机器学习入门之k近邻算法
前言:
博主在路过篮球场时,看到了迎面而来的篮球。当下心中有了一个疑惑,为何我知道它叫篮球,而机器不知道呢?于是今天的主题就是使用k近邻算法分辨几种常见的球类。
正文:
博主打算选取的球类主要是足球,篮球,排球。经过一番搜索和抉择,总结特性如下表,如有不符,那一定是为了做实验而进行的科学抽象,请各位看官莫要介意。
| 球类 属性 | 圆周长(cm) | 重量(g) | 表皮材料 | 纹路 |
| 篮球 | 75-76 | 600-650 | PU合成皮、PVC合成皮、黄牛面皮、橡胶 | 条纹状 |
| 足球 | 68.5-69.5 | 420-445 | PU合成皮、PVC合成皮 | 斑点状 |
| 排球 | 65-68 | 260-280 | PU合成皮、PVC合成皮、羊皮 | 条纹状 |
生成数据集:
特性已有,那么接下来的工作就是搞数据集了。这里我的想法是按照上边的特性随机生成一组数据集。下面附上代码:
import random as r
n_size = 100
l = []
z = []
p = []
fileName = 'data1'
with open(fileName, 'w', encoding='utf-8') as file:
# file.write('圆周长(cm)' + '\t')
# file.write('\t重量(g)' + '\t')
# file.write('\t材料' + '\t')
# file.write('\t纹路' + '\t')
# file.write('\t类别' + '\n')
for i in range(n_size):
a = r.uniform(75, 76)
l.append((str(a).split(".")[0] + "." + str(a).split(".")[1][:2]))
file.write(l[i] + '\t')
file.writelines('\t' + str(r.randint(600, 650)) + '\t')
file.writelines('\t' + r.choice(['PU合成皮', 'PVC合成皮', '黄牛面皮', '橡胶']) + '\t')
file.write('\t' + '条纹状' + '\t')
file.write('\t' + '篮球' + '\n')
for i in range(n_size):
a = r.uniform(68.5, 69.5)
z.append((str(a).split(".")[0] + "." + str(a).split(".")[1][:2]))
file.write(z[i] + '\t')
file.writelines('\t' + str(r.randint(420, 445)) + '\t')
file.writelines('\t' + r.choice(['PU合成皮', 'PVC合成皮']) + '\t')
file.write('\t' + '斑点状' + '\t')
file.write('\t' + '足球' + '\n')
for i in range(n_size):
a = r.uniform(65, 68)
p.append((str(a).split(".")[0] + "." + str(a).split(".")[1][:2]))
file.write(p[i] + '\t')
file.writelines('\t' + str(r.randint(260, 280)) + '\t')
file.writelines('\t' + r.choice(['PU合成皮', 'PVC合成皮', '羊皮']) + '\t')
file.write('\t' + '条纹状' + '\t')
file.write('\t' + '排球' + '\n')中间注释掉的部分也是实属无奈,保留就是给数据集加了一个表头,但后边进行数据导入的时候会出现一点问题,为了操作简单就将其去掉了。
代码看起来有点冗长,但其实本质上就是一个随机数循环,再将随机数写入文档。完成效果如下:
k近邻算法:
当数据集完成后,我们的工作就是分类了。也就是说,我们要如何根据已有的数据识别出这是个什么球?终于开始正题了,机器学习初始不搞那些花里胡哨的,我们从最基本的k近邻算法开始,慢慢回顾前人走过的路。
摆在我们面前的无非这么几个问题。什么是k近邻?算法思想如何?怎样去实现?
首先解释算法:
百度百科这样说:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
也有人这么说:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类。
大致上解释都差不多,用我的大白话来解释就是:从上边的数据里随便抽出一个,分别计算这个数据与其他所有数据的距离,拉出排在最前面的k个值亮相,哪个阵营人多它就跟谁混。
理论方法:
计算距离采用欧氏距离:
![]()
当然,其他的距离计算方法也都可以,可以自己了解选用。
实现:
没什么好说的了,直接上代码:
import numpy
import matplotlib
import matplotlib.pyplot as plt
def file2matrix(filename):
with open(filename, 'r', encoding='utf-8') as file:
arrayOLines = file.readlines() #列表型
numberOfLines = len(arrayOLines)
returnMat = numpy.zeros((numberOfLines, 2))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t\t')
returnMat[index, :] = listFromLine[0: 2]
classLabelVector.append(listFromLine[-1])
index += 1
return returnMat, classLabelVector
def show_file2matrix():
Mat, Labels = file2matrix(('./data1'))
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(Mat[:, 0], Mat[:, 1])
#前两位是输入的数据,第三位传入大小的参数,第四位传入颜色的参数
plt.show()
show_file2matrix()这一部分的代码主要是进行数据导入,并显示其分布情况。分布如下图:
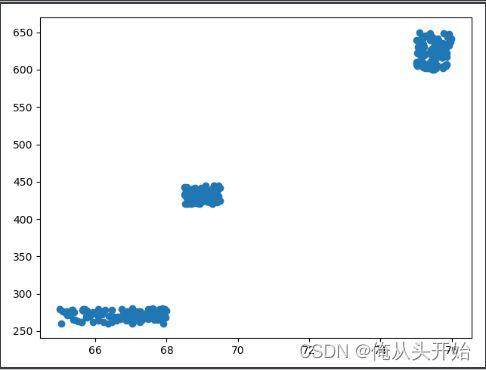
这样看来,我们的任务可能会很简单了,毕竟相似数据已经抱团。
下面附上完整的实现代码:
from numpy import *
import operator
# 训练样本集以及对应的类别
def createDateSet():
group = array([[3, 104], [2, 100], [1, 81], [101, 10], [99, 5], [98, 2]])
labels = ['Love', 'Love', 'Love', 'Action', 'Action', 'Action']
return group, labels
def classify(inX, dataSet, labels, k):
# dataSetSize是训练样本集数量
dataSetSize = dataSet.shape[0]
# 距离计算——欧式距离公式
# tile函数,把inX变成能与dataSet相减的二维数组
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
# axis=1是列相加求和,即得到(x1-x2)^2+(y1-y2)^2的值
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
# 按照距离递增次序排序,返回下标
sortedDistIndicies = distances.argsort()
# 选择距离最小的k个点
classCount = {}
for i in range(k):
voteILabel = labels[sortedDistIndicies[i]]
classCount[voteILabel] = classCount.get(voteILabel, 0) + 1
# 按照字典里的关键字的值排序,reverse=True降序排序
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回类别最多的标签
return sortedClassCount[0][0]
import numpy
import matplotlib
import matplotlib.pyplot as plt
def file2matrix(filename):
with open(filename, 'r', encoding='utf-8') as file:
arrayOLines = file.readlines() #列表型
numberOfLines = len(arrayOLines)
returnMat = numpy.zeros((numberOfLines, 2))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t\t')
returnMat[index, :] = listFromLine[0: 2]
classLabelVector.append(listFromLine[-1])
index += 1
return returnMat, classLabelVector
def show_file2matrix():
Mat, Labels = file2matrix(('./data1'))
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(Mat[:, 0], Mat[:, 1]) #输入坐标轴的x, y值
plt.show()
def autoNorm(dataSet):
'''
归一化模块
方程: newValue = (oldValue - min) / (max - min)
:param dataSet: 需要归一化的数据集
:return: 归一化后的数据集,最大值和最小值的差,最小值
'''
minVals = dataSet.min(0)
# print(minVals)#得到最小的那行数据
maxVals = dataSet.max(0)
# print(maxVals)#得到最大的那行数据
ranges = maxVals - minVals
# print(ranges)#取两个最大最小行的差值
normDataSet = zeros(dataSet.shape)#定义一个和dataSet一样大的零矩阵方便后面操作
m = dataSet.shape[0]#m为dataSet的形状,shape[0]指列值
normDataSet = dataSet - tile(minVals,(m,1))
normDataSet = normDataSet/tile(ranges,(m,1))
#numDataSet即为归一化之后的值
return normDataSet, ranges, minVals
def datingClassTest():
'''
测试模块
:return:
'''
hoRatio = 0.10
datingDataMat, datingLabels = file2matrix('./data1')
normMat, ranges, minVals = autoNorm(datingDataMat)
# normMat为归一化之后的值
m = normMat.shape[0]
# m为normMat的行数
numTestVecs = int(m*hoRatio)
# 0.10*行数,就是拿1/10的数据去测试
errorCount = 0.0
# 用于存储错误率
for i in range(numTestVecs):
classifierResult = classify(normMat[i,:], normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
#将除去测试数据集的数据集作为训练集合
print("The classifier cameback with: %s, the real answer is: %s"\
% (classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("the total error rate is: %f"%(errorCount/float(numTestVecs)))
def Input_Text():
hoRatin = 0.10
datingDataMat, datingLabels = file2matrix('./data1')
normMat, ranges, minVals = autoNorm(datingDataMat)
#normMat为归一化之后的值
m = normMat.shape[0]
#m为normMat的行数
numTestVecs = int(m*hoRatin)
#0.10*行数,就是拿1/10的数据去测试
errorCount = 0.0
#用于存储错误率
# print(normMat[1,:])
# for i in range(numTestVecs):
# print(normMat[i,:])
# print(normMat[numTestVecs:m,])
#normMat[numTestVecs:m,:] 将除去测试数据集的数据集作为训练集合
for i in range(10):
distance = float(input('distance?'))
play_time = float(input('play_time?'))
ice_cream = float(input('ice-cream?'))
aim = [distance,play_time,ice_cream]
normDataSet = zeros(1)
m = 1
normDataSet = aim - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges,(m,1))
# print(normDataSet)
#将输入归一化
Result = classify(aim,datingDataMat,datingLabels,3)
print(Result)
if __name__ == '__main__':
show_file2matrix()
autoNorm(file2matrix('./data1')[0])
print(file2matrix('./data1'))
datingClassTest()
Input_Text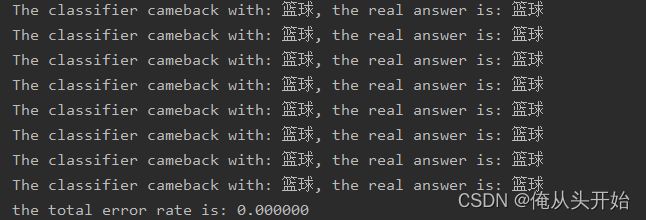
因为数据本身就差距较大的原因, 错误率直接归零,这倒是让我省去一番调参的时间。
今日份学习到这里就结束了,希望对各位看官有一点帮助。