机器学习----使用Sklearn构建逻辑回归模型
| 1.1 什么是Sclkit-Learn?
现在我们已经建立了逻辑回归工作原理的基础,您可以参见《》。让我们深入研究一些代码来构建模型。
为此,我们将介绍一个名为 scikit-learn 的新 Python 模块。 Scikit-learn,通常简称为 sklearn,是我们的科学工具包。
所有基本的机器学习算法都在 sklearn 中实现。我们将看到,只需几行代码,我们就可以构建几个不同的强大模型。
Tips : scikit-learn 会不断更新。如果您在计算机上安装的模块版本略有不同,一切仍将正常工作,但您可能会看到与本文中的略有不同的值。
Scikit-learn 是目前记录最好的 Python 模块之一。您可以在 scikit-learn.org 找到大量代码示例
| 2.1 使用Pandas做数据预处理
现在我们需要开始使用Pandas,如果你对Pandas还不熟悉,请参考《数据科学---使用Pandas进行操作数据》学习Pandas基本操作。现在我们已经建立了逻辑回归工作原理的基础,您可以参见《机器学习----逻辑回归模型基础》。让我们深入研究一些代码来构建模型。
让我们回到我们的完整数据集并使用 Pandas 命令。下面是一个包含所有列的 Pandas DataFrame:
import pandas as pddf = pd.read_csv("titanic.csv")df.head()
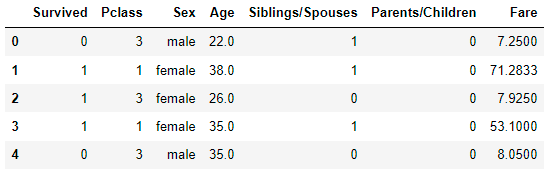
首先,我们需要将所有列设为数字。回想一下如何为 Sex 创建布尔列。
df['male'] = df['Sex'] == 'male'现在,让我们获取所有特征并创建一个名为 X 的 numpy 数组。我们首先选择所有感兴趣的列,然后使用 values 方法将其转换为 numpy 数组。
X = df[['Pclass', 'male', 'Age', 'Siblings/Spouses', 'Parents/Children', 'Fare']].values现在让我们获取目标(Survived 列)并将其存储在变量 y 中。
y = df['Survived'].valuesTips:标准做法是调用我们的二维特征数组 X 和我们的一维目标值数组 y。
| 3.1 使用 Sklearn 构建逻辑回归模型
我们首先导入逻辑回归模型:
from sklearn.linear_model import LogisticRegression所有 sklearn 模型都构建为Python类。首先实例化这个类。
model = LogisticRegression()现在我们可以使用我们之前准备的数据来训练模型。fit方法用于构建模型。它有两个参数:X(作为 2d numpy 数组的特征)和 y(作为 1d numpy 数组的目标)。
为简单起见,我们首先假设我们正在构建一个仅使用 Fare 和 Age 列的 Logistic 回归模型。首先,我们将 X 定义为特征矩阵,将 y 定义为目标数组。
X = df[['Fare', 'Age']].valuesy = df['Survived'].values
现在我们使用 fit 方法来构建模型。
model.fit(X, y)拟合模型意味着使用数据选择最佳拟合线。我们可以看到带有 coef_ 和 intercept_ 属性的系数。
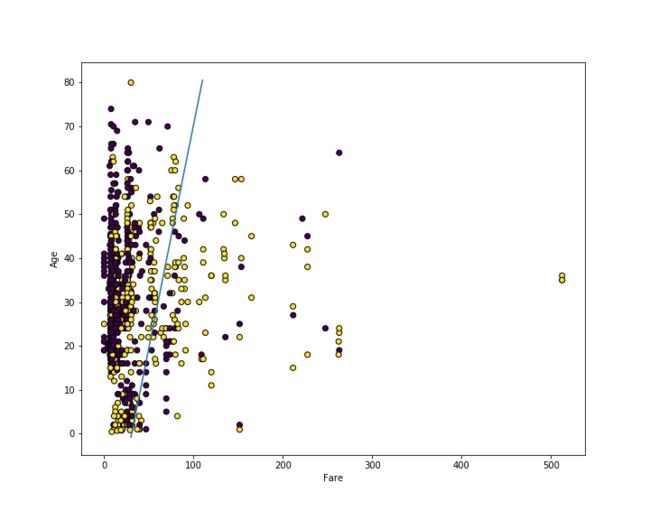
print(model.coef_, model.intercept_)# [[ 0.01615949 -0.01549065]] [-0.51037152]
这些值意味着等式如下:
0 = 0.0161594x + -0.01549065y + -0.51037152这是在图表上绘制的线。您可以看到它在分割黄色和紫色点方面做得不错(但不是很好)。我们只使用了其中的 2 个特征,这给自己造成了一些障碍,因此在接下来的部分中,我们将使用所有的特征。
Tips:很难记住不同 sklearn 模型的导入语句。如果您不记得,只需查看 scikit-learn 文档即可。
| 4.1 使用模型进行预测
我们只使用了前面部分中的两个特征确实使我们的模型受到了阻碍,所以让我们用所有这些特征重建模型。
X = df[['Pclass', 'male', 'Age', 'Siblings/Spouses', 'Parents/Children', 'Fare']].valuesy = df['Survived'].valuesmodel = LogisticRegression()model.fit(X, y)
现在我们可以使用 predict 方法进行预测。
model.predict(X)数据集中的第一位乘客是:
[3, True, 22.0, 1, 0, 7.25]这意味着乘客属于 Pclass3,男性,22 岁,机上有 1 名兄弟姐妹/配偶,0 名父母/孩子,并支付了 7.25 美元。
让我们看看模型对这位乘客的预测。请注意,即使有一个数据点,predict 方法也采用二维 numpy 数组并返回一维 numpy 数组。
print(model.predict([[3, True, 22.0, 1, 0, 7.25]]))# [0]
结果为 0,这意味着模型预测该乘客没有生还。
让我们看看模型对前 5 行数据的预测,并将其与我们的目标数组进行比较。我们用 X[:5] 获得前 5 行数据,用 y[:5] 获得目标的前 5 个值。
print(model.predict(X[:5]))# [0 1 1 1 0]print(y[:5])# [0 1 1 1 0]
我们看到5个结果全部预测正确!
Tips : predict 方法返回一个由 1 和 0 组成的数组,其中 1 表示模型预测乘客幸存,0 表示模型预测乘客没有幸存。
| 5.1 给模型打分
我们可以通过计算它正确预测的数据点的数量来了解我们的模型有多好。这称为准确度得分。让我们创建一个具有预测 y 值的数组。
y_pred = model.predict(X)现在我们创建一个布尔值数组,用于判断我们的模型是否正确预测了每位乘客。
y == y_pred要获得这些为真的数量,我们可以使用 numpy sum 方法。
print((y == y_pred).sum())# 714
这意味着在 887 个数据点中,模型对其中的 714 个做出了正确的预测。为了获得正确的百分比,我们将其除以乘客总数。我们使用 shape 属性获得乘客总数。
print((y == y_pred).sum() / y.shape[0])# 0.8049605411499436
因此模型的准确率为 80%。换句话说,该模型对 80% 的数据点做出了正确的预测。
这是一个足够常见的计算,sklearn 已经为我们实现了它。所以我们可以使用 score 方法得到相同的结果。score 方法使用该模型对 X 进行预测,并计算其中与 y 匹配的百分比。
print(model.score(X, y))| 6.1 完整代码
import pandas as pdfrom sklearn.linear_model import LogisticRegressiondf = pd.read_csv("titanic.csv")df['male'] = df['Sex'] == 'male'X = df[['Pclass', 'male', 'Age', 'Siblings/Spouses', 'Parents/Children', 'Fare']].valuesy = df['Survived'].valuesmodel = LogisticRegression()model.fit(X, y)# print(model.predict([[3, True, 22.0, 1, 0, 7.25]]))# print(model.predict(X[:5]))# print(y[:5])y_pred = model.predict(X)print((y == y_pred).sum())print((y == y_pred).sum() / y.shape[0])print(model.score(X, y))
当然,你也可以访问github存储库来下载代码:
https://github.com/Zesheng-Wang/Machine-Learning
References:
Hoss Belyadi, Alireza Haghighat, in Machine Learning Guide for Oil and Gas Using Python, 2021https://www.ibm.com/topics/logistic-regressionhttps://en.wikipedia.org/wiki/Logistic_regressionhttps://towardsdatascience.com/machine-learning-classifiershttps://www.statisticssolutions.com/free-resources/directory-of-statistical-analyses/what-is-logistic-regression/
| 7.1 写在最后
学习不是一蹴而就的,机器学习所涉及的内容非常宽泛,除了一些数学公式以外,我们也算站在巨人的肩膀上了。作为一种面向应用的方式方法,在不同的场景下同样有着不同的解决方式,希望今天的内容可以帮你了解什么是sklearn以及逻辑回归,从根本上理解机器学习,而不是做一个调包侠,希望可以帮你打下坚实的基础。
勘误:
由于我自己也不是资深编程高手,在创作此内容时尽管已经力求精准,查阅了诸多资料,还是难保有所疏漏,如果各位发现有误可以公众号内留言,欢迎指正。
你要偷偷学Python,然后惊艳所有人。


-END-
感谢大家的关注
你关心的,都在这里