机器学习中 常见问题汇总(一)
深度学习框架TensorFlow中都有哪些优化方法?
梯度下降算法针对凸优化问题原则上是可以收敛到全局最优的,因为此时只有唯一的局部最优点。而实际上深度学习模型是一个复杂的非线性结构,一般属于非凸问题,这意味着存在很多局部最优点(鞍点),采用梯度下降算法可能会陷入局部最优,这应该是最头疼的问题。这点和进化算法如遗传算法很类似,都无法保证收敛到全局最优。因此,我们注定在这个问题上成为“高级炼丹师”。可以看到,梯度下降算法中一个重要的参数是学习速率,适当的学习速率很重要:学习速率过小时收敛速度慢,而过大时导致训练震荡,而且可能会发散。理想的梯度下降算法要满足两点:收敛速度要快;能全局收敛。为了这个理想,出现了很多经典梯度下降算法的变种,下面将分别介绍它们。
SGD
梯度下降算法(Gradient Descent Optimization)是神经网络模型训练最常用的优化算法。梯度下降算法背后的原理:目标函数J(θ)关于参数θ的梯度将是目标函数上升最快的方向,对于最小化优化问题,只需要将参数沿着梯度相反的方向前进一个步长(学习速率),就可以实现目标函数的下降。参数更新公式如下:
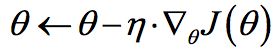
其中是参数的梯度。
根据计算目标函数J(θ)采用数据量的大小,梯度下降算法又可以分为批量梯度下降算法(Batch Gradient Descent),随机梯度下降算法(Stochastic GradientDescent)和小批量梯度下降算法(Mini-batch Gradient Descent)。
- 批量梯度下降算法,J(θ)是在整个训练集上计算的,如果数据集比较大,可能会面临内存不足问题,而且其收敛速度一般比较慢。
- 随机梯度下降算法,J(θ)是针对训练集中的一个训练样本计算的,又称为在线学习,即得到了一个样本,就可以执行一次参数更新。所以其收敛速度会快一些,但是有可能出现目标函数值震荡现象,因为高频率的参数更新导致了高方差。
- 小批量梯度下降算法,是折中方案,J(θ)选取训练集中一个小批量样本计算,这样可以保证训练过程更稳定,而且采用批量训练方法也可以利用矩阵计算的优势。这是目前最常用的梯度下降算法。
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss)momentum
SGD方法的一个缺点是,其更新方向完全依赖于当前的batch,因而其更新十分不稳定,每次迭代计算的梯度含有比较大的噪音。解决这一问题的一个简单的做法便是引入momentum,momentum即动量,是BorisPolyak在1964年提出的,其基于物体运动时的惯性:将一个小球从山顶滚下,其初始速率很慢,但在加速度作用下速率很快增加,并最终由于阻力的存在达到一个稳定速率,即更新的时候在一定程度上保留之前更新的方向,同时利用 当前batch的梯度 微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力。
其更新方程如下:
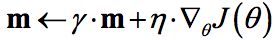
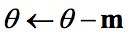
可以看到,参数更新时不仅考虑当前梯度值,而且加上了一个动量项γm,但多了一个超参γ,通常γ设置为0.5,直到初始学习稳定,然后增加到0.9或更高。相比原始梯度下降算法,动量梯度下降算法有助于加速收敛。当梯度与动量方向一致时,动量项会增加,而相反时,动量项减少,因此动量梯度下降算法可以减少训练的震荡过程。
tf.train.MomentumOptimizer(learning_rate=learning_rate,momentum=0.9)NAG
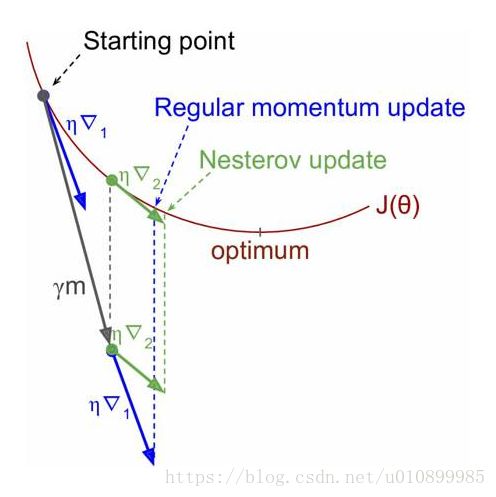
NAG(Nesterov Accelerated Gradient),,由Ilya Sutskever(2012 unpublished)在Nesterov工作的启发下提出的。对动量梯度下降算法的改进版本,其速度更快。其变化之处在于计算“超前梯度”更新动量项 γm,具体公式如下:
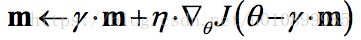
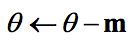
既然参数要沿着动量项 γm更新,不妨计算未来位置(θ -γm)的梯度,然后合并两项作为最终的更新项,其具体效果如图1所示,可以看到一定的加速效果。
momentum基础上设置 use_nesterov=True
tf.train.MomentumOptimizer(learning_rate=learning_rate,momentum=0.9, use_nesterov=True)AdaGrad
AdaGrad是Duchi在2011年提出的一种学习速率自适应的梯度下降算法。在训练迭代过程,其学习速率是逐渐衰减的,经常更新的参数其学习速率衰减更快,这是一种自适应算法。其更新过程如下:
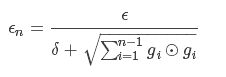
每步迭代过程:
- 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
- 计算梯度和误差,更新r,再根据r和梯度计算参数更新量:
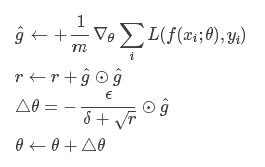
其中,全局学习速率 ϵ, 初始参数 θ,梯度平方的累计量r初始化为0), δ(通常为10^−7)是为了防止分母的为 0。
由于梯度平方的累计量r逐渐增加的,那么学习速率是衰减的。考虑下图所示的情况,目标函数在两个方向的坡度不一样,如果是原始的梯度下降算法,在接近坡底时收敛速度比较慢。而当采用AdaGrad,这种情况可以被改善。由于比较陡的方向梯度比较大,其学习速率将衰减得更快,这有利于参数沿着更接近坡底的方向移动,从而加速收敛。对于每个参数,随着其更新的总距离增多,其学习速率也随之变慢。
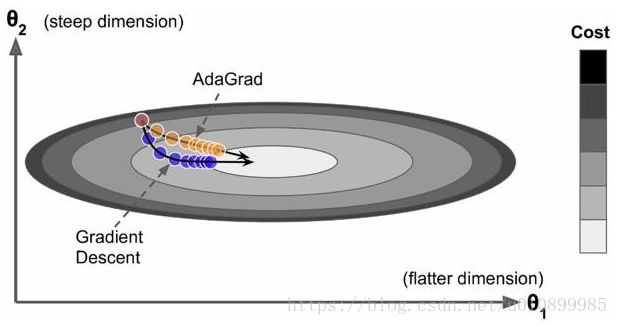
缺点: 任然要设置一个变量ϵ ,经验表明,在普通算法中也许效果不错,但在深度学习中,深度过深时会造成训练提前结束。
tf.train.AdagradOptimizer(learning_rate=0.001).minimize(loss)Adadelta
Adadelta是对Adagrad的扩展,最初方案依然是对学习率进行自适应约束,但是进行了计算上的简化。
Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值。即:
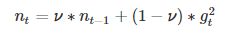
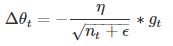
其中,η是学习率,gt 是梯度
在此处Adadelta其实还是依赖于全局学习率的,但是作者做了一定处理,经过近似牛顿迭代法之后:
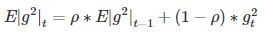
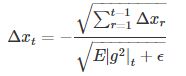
其中,E代表求期望。此时,可以看出Adadelta已经不用依赖于全局学习率了。
tf.train.AdadeltaOptimizer(learning_rate=0.001).minimize(loss)RMSProp
RMSprop是对Adagrad算法的改进,主要是解决。其实思路很简单,类似Momentum思想,引入一个衰减系数,让梯度平方的累计量r 每回合都衰减一定比例:

其中,衰减系数ρ
decay: 衰减率
epsilon: 设置较小的值,防止分母的为 0.
tf.train.RMSPropOptimizer(learning_rate=0.001,momentum=0.9, decay=0.9, epsilon=1e-10)优点:
- 相比于AdaGrad,这种方法有效减少了出现梯度爆炸情况,因此避免了学习速率过快衰减的问题。
- 适合处理非平稳目标,对于RNN效果很好
缺点:
- 又引入了新的超参—衰减系数ρ
- 依然依赖于全局学习速率,
总结:RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间。
Adam
自适应矩估计(daptive moment estimation,Adam),是Kingma等在2015年提出的一种新的优化算法,本质上是带有动量项的RMSprop,其结合了Momentum和RMSprop算法的思想。它利用梯度的一阶矩估计 和 二阶矩估计 动态调整每个参数的学习率。
具体实现每步迭代过程:
- 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
- 计算梯度和误差,更新r和s,再根据r和s以及梯度计算参数更新量 :

其中,一阶动量s,二阶动量r(初始化为0),一阶动量衰减系数ρ1, 二阶动量衰减系数ρ2
超参数的建议值是ρ1=0.9,ρ2 =0.999,epsilon: 设置较小的值,防止分母的为 0。

实践
各种优化方法在CIFAR-10图像识别上比较:
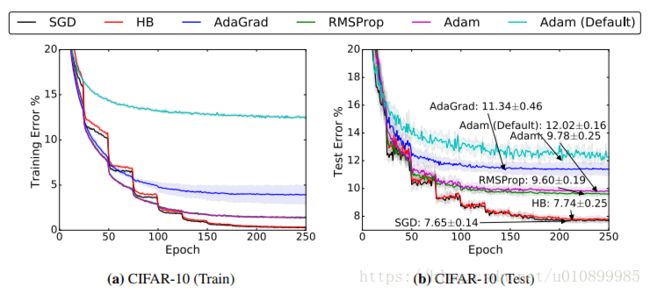
图片来源:The Marginal Value of Adaptive Gradient Methods in Machine Learning
- 自适应优化算法在训练前期阶段在训练集上收敛的更快,但是在测试集上反而并不理想。
- 用相同数量的超参数来调参,SGD和SGD +momentum 方法性能在测试集上的额误差好于所有的自适应优化算法,尽管有时自适应优化算法在训练集上的loss更小,但是他们在测试集上的loss却依然比SGD方法高,
总结:
- 对于稀疏数据,优先选择学习速率自适应的算法如RMSprop和Adam算法,而且最好采用默认值,大部分情况下其效果是较好的
- SGD通常训练时间更长,容易陷入鞍点,但是在好的初始化和学习率调度方案的情况下,结果更可靠。
- 如果要求更快的收敛,并且较深较复杂的网络时,推荐使用学习率自适应的优化方法。例如对于RNN之类的网络结构,Adam速度快,效果好,而对于CNN之类的网络结构,SGD +momentum 的更新方法要更好(常见国际顶尖期刊常见优化方法).
- Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
- 在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果。
- 特别注意学习速率的问题。学习速率设置得非常大,那么训练可能不会收敛,就直接发散了;如果设置的比较小,虽然可以收敛,但是训练时间可能无法接受。理想的学习速率是:刚开始设置较大,有很快的收敛速度,然后慢慢衰减,保证稳定到达最优
- 其实还有很多方面会影响梯度下降算法,如梯度的消失与爆炸,梯度下降算法目前无法保证全局收敛还将是一个持续性的数学难题
转:https://blog.csdn.net/u010899985/article/details/81836299