xgboost简单介绍_XGBOOST模型介绍
描述
前言
这是机器学习系列的第三篇文章,对于住房租金预测比赛的总结这将是最后一篇文章了,比赛持续一个月自己的总结竟然也用了一个月,牵强一点来说机器学习也将会是一个漫长的道路,后续机器学习的文章大多数以知识科普为主,毕竟自己在机器学习这个领域是个渣渣,自己学到的新知识点会分享给大家的。
前面的文章谈了谈这次比赛非技术方面的收获,对数据集的初步了解和特征工程的处理,今天主要介绍这次使用的模型--XGBOOST。

XGBOOST模型介绍
关于xgboost的原理网络上的资源很少,大多数还停留在应用层面,自己也是仅仅学习了一点应用,关于原理可以参考陈天奇博士的这篇文章
https://xgboost.readthedocs.io/en/latest/tutorials/model.html。
简单介绍:
XGBOOST是一个监督模型,xgboost对应的模型本质是一堆CART树。用一堆树做预测,就是将每棵树的预测值加到一起作为最终的预测值。下图就是CART树和一堆CART树的示例,用来判断一个人是否会喜欢计算机游戏:
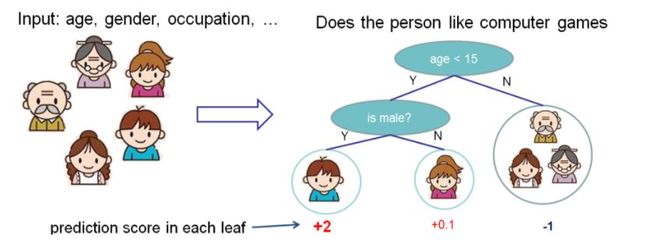

第二张图明了如何用一堆CART树做预测,就是简单将各个树的预测分数相加。
参数介绍:
官方参数介绍看这里: https://xgboost.readthedocs.io/en/latest/parameter.html#general-parameters
比较重要的参数介绍:
“reg:linear” –线性回归。 “reg:logistic” –逻辑回归。 “binary:logistic” –二分类的逻辑回归问题,输出为概率。 “binary:logitraw” –二分类的逻辑回归问题,输出的结果为wTx。
“count:poisson”–计数问题的poisson回归,输出结果为poisson分布。在poisson回归中,max_delta_step的缺省值为0.7。(used to safeguard optimization)
“multi:softmax”–让XGBoost采用softmax目标函数处理多分类问题,同时需要设置参数num_class(类别个数)
“multi:softprob” –和softmax一样,但是输出的是ndata * nclass的向量,可以将该向量reshape成ndata行nclass列的矩阵。没行数据表示样本所属于每个类别的概率。
lambda [default=0] L2 正则的惩罚系数alpha [default=0] L1 正则的惩罚系数
lambda_bias 在偏置上的L2正则。缺省值为0(在L1上没有偏置项的正则,因为L1时偏置不重要)
eta [default=0.3] 为了防止过拟合,更新过程中用到的收缩步长。在每次提升计算之后,算法会直接获得新特征的权重。eta通过缩减特征的权重使提升计算过程更加保守。取值范围为:[0,1]
max_depth[default=6]数的最大深度。缺省值为6,取值范围为:[1,∞]
min_child_weight [default=1] 孩子节点中最小的样本权重和。如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束。在现行回归模型中,这个参数是指建立每个模型所需要的最小样本数。该成熟越大算法越conservative 取值范围为: [0,∞]
xgboost参数设置的代码示例:
1xgboost参数设置代码示例: 2 3# 划分数据集 4X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.01, random_state=1729) 5print(X_train.shape, X_test.shape) 6 7#模型参数设置 8xlf = xgb.XGBRegressor(max_depth=10, 9 learning_rate=0.1, 10 n_estimators=10, 11 silent=True, 12 objective='reg:linear', 13 nthread=-1, 14 gamma=0,15 min_child_weight=1, 16 max_delta_step=0, 17 subsample=0.85, 18 colsample_bytree=0.7, 19 colsample_bylevel=1, 20 reg_alpha=0, 21 reg_lambda=1, 22 scale_pos_weight=1, 23 seed=1440, 24 missing=None)2526xlf.fit(X_train, y_train, eval_metric='rmse', verbose = True, eval_set = [(X_test, y_test)],early_stopping_rounds=100)2728# 计算 分数、预测29preds = xlf.predict(X_test)
比赛代码
关于xgboost只是简单的做了一个介绍,自己也仅仅懂一点应用层,原理懂得不是很多,这次XGB代码分析使用的是第一名开源代码。
导入数据集
1import pandas as pd 2import numpy as np 3import matplotlib.pyplot as plt 4 5train_data=pd.read_csv('train.csv') 6test_df=pd.read_csv('test.csv') 7train_df=train_data[train_data.loc[:,'Time']<3] 8val_df=train_data[train_data.loc[:,'Time']==3] 910del train_data
以默认参数的XGB分数为准,低于此基准线2.554的模型一律不考虑。
1def xgb_eval(train_df,val_df): 2 train_df=train_df.copy() 3 val_df=val_df.copy() 4 5 try: 6 from sklearn.preprocessing import LabelEncoder 7 lb_encoder=LabelEncoder() 8 lb_encoder.fit(train_df.loc[:,'RoomDir'].append(val_df.loc[:,'RoomDir'])) 9 train_df.loc[:,'RoomDir']=lb_encoder.transform(train_df.loc[:,'RoomDir'])10 val_df.loc[:,'RoomDir']=lb_encoder.transform(val_df.loc[:,'RoomDir'])11 except Exception as e:12 print(e)1314 import xgboost as xgb15 X_train=train_df.drop(['Rental'],axis=1)16 Y_train=train_df.loc[:,'Rental'].values17 X_val=val_df.drop(['Rental'],axis=1)18 Y_val=val_df.loc[:,'Rental'].values1920 from sklearn.metrics import mean_squared_error2122 try:23 eval_df=val_df.copy().drop('Time',axis=1)24 except Exception as e:25 eval_df=val_df.copy()2627 reg_model=xgb.XGBRegressor(max_depth=5,n_estimators=500,n_jobs=-1)28 reg_model.fit(X_train,Y_train)2930 y_pred=reg_model.predict(X_val)31 print(np.sqrt(mean_squared_error(Y_val,y_pred)),end=' ')3233 eval_df.loc[:,'Y_pred']=y_pred34 eval_df.loc[:,'RE']=eval_df.loc[:,'Y_pred']-eval_df.loc[:,'Rental']3536 print('')37 feature=X_train.columns38 fe_im=reg_model.feature_importances_39 print(pd.DataFrame({'fe':feature,'im':fe_im}).sort_values(by='im',ascending=False))4041 import matplotlib.pyplot as plt42 plt.clf()43 plt.figure(figsize=(15,4))44 plt.plot([Y_train.min(),Y_train.max()],[0,0],color='red')45 plt.scatter(x=eval_df.loc[:,'Rental'],y=eval_df.loc[:,'RE'])46 plt.show()4748 return eval_df
原生特征的丢弃尝试
以XGB做原生特征筛选,在原生特征中丢弃后不影响分数甚至涨分的特征有:Time,RentRoom(涨幅明显),RoomDir,Livingroom,RentType(涨幅明显),SubwayLine(涨幅明显),SubwayDis(涨幅明显)。
1# 丢弃各特征后的分数 2# ‘Time':2.558,'Neighborhood':2.592,'RentRoom':2.531,'Height':2.57,'TolHeight':2.591,'RoomArea':3 3# 'RoomDir':2.548,'RentStatus':2.561,'Bedroom':2.584,'Livingroom':2.548,'Bathroom':2.590,'RentType':2.538 4# 'Region':2.583,'BusLoc':2.594,'SubwayLine':2.521,'SubwaySta':2.569,'SubwayDis':2.537,'RemodCond':2.571 5for col in train_df.columns: 6 if col!='Rental': 7 print('drop col:{}'.format(col)) 8 tmp_train_df=train_df.drop([col],axis=1) 9 tmp_val_df=val_df.drop([col],axis=1)10 eval_df=xgb_eval(train_df=tmp_train_df,val_df=tmp_val_df)1112# 一起丢弃:2.55313tmp_train_df=train_df.copy()14tmp_val_df=val_df.copy()15tmp_train_df.drop(['Time','RentRoom','RoomDir','Livingroom','RentType','SubwayLine','SubwayDis'],axis=1,inplace=True)16tmp_val_df.drop(['Time','RentRoom','RoomDir','Livingroom','RentType','SubwayLine','SubwayDis'],axis=1,inplace=True)17eval_df=xgb_eval(train_df=tmp_train_df,val_df=tmp_val_df)
特征选择
一股脑加上所有特征表现不佳,使用贪心策略(前向选择、后向选择)逐个添加特征。
1train_data=pd.read_csv('train.csv') 2train_df=train_data[train_data.loc[:,'Time']<3] 3val_df=train_data[train_data.loc[:,'Time']==3] 4 5drop_cols=['SubwayLine','RentRoom','Time'] # 需要丢弃的原生特征 6 7comb_train_df=train_df.copy() 8comb_val_df=val_df.copy() 910# 前向特征选择这块我是用for循环暴力搜出来的最优特征组合,最终筛选出来的特征组合为:11# ['ab_Height','TolRooms','Area/Room','BusLoc_rank','SubwayLine_rank']1213comb_train_df.loc[:,'ab_Height']=comb_train_df.loc[:,'Height']/(comb_train_df.loc[:,'TolHeight']+1)14comb_val_df.loc[:,'ab_Height']=comb_val_df.loc[:,'Height']/(comb_val_df.loc[:,'TolHeight']+1)1516comb_train_df.loc[:,'TolRooms']=comb_train_df.loc[:,'Livingroom']+comb_train_df.loc[:,'Bedroom']+comb_train_df.loc[:,'Bathroom']17comb_val_df.loc[:,'TolRooms']=comb_val_df.loc[:,'Livingroom']+comb_val_df.loc[:,'Bedroom']+comb_val_df.loc[:,'Bathroom']18comb_train_df.loc[:,'Area/Room']=comb_train_df.loc[:,'RoomArea']/(comb_train_df.loc[:,'TolRooms']+1)19comb_val_df.loc[:,'Area/Room']=comb_val_df.loc[:,'RoomArea']/(comb_val_df.loc[:,'TolRooms']+1)2021rank_cols=['BusLoc','SubwayLine']22for col in rank_cols:23 rank_df=train_df.loc[:,[col,'Rental']].groupby(col,as_index=False).mean().sort_values(by='Rental').reset_index(drop=True)24 rank_df.loc[:,col+'_rank']=rank_df.index+1 # +1,为缺失值预留一个0值的rank25 rank_fe_df=rank_df.drop(['Rental'],axis=1)26 comb_train_df=comb_train_df.merge(rank_fe_df,how='left',on=col)27 comb_val_df=comb_val_df.merge(rank_fe_df,how='left',on=col)28 try:29 comb_train_df.drop([col],axis=1,inplace=True)30 comb_val_df.drop([col],axis=1,inplace=True)31 except Exception as e:32 print(e)33for drop_col in drop_cols:34 try:35 comb_train_df.drop(drop_col,axis=1,inplace=True)36 comb_val_df.drop(drop_col,axis=1,inplace=True)37 except Exception as e:38 pass3940# 贪心策略添加特征,目前为:2.40341eval_df=xgb_eval(train_df=comb_train_df,val_df=comb_val_df
调参对于不是很大的数据集可以用sklearn的Gridcvsearch来暴力调参。示例代码:
1params = {'depth':[3],2 'iterations':[5000],3 'learning_rate':[0.1,0.2,0.3],4 'l2_leaf_reg':[3,1,5,10,100],5 'border_count':[32,5,10,20,50,100,200]}6clf = GridSearchCV(cat, params, cv=3)7clf.fit(x_train_2, y_train_2)
对于较大的数据集,用第一种方法耗时特别长。2. 逐个参数调,先取定其它参数,遍历第一个参数,选择最优值,再调下一个参数。省时但有的时候容易陷入局部最优。3.观察数据的分布来调整对应的参数,如树模型的叶子节点数,变量较多,叶子数少欠拟合。
预测提交
1def xgb_pred(): 2 train_df=pd.read_csv('train.csv') 3 test_df=pd.read_csv('test.csv') 4 5 try: 6 from sklearn.preprocessing import LabelEncoder 7 lb_encoder=LabelEncoder() 8 lb_encoder.fit(train_df.loc[:,'RoomDir'].append(test_df.loc[:,'RoomDir'])) 9 train_df.loc[:,'RoomDir']=lb_encoder.transform(train_df.loc[:,'RoomDir'])10 test_df.loc[:,'RoomDir']=lb_encoder.transform(test_df.loc[:,'RoomDir'])11 except Exception as e:12 print(e)1314 train_df.loc[:,'ab_Height']=train_df.loc[:,'Height']/(train_df.loc[:,'TolHeight']+1)15 test_df.loc[:,'ab_Height']=test_df.loc[:,'Height']/(test_df.loc[:,'TolHeight']+1)16 train_df.loc[:,'TolRooms']=train_df.loc[:,'Livingroom']+train_df.loc[:,'Bedroom']+train_df.loc[:,'Bathroom']17 test_df.loc[:,'TolRooms']=test_df.loc[:,'Livingroom']+test_df.loc[:,'Bedroom']+test_df.loc[:,'Bathroom']18 train_df.loc[:,'Area/Room']=train_df.loc[:,'RoomArea']/(train_df.loc[:,'TolRooms']+1)19 test_df.loc[:,'Area/Room']=test_df.loc[:,'RoomArea']/(test_df.loc[:,'TolRooms']+1)2021 rank_cols=['BusLoc','SubwayLine']22 for col in rank_cols:23 rank_df=train_df.loc[:,[col,'Rental']].groupby(col,as_index=False).mean().sort_values(by='Rental').reset_index(drop=True)24 rank_df.loc[:,col+'_rank']=rank_df.index+1 # +1,为缺失值预留一个0值的rank25 rank_fe_df=rank_df.drop(['Rental'],axis=1)26 train_df=train_df.merge(rank_fe_df,how='left',on=col)27 test_df=test_df.merge(rank_fe_df,how='left',on=col)28 try:29 train_df.drop([col],axis=1,inplace=True)30 test_df.drop([col],axis=1,inplace=True)31 except Exception as e:32 print(e)33 for drop_col in drop_cols:34 try:35 train_df.drop(drop_col,axis=1,inplace=True)36 test_df.drop(drop_col,axis=1,inplace=True)37 except Exception as e:38 pass3940 print(train_df.columns,test_df.columns)4142 import xgboost as xgb43 X_train=train_df.drop(['Rental'],axis=1)44 Y_train=train_df.loc[:,'Rental'].values45 test_id=test_df.loc[:,'id']46 X_test=test_df.drop(['id'],axis=1)474849 from sklearn.metrics import mean_squared_error5051 reg_model=xgb.XGBRegressor(max_depth=8,n_estimators=1880,n_jobs=-1)52 reg_model.fit(X_train,Y_train,eval_set=[(X_train,Y_train)],verbose=100,early_stopping_rounds=10)5354 y_pred=reg_model.predict(X_test)5556 sub_df=pd.DataFrame({57 'id':test_id,58 'price':y_pred59 })60 sub_df.to_csv('sub.csv',index=False)6162 return None6364xgb_pred()
第一名XGB单模分数为1.94,线下线上是一致的,总特征数二十多个,跟自己的XGB相比,自己在特征组合方向有所欠缺,自己单模特征10个左右分数在2.01。
打开APP阅读更多精彩内容
点击阅读全文