∗ a d = f(a) = k * a d=f(a)=k∗a
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
a.grad == d / a # 验证一下
1.3.2 简单训练实例
下面以简单线性回归为例子:
- 生成数据集(一般情况下无需自己手动生成)
import torch
from torch.utils import data
true_w = torch.tensor([2, -3.4])
true_b = 4.2
# 生成数据
def synthetic_data(w, b, num_examples):
"""生成带噪音的数据集 y = Xw + b + noise."""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
features, labels = synthetic_data(true_w, true_b, 1000)
- 加载数据
def load_array(data_arrays, batch_size, is_train=True): #@save
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
# 转成python的iter
next(iter(data_iter))
- 定义模型
# 模型定义
from torch import nn
# 单层神经网络
net = nn.Sequential(nn.Linear(2, 1))
- 初始化参数
# 初始化模型参数
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
- 定义损失函数和优化器
# 损失函数
loss = nn.MSELoss()
# 优化器
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
- 开始训练
# 开始训练
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y) # 自带模型参数,不需要w和b放进去了
trainer.zero_grad() # 优化器梯度清零
l.backward() # 自动帮你求sum了
trainer.step() # 模型更新
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')