单细胞基础分析 | 对细胞按照基因marker进行分型(ACC脑区)
因项目的需求,需要对数据进行简单的分类,然后找差异表达基因。
虽然我自知自己在这个过程中的很多方面并不理解透彻,很糊涂的去做。但是我愿意去尝试完成。
现在开始跟着Seurat上面的教程一点点的来做。
参考链接:https://satijalab.org/seurat/articles/pbmc3k_tutorial.html
1、加载分析必须的包
library(Seurat)
library(dplyr)
library(patchwork)
2、加载10XGenomics 数据
data<-CreateSeuratObject(Read10X("./"),"ACC")
 关于这一部分10X Genomics数据的下载链接为:GSE127774
关于这一部分10X Genomics数据的下载链接为:GSE127774
数据特征:
> data
An object of class Seurat
32893 features across 21546 samples within 1 assay
Active assay: RNA (32893 features, 0 variable features)
#总结一下:该数据集中一共有21546个细胞,每个细胞中可以检测32893个基因
3、数据质量核查以及数据预处理
data[["percent.mt"]] <- PercentageFeatureSet(data,pattern = "^MT-") #看线粒体的含量
VlnPlot(data, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"), ncol = 3) #看每个细胞这些指标的相对情况
 为什么要统计这几个指标?有何含义?
为什么要统计这几个指标?有何含义?
我们知道,我们一般采样的是细胞中RNA,RNA的话有两个衡量的水平,首先是RNA的种类,其次是RNA的总量。一种RNA在细胞中可能对应有多个表达值(且由于10X Genomics是根据UMI进行计数的,因此不存在PCR冗余的情况)。
而这里和其他分析不太一样的是,还统计了线粒体基因的含量。为什么要考虑线粒体的含量呢?是这样的。因为一般情况下,我们进行的是核测序(当然也有全细胞测序),线粒体基因是位于细胞质中的,如果该细胞中检测到的线粒体基因高于特定的阈值,则很有可能是该细胞在实验操作的过程中破裂(关于实验的细节还是应该再看看,如果是进行了核测序,那么究竟是怎样测序呢?)。
当然RNA总量也并非越多越好,因为多得话,可能是双核。
- nFeature_RNA:测到的基因的数量
- nCount_RNA:测到的细胞内整体的RNA的总量
- percent.mt:线粒体的比例
plot1 <- FeatureScatter(data, feature1 = "nCount_RNA", feature2 = "percent.mt")
plot2 <- FeatureScatter(data, feature1 = "nCount_RNA", feature2 = "nFeature_RNA")
plot1 + plot2

从上面那张图中,我们可以看到一些细胞中总体的RNA的值很低,但是线粒体基因的比例很高,这就暗示这些细胞可能是破碎的细胞。
min(data$nCount_RNA)
[1] 203
mean(data$nCount_RNA)
[1] 910.5498
min(data$nFeature_RNA)
[1] 155
mean(data$nFeature_RNA)
[1] 663.5555
max(data$percent.mt)
[1] 19.66102
刚刚出现了一些突发的状况。输入法突然输入不了拼音了。换了科大讯飞的产品,那顺滑和简洁的程度太棒了。我喜欢!
data <- subset(data, subset = nFeature_RNA > 500 & nFeature_RNA < 2500 & percent.mt < 5)
当然你觉得不筛也行。最后筛到差不多10000个细胞左右。
> data
An object of class Seurat
32893 features across 11124 samples within 1 assay
Active assay: RNA (32893 features, 0 variable features)
4、标准化
data <- NormalizeData(data)
用默认的方法,对数据进行标准化,使得细胞之间可以相互比较。关于标准化的方法以及参数设置有很多,这里采用默认的参数进行操作(具体的标准化咱一会儿系统的来研究它)。
5、特征选择——寻找高变基因
data <- FindVariableFeatures(data, selection.method = "vst", nfeatures = 2000) #这里就是计算方差最大的那个基因
top10 <- head(VariableFeatures(data), 10)
plot1 <- VariableFeaturePlot(data)
plot2 <- LabelPoints(plot = plot1, points = top10, repel = TRUE)
plot2

6、在线性降维之前进行scale
data <- ScaleData(data, features = all.genes,vars.to.regress = "percent.mt")
在scale的时候忽略线粒体基因(似乎重新做一遍scale,变慢)。
7、使用PCA进行线性降维,确定最后用多少维聚类
data <- RunPCA(data, features = VariableFeatures(object = data))
data <- JackStraw(data, num.replicate = 100)
data <- ScoreJackStraw(data, dims = 1:40)
JackStrawPlot(data, dims = 1:15)
ElbowPlot(data)

这张图就很像咱们做WGCNA的时候,判断那个软阈值很像。在第16个值之后,它下降的速度就不那么明显了。所以,选择前16维,进行聚类分析。
8、umap聚类分析
data <- FindNeighbors(data, dims = 1:16)
data <- FindClusters(data, resolution = 0.2) #选择合适的分辨率 分辨率越大,聚类数越多
data <- RunUMAP(data, dims = 1:16)
DimPlot(data, reduction = "umap")

这个分类数我还挺满意的。接下来就想对这些levels进行注释。根据特定基因的表达模式。
9、细胞类型注释分析
我们已知一些基因是某些细胞类型的标记基因。先看一下这些基因的表达模式,再和相应的cluster对应起来。
 记录一下初学者卑微的探索过程。
记录一下初学者卑微的探索过程。
对于不同的数据,想要对细胞类型定性,实在是太难了。
最后屈服于现实,乖乖按照原始数据集文章中的分类marker进行细胞类型注释吧。
#astrocytes
VlnPlot(data,features = c("GJA1"), slot = "counts",log = TRUE) #3
#inhibitory neurons
VlnPlot(data,features = c("GAD1","GAD2"), slot = "counts",log = TRUE) #4
#excitatory neurons
VlnPlot(data,features = c("SLC17A7","SATB2","LMO7","PCP4","PCDH8"), slot = "counts", log = TRUE) #这个范围比较广
#oligodendrocyte precursor cells
VlnPlot(data,features = c("PDGFRA","CSPG4"), slot = "counts",log = TRUE) #
#oligodendrocytes OD
VlnPlot(data,features = c("MBP","MOBP","MOG"), slot = "counts", log = TRUE) #
#endothelial vascular cells VEC
VlnPlot(data,features = c("A2M"), slot = "counts", log = TRUE) #5
#microglia MG
VlnPlot(data,features = c("AIF1","AIF1","CX3CR1","PTPRC","HLA−DRA"), slot = "counts", log = TRUE)
#Cajal-Retzius CR
VlnPlot(data,features = c("RELN"), slot = "counts", log = TRUE)
#spindle neurons Sn
VlnPlot(data,features = c("TAC1","PCDH8","DRD2","ADORA2A","PENK"),slot = "counts", log = TRUE)
#granular cells
VlnPlot(data,features = c("TIAM1"),slot = "counts", log = TRUE)
#Purkinje cells Pur
VlnPlot(data,features = c("PCP4","NECAB2","LMO7","CALB1"),slot = "counts", log = TRUE)
这点是取自文章中的建议的marker。具体如下:
参考链接:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7263190/
 但是,结果并不是特别的理想。有些marker并没有仅在特定的cluster中表达。
但是,结果并不是特别的理想。有些marker并没有仅在特定的cluster中表达。
对于没有已知的marker表达的cluster,可以通过寻找差异表达基因,找基于咱们真实的数据的marker,然后再到网站:https://panglaodb.se/search.html 去查,该marker在其他数据集注释的细胞类型。
cluster.markers <- FindAllMarkers(data,logfc.threshold = 0.25, test.use = "roc",only.pos = TRUE)
head(cluster.markers)
write.csv(cluster.markers,"cluster.markers.csv")
但是后来试了一下,觉得毛病有很多。很多marker是某一簇的差异表达基因,但是这些marker在网站上却注释为不同的细胞类型;另外可能存在许多在我这边unknown的簇,属于同一个细胞类型。即使他们说同一细胞类型的亚型,也十分说不通。
在我看来,差异表达基因是相对的比较产生的结果。使用的background不同,得到的差异表达基因的结果也是不一样的。细胞类型可以分多一点,可以分少一点,都没有绝对一说。
还有点循环论证的感觉:用我定义的细胞类型的差异表达基因去映射基因簇的富集情况。
故而,如果要使用这个方法的话,就要足够灵巧和聪明,怎样规避模棱两可的情况。
10、细胞类型再注释
经过上述的反思,我觉得就把细胞分为两类:神经元、非神经元。然后去看,我们感兴趣的基因在两者间的富集情况,适当的使用一些统计分析的方法。
目前根据一些神经元的marker,按照全或无的规则,去看哪些细胞簇中表达这些marker,但凡有的,就把他认定为是neuron。其余簇为非neuron,然后将两者进行定义和命名。
VlnPlot(data,features = c("NEFM","CAMK2N1","PNISR","SLC12A5","STMN2","MEG3","DYNC1I1"),slot = "counts", log = TRUE) #神经元的marker
 将其按照上述的定义,将cluster进行重新的命名。
将其按照上述的定义,将cluster进行重新的命名。
levels(data)
new.cluster.ids <- c("Neuron", "Neuron", "Neuron", "no-Neuron", "Neuron", "Neuron","Neuron","no-Neuron","Neuron",
"no-Neuron", "no-Neuron", "Neuron","Neuron","Neuron","Neuron","Neuron","Neuron"
)
names(new.cluster.ids) <- levels(data)
data<- RenameIdents(data, new.cluster.ids)
然后,用之前已知的在神经元以及非神经元细胞中的marker进行验证。
#excitatory neurons
VlnPlot(data,features = c("SLC17A7","SATB2","LMO7","PCP4","PCDH8"), slot = "counts", log = TRUE) #这个范围比较广
#oligodendrocytes OD
VlnPlot(data,features = c("MBP","MOBP","MOG"), slot = "counts", log = TRUE)

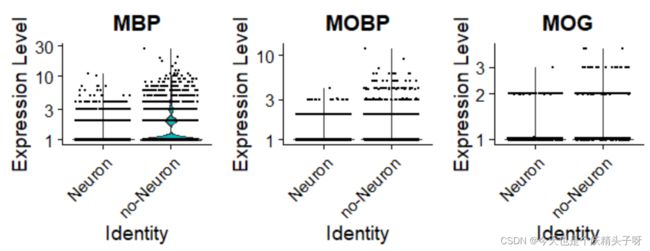 从以上两张图,可以明显的看到不同。因此,这给我一种确信就是我这样做啥有意义的。
从以上两张图,可以明显的看到不同。因此,这给我一种确信就是我这样做啥有意义的。
11、差异表达分析
重复之前的操作:
cluster.markers2 <- FindAllMarkers(data,logfc.threshold = 0.25, test.use = "roc",only.pos = TRUE)
head(cluster.markers2)
write.csv(cluster.markers2,"cluster.markers2.csv")
但是发现之前已经验证过的一个基因A2M不在里面。于是,就放宽了阈值条件。
cluster.markers5<- FindAllMarkers(data,logfc.threshold = 0.1,min.pct=0.01,test.use = "wilcox",only.pos = TRUE)
head(cluster.markers5)
dim(cluster.markers5)
write.csv(cluster.markers5,"cluster.markers5.csv")
cluster.markers6<-subset(cluster.markers5,p_val_adj<=0.05)
dim(cluster.markers6)
write.csv(cluster.markers6,"cluster.markers6.csv")
终于在结果中找到了A2M了。
筛选完成之后一共是4989个基因的输出结果。
虽然,对这些结果,我仍旧是保持怀疑。我想多用几个数据集,然后取他们之间的overlap。是比较确信的去除数据集特征之后的,非神经元以及神经元之间特异性的biomarker。
将其另存为,cluster.markers_ACC.csv。
接下来分别处理其他脑区的数据。必要的话,把咱们的数据也按照“神经元-非神经元”进行分类,找到这些数据所共有的markers。然后再根据这些数据所共有的特征进行整合。只有这样才能确保是正确的markers。
(完)