目标跟踪——Tracking without bells and whistles
Tracking without bells and whistles
- Abstract
- 1. Introduction
- 2. A detector is all you need
-
- 2.1. Object detector
- 2.2. Tracktor
-
- Bounding box regression
- Bounding box initialization
- 2.3. Tracking extensions
-
- Motion model
- Re-identification
Abstract
在一个视频序列中跟踪多个对象的问题提出了几个具有挑战性的任务。对于tracking-by-detection,这些包括目标重识别、运动预测和处理遮挡。我们提供了一个跟踪器(没有花哨的功能),它可以完成跟踪,而没有专门针对任何这些任务,特别是,我们没有对跟踪数据进行训练或优化。为此,我们利用目标检测器的边界框回归来预测目标在下一帧中的位置,从而将检测器转换为跟踪器。我们演示了跟踪器的潜力,并提供了一个新的最先进的三个多目标跟踪基准,通过扩展它与一个直接的重新识别和相机运动补偿。
然后,我们对几种最先进的跟踪方法的性能和故障情况进行了分析,并与我们的跟踪器进行了比较。令人惊讶的是,没有一种专门的跟踪方法在处理复杂的跟踪场景方面做得相当好,即小的和被遮挡的物体或缺失的检测。然而,我们的方法解决了大多数简单的跟踪场景。因此,我们将我们的方法作为一种新的跟踪范式,并指出了未来有前途的研究方向。总的来说,跟踪器比任何当前的跟踪方法都具有更好的跟踪性能,我们的分析暴露了剩余的和未解决的跟踪挑战,以启发未来的研究方向。
1. Introduction
从视频中理解场景仍然是计算机视觉的一大挑战。而人通常是场景中关注的焦点,这就导致了(人员的检测和跟踪)是计算机视觉的一个基本问题。通过检测进行跟踪已成为解决多目标跟踪问题的首选范式,因为它将任务简化为两个步骤:1)在每一帧中独立检测目标位置;2)通过跨时间连接相应的检测来形成轨迹。由于缺失和虚假检测、遮挡和拥挤环境中的目标交互,连接步骤或数据关联本身就是一项具有挑战性的任务。
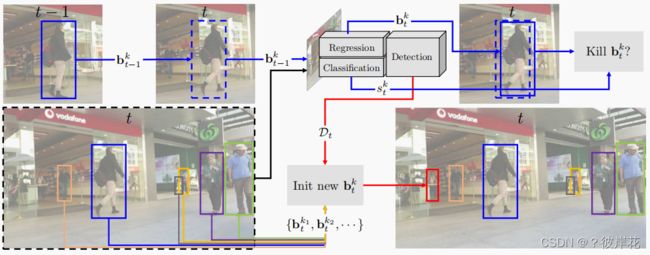
在本文中,我们仅使用一种目标检测方法进行跟踪,将通过检测跟踪推到极限。我们证明,仅通过训练神经网络,就可以实现最先进的跟踪结果。如图中的蓝色箭头所示,Faster-RCNN[52]等目标检测器的回归变量足以在许多具有挑战性的跟踪场景中构造目标轨迹。这就提出了一个我们在本文中讨论的有趣问题:如果一个检测器可以解决大多数跟踪问题,那么实际情况下需要专用的跟踪算法?
本文提出了四个主要的贡献:
- 我们引入了跟踪器,它通过利用检测器的回归头来执行对目标边界框的时间重新排列来处理多目标跟踪。
- 我们提出了对跟踪器的两个简单的扩展,一个重新识别Siamese network和一个运动模型。由此产生的跟踪器在三个具有挑战性的多对象跟踪基准测试中产生了最先进的性能。
- 我们对失败案例和具有挑战性的跟踪场景进行了详细的分析,并显示没有一种专门的跟踪方法比我们的回归方法表现得好得多。
- 我们提出我们的方法作为一种新的跟踪范式,利用检测器,并允许研究人员专注于剩余的复杂跟踪挑战。这包括对未来有前途的研究方向的广泛研究。
2. A detector is all you need
我们提出将探测器转换为跟踪器使用来执行多目标跟踪。一些基于CNN的检测算法[52,63]包含了通过回归来改进边界框的某种形式。我们利用这种回归因子来完成跟踪任务。这有两个关键优势:(1)我们不需要进行任何专为追踪的训练;(2)我们在测试时不执行任何复杂的优化,因此我们的跟踪器是在线的。此外,我们表明我们的方法在几个有挑战性的跟踪场景下达到了最先进的性能。
2.1. Object detector
我们的跟踪算法核心元素是基于回归的检测器。在我们的案例中,我们在在MOT17Det[45]行人检测数据集上训练由ResNet-101[22]和特征金字塔网络(FPN)[41]组成的Faster R-CNN[52]。
为了进行目标检测,Faster R-CNN应用RPN网络为每个潜在的目标生成大量的目标包围框建议。每个建议的特征映射通过Region of Interest(RoI) Pooling提取,并传递给分类和回归头。分类头给建议分配一个目标分数,在我们的案例中,它评估提案显示行人的可能性。回归头部细化了紧围绕一个对象的边界框位置。检测器通过应用非最大抑制(NMS)来获得最终的目标检测集。我们提出的方法利用上述的能力,回归和分类边界框,以执行多目标跟踪。
2.2. Tracktor
MOT 的挑战在于:提取给定的视频帧中的多个目标的时间和空间上位置信息,即:轨迹。这种轨迹信息被定义为:一系列有序的目标边界框的集合。 T k = { b t 1 k , b t 2 k , . . . } \mathcal{T}_k = \left\{\mathbf{b}^k_{t_1},\mathbf{b}^k_{t_2}, ... \right\} Tk={bt1k,bt2k,...},其中边界框由坐标 b t k = ( x , y , w , h ) \mathbf{b}^k_{t}=(x, y, w, h) btk=(x,y,w,h) 定义,t 表示视频的一帧。我们用 B k = { b t k 1 , b t k 2 , . . . } \mathcal{B}_k = \{\mathbf{b}^{k_1}_{t}, \mathbf{b}^{k_2}_{t}, ... \} Bk={btk1,btk2,...}表示第t帧中目标边界框的集合。注意,每个 T k \mathcal{T}_k Tk或 B t \mathcal{B}_t Bt 所包含的元素可以小于序列中帧或轨迹的总数。
在时刻 t=0,作者的 trackor 用第一组检测的结果进行初始化,即: D 0 = { d 0 1 , d 0 2 , . . . } = B 0 D_0=\{d^1_0,d^2_0,...\}=B_0 D0={d01,d02,...}=B0。在图中,我们展示了两个随后的步骤:the bounding box regression and track initialization。
Bounding box regression
第一步(蓝色箭头所示)利用边界框回归将活动轨迹扩展到当前帧 t。这是通过将t-1时刻的边界框 b t − 1 k \mathbf{b}^{k}_{t-1} bt−1k回归到对象在 t 帧的新位置 b t k \mathbf{b}^{k}_{t} btk来实现的。
在Faster R-CNN的情况下,这相当于在当前帧的特征上应用RoI Pooling,但使用之前的边框坐标。我们的假设是目标在帧间仅轻微移动,这通常是由高帧率来保证的。标识自动从之前的边界框转移到回归的边界框,有效地创建了一个轨迹。这对所有随后的帧都是重复的。
边界框回归之后,我们的追踪器考虑两种销毁追踪轨迹的方法:1)目标移动到画面之外,或被其他物体遮挡,此时它新的分类 s t k s^{k}_{t} stk得分低于 σ a c t i v e \sigma_{active} σactive;2)目标之间发生互相遮挡,这种情况将所有剩余 B t \mathcal{B}_t Bt及其对应的分数与一个IoU 阈值 λ a c t i v e \lambda_{active} λactive做一个非极大值抑制(NMS) 。
Bounding box initialization
为了能记录新的目标,目标检测器还给出第 t 帧的检测结果 D t \mathbf{D}_t Dt。这是第二步,如图中红色箭头所示,类似于t = 0时的第一个初始化。但是 D t \mathbf{D}_t Dt的检测只有当任何一个已经活动的轨道 b t k \mathbf{b}^k_t btk的IoU小于 λ n e w \lambda_{new} λnew时才会开始一个轨道。也就是说,只有在当前的检测结果中的目标没有任何一个轨迹能和它匹配的时候才会开一个新的轨迹。
需要再次指出的是,我们的跟踪器不需要针对跟踪进行专门的训练或者优化,它只依赖于目标检测方法。这使我们能够直接受益于改进的目标检测方法,最重要的是,能够相对廉价地传输到不同的跟踪数据集或场景,在这些场景中,没有标记的信息跟踪信息,只有用于目标检测的数据。
2.3. Tracking extensions
在本节中,我们将对我们的原生跟踪器进行两个简单的扩展:运动模型和再识别算法。两者都旨在改进在不同的帧间实现身份保存,这两者都是增强技术的一般例子,用来提高例如基于图的跟踪方法[39,62,35]的性能。
Motion model
我们之前的假设是,物体的位置从一帧到另一帧只是轻微的变化,这在两种情况下这个假设符合实际:一是摄像机抖动很厉害,二是视频采集的帧率很低。在极端情况下,第 t − 1 t - 1t−1 帧的画面里可能根本不包含第 t tt 帧中被跟踪的对象。因此,我们应用了两种运动模型来改善边框在未来帧未来帧中的位置。对于摄像机大抖动的视频,我们使用[16]中引入的增强相关系数(ECC)最大化算法对帧间图像进行配准,来直接补偿相机抖动产生的影响。对于帧率相对较低的视频,我们对所有对象应用恒定速度假设(CVA),如[11,2]。
Re-identification
为了让tracker 能够保持 online,作者提出利用 short-term re-ID 的方式(借助 Siamese Network 来进行 appearance feature 的匹配)来改善效果。为此,我们在其非回归版本 b t − 1 k \mathbf{b}^k_{t−1} bt−1k 中为一定数量( F r e I D F_{reID} FreID)的帧画面存储被清理(停用)的追踪目标。然后我们将未激活的追踪目标与新检测到的目标在嵌入空间中的距离进行比较,并通过阈值进行重新识别。嵌入空间距离由一个孪生CNN和每个包围框的外观特征向量计算。值得注意的是,reID网络确实是在标记过的跟踪数据上进行训练的。为了最小化虚假reIDs的风险,只有未激活和新的边界框之间有足够大的IoU才考虑匹配。这个运动模型持续在停用的目标上使用。