【论文翻译】-- GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition
本文是复旦大学发表于 AAAI 2019 的工作。截至目前CASIA-B正确率最高的网络。
英文粘贴原文,google参与翻译但人工为主。有不对的地方欢迎评论。
粉色部分为本人理解添加,非原文内容。
目录
摘要
1.介绍
Flexible
灵活性
Fast
快速性
Effective
有效性
2. 相关工作
2.1 步态识别
2.2 无序序列的深度学习
3. GaitSet
3.1 问题表述
3.2 Set Pooling
Statistical Functions 统计函数
Joint Function 联合函数
Attention 注意力机制
3.3 Horizontal Pyramid Mapping
3.4 Multilayer Global Pipeline
3.5 训练和测试
训练损失函数
测试
4 实验
4.1 数据集和训练细节
CASIA-B
OU-MVLP
训练细节
4.2 主要结果
CASIA-B
Small-Sample Training (ST)
Medium-Sample Training (MT) & Large-Sample Training (LT)
OU-MVLP
4.3 AblationExperiments 消融实验
Set VS. GEI
Impact of SP
Impact of HPM and MGP
4.4 Practicality 实用性
Limited Silhouettes 有限轮廓数量
MultipleViews 多视角
Multiple Walking Conditions
5 结论
摘要
As a unique biometric feature that can be recognized at a distance, gait has broad applications in crime prevention, forensic identification and social security.
作为一种可以远距离识别的独特生物识别功能,步态在预防犯罪,法医鉴定和社会保障方面具有广泛的应用。
To portray a gait, existing gait recognition methods utilize either a gait template, where temporal information is hard to preserve, or a gait sequence, which must keep unnecessary sequential constraints and thus loses the flexibility of gait recognition.
为了描绘步态,现有的步态识别方法利用步态模板(其中时间信息难以保存)或步态序列,其必须保持不必要的顺序约束并因此失去步态识别的灵活性。
In this paper we present a novel perspective, where a gait is regarded as a set consisting of independent frames. We propose a new network named GaitSet to learn identity information from the set.
在本文中,我们提出了一种新颖的视角,其中步态被视为由独立帧组成的(图像)序列。我们提出了一个名为GaitSet的新网络来学习(图像)序列中的身份信息。
Based on the set perspective, our method is immune to permutation of frames, and can naturally integrate frames from different videos which have been filmed under different scenarios, such as diverse viewing angles, different clothes/carrying conditions.
基于(图像)序列视角,我们的方法不受帧的排列的影响,并且可以自然地整合来自不同视频的帧,这些视频已经在不同的场景下被完成,例如不同的视角,不同的衣服/携带条件。
Experiments show that under normal walking conditions, our single-model method achieves an average rank-1 accuracy of 95.0% on the CASIAB gait dataset and an 87.1% accuracy on the OU-MVLP gait dataset.
实验表明,在正常步行条件下,我们的单模型方法在CASIAB步态数据集上实现了平均95.0%的一次命中准确度,在OU-MVLP步态数据集上达到了87.1%的准确度。
These results represent new state-of-the-art recognition accuracy.
这些结果代表了新的最先进的识别准确度。
On various complex scenarios, our model exhibits a significant level of robustness. It achieves accuracies of 87.2% and 70.4% on CASIA-B underbag-carrying and coat-wearing walking conditions, respectively.
在各种复杂场景中,我们的模型具有显着的鲁棒性。它分别对携带CARA-Bunderbag和涂层的行走条件达到了87.2%和70.4%的准确率。
These outperform the existing best methods by a large margin.
这些都大大优于现有的最佳方法。
The method presented can also achieve a satisfactory accuracy with a small number of frames in a test sample, e.g., 82.5% on CASIAB with only 7 frames.
所提出的方法可以在小帧数测试样本中获得令人满意的正确率,例如在CASIAB上仅用7帧得到82.5%的正确率。
The source code has been released at https://github.com/AbnerHqC/GaitSet.
代码开源到网址:https://github.com/AbnerHqC/GaitSet。
1.介绍
Unlike other biometrics such as face, fingerprint and iris, gait is a unique biometric feature that can be recognized at a distance without the cooperation of subjects and intrusion to them.Therefore,it has broad applications in crime prevention, forensic identification and social security.
与脸部,指纹和虹膜等其他生物识别技术不同,步态是一种独特的生物特征,可以远距离识别,非侵入且无需受试者的合作。因此,它被广泛应用于犯罪防范、法医鉴定和社会保障。
However, gait recognition suffers from exterior factors such as the subject’s walking speed, dressing and carrying condition, and the camera’s viewpoint and frame rate.
然而,步态识别受到外部因素的影响,例如受试者的步行速度,穿着和携带状况,以及相机的视点和帧速率。
There are two main ways to identify gait in literature,i.e.,regarding gait as an image and regarding gait as a video sequence. The first category compresses all gait silhouettes into one image, or gait template for gait recognition.
在文献中识别步态有两种主要方式,即将步态视为图像和将步态视为视频序列。 第一类将所有步态轮廓压缩成一个图像,或用步态模板进行步态识别。"第一类典型代表典型代表GEI,如下图最后一列就是前几列图像的GEI,Gait Energy Image"
Simple and easy to implement, gait template easily loses temporal and fine-grained spatial information. Differently, the second category extracts features directly from the original gait silhouette sequences in recent years.
步态模板简单易行,但很容易丢失时间和细粒度的空间信息。不同的是,近几年第二类直接从原始步态轮廓序列中提取特征的算法更多。
However, these methods are vulnerable to exterior factors. Further, deep neural networks like3D-CNN for extracting sequential information are harder to train than those using a single template like Gait Energy Image.
但是,这些方法容易受到外部因素的影响。 此外,用于提取序列信息的深度神经网络如 3D-CNN 比使用像 GEI 这样的单个模板的深度神经网络更难训练。
To solve these problems, we present a novel perspective which regards gait as a set of gait silhouettes. As a periodic motion, gait can be represented by a single period.
为了解决这些问题,我们提出了一种新思路即将步态特征视为一组步态轮廓图。 作为周期性运动,步态可以由一个周期表示。
In a silhouette sequence containing one gait period, it was observed that the silhouette in each position has unique appearance, as shown in Fig. 1.
在包含一个步态周期的轮廓序列中,观察到每个位置的轮廓具有独特的外观,如图1所示。

图1:从左上角到右下角是CASIA-B步态数据集中的一个目标的完整周期轮廓。
Even if these silhouettes are shuffled, it is not difficult to rearrange them into correct order only by observing the appearance of them. Thus, we assume the appearance of a silhouette has contained its position information. With this assumption, order information of gait sequence is not necessary and we can directly regard gait as a set to extract temporal information.
即使这些轮廓是乱序的,但只有通过观察它们的外观就能将它们重新排列成正确的顺序。 因此,我们假设轮廓的外观包含其位置信息。 通过这种假设,步态序列的顺序信息不是必需的(输入特征),我们可以直接将步态视为一组(图像)来提取时间信息。
We propose an end-to-end deep learning model called GaitSet whose scheme is shown in Fig. 2.
我们提出了一种端到端的深度学校模型称作GaitSet,其框架图见图2。
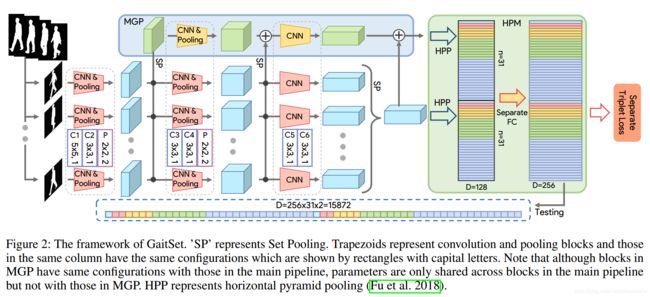
图2:GaitSet的框架。 'SP'代表Set Pooling。梯形表示卷积和池化块,同一列中的梯形具有相同的参数,这些参数由带有大写字母的矩形表示。请注意,尽管MGP中的块与主流水线中的块具有相同的参数,但其参数仅在主流水线中的块之间共享,而不与MGP中的块共享。HPP代表水平金字塔池化。
The input of our model is a set of gait silhouettes.
我们这个模型的输入是一组步态轮廓图像。(就像图1那种)
First, a CNN is used to extract frame-level features from each silhouette independently. Second, an operation called Set Pooling is used to aggregate frame-level features into a single set-level feature.
首先,CNN用于独立地从每个轮廓中提取帧级特征。 其次,名为Set Pooling的操作用于将帧级特征聚合成独立序列级特征。
Since this operation is applied on high-level feature maps instead of the original silhouettes, it can preserve spatialand temporal information better than gait template.This will be justified by the experiment in Sec. 4.3.
由于此操作应用于高级特征(原始轮廓卷积之后就变成高级特征了)而不是原始轮廓,因此它可以比步态模板更好地保留空间和时间信息。(其实我感觉这句话说的有点不太好理解,也可能是我理解能力有限,作者应该想表达的是:整个过程提取了每一帧图像的空间特征同时还提取了整个序列的时间特征,比步态模板的方式提取的特征更全面,侧重点应该在保留时间特征的同时提取了各帧特征)这部分的实验验证在Sec.4.3中详细介绍。
Third, a structure called Horizontal Pyramid Mapping is used to map the set-level feature into a more discriminative space to obtain the final representation.
第三,使用称为水平金字塔映射(Horizontal Pyramid Mapping,HPM)的结构将序列级特征映射到更具辨别力的空间以获得最终表示。(这句话的后半句说的很玄乎啊,主要discriminative这个词用的太好了,让人不明觉厉。我的理解就是把这个序列级特征,就是包含了时间和空间的特征压缩成一维特征便于最后全连接做分类。)
The superiorities of the proposed method are summarized as follows:
该方法的优越性总结如下:
Flexible
Our model is pretty flexible since there are no any constraints on the input of our model except the size of the silhouette. It means that the input set can contain any number of non-consecutive silhouettes filmed under different viewpoints with different walking conditions. Related experiments are shown in Sec. 4.4
灵活性
我们的模型非常灵活,因为除了轮廓的大小之外,我们模型的输入没有任何限制。 这意味着输入的序列可以包含在不同视点下具有不同行走条件的任意数量的非连续轮廓。 相关实验见Sec.4.4。(此处原文忘记写句号了我帮他们填上了哈哈哈)
Fast
Our model directly learns the representation of gait instead of measuring the similarity between a pair of gait templates or sequences. Thus, the representation of each sample needs to be calculated only once, then the recognition can be completed by calculating the Euclidean distance between representations of different samples.
快速性
我们的模型直接学习步态的表示,而不是测量一对步态模板或序列之间的相似性。 因此,每个样本的表示仅需要计算一次,然后可以通过计算不同样本的表示之间的欧式距离来完成识别。
Effective
Our model greatly improves the performance on the CASIA-B and the OUMVLP datasets, showing its strong robustness to view and walking condition variations and high generalization ability to large datasets.
有效性
我们的模型极大地提高了CASIA-B和OUMVLP数据集的性能,显示了其对视图和行走条件变化的强大鲁棒性以及对大型数据集的高泛化能力。
2. 相关工作
In this section, we will give a brief survey on gait recognition and set-based deep learning methods.
这部分我们会简要介绍步态识别和基于序列的深度学习方法的回顾。
2.1 步态识别
Gait recognition can be grouped into template-based and sequence-based categories.
步态识别可以分为基于模板和基于序列两种。
Approaches in the former category first obtain human silhouettes of each frame by background subtraction. Second, they generate a gait template by rendering pixel level operators on the aligned silhouettes.Third, they extract the representation of the gait by machine learning approaches such as Canonical Correlation Analysis(CCA), Linear Discriminant Analysis (LDA) and deep learning. Fourth, they measure the similarity between pairs of representations by Euclidean distance or some metric learning approaches. Finally, they assign a label to the template by some classifier, e.g., nearest neighbor classifier.
前一类中的方法首先通过背景减法获得每个帧的人体轮廓。第二步,将排列好的轮廓在帧级进行操作以生成步态模板。第三步,他们通过机器学习方法提取步态的表示,例如典型相关分析(CCA),线性判别分析(LDA)和深度学习。第四,它们通过欧几里德距离或一些度量学习方法来测量表示对(表示对就是输入的图像序列和训练过程中已经存储的一组图像序列)之间的相似性。最后,他们通过某些分类器,例如,最近邻居分类器,来为(输入的待检测)模板分配标签。
Previous works generally divides this pipeline into two parts, template generation and matching.
以前的工作通常将此流程分为两部分,模板生成和匹配。
The goal of generation is to compress gait information into a single image, e.g., Gait Energy Image (GEI) and Chrono-Gait Image (CGI).
(模板)生成的目标是将步态信息压缩成单个图像,例如步态能量图像(GEI)和计时步态图像(CGI)。
In template matching approaches, View Transformation Model (VTM) learns a projection between different views. (Hu et al. 2013) proposed View-invariant Discriminative Projection (ViDP) to project the templates into a latent space to learn a view-invariance representation.
在模板匹配方法中,视角转换模型(VTM)学习不同视图之间的投影。 (Hu et al.2013)提出了视角不变判别投影(ViDP)将模板投影到潜在空间以学习视角不变性表示。(关于潜在空间 latent space参考https://www.quora.com/What-is-the-meaning-of-latent-space,其实就是一个说不定几维的空间,这个空间中同一类的物体离的更近,以便于分类。上述链接可能打不开,内容见下图)

Recently, as deep learning performs well on various generation tasks, it has been employed on gait recognition task (Yu et al. 2017a; He et al. 2019; Takemura et al. 2018a; Shiraga et al. 2016; Yu et al. 2017b; Wu et al. 2017).
最近,由于深度学习在各种生成任务上表现良好,因此它已被(广泛)用于步态识别任务(列举了一堆相关文献)。
As the second category, video-based approaches directly take a sequence of silhouettes as input. Based on the way of extracting temporal information, they can be classified into LSTM-based approaches (Liao et al. 2017) and 3D CNN-based approaches (Wolf, Babaee, and Rigoll 2016; Wu et al. 2017).
作为第二类,基于视频的方法直接采用一系列轮廓作为输入。 基于提取时间信息的方式,可以将它们分类为基于LSTM的方法和基于3D CNN的方法。
The advantages of these approaches are that 1) focusing on each silhouette, they can obtain more comprehensive spatial information.2)They can gather more temporal information because specialized structures are utilized to extract sequential information. However, The price to pay for these advantages is high computational cost.
这些方法的优点在于:1)关注每个轮廓以获得更全面的空间信息.2)可以收集更多的时间信息,因为利用了专门的结构来提取顺序信息。 然而,为这些优势付出的代价是高计算成本。
2.2 无序序列的深度学习
Most works in deep learning focus on regular input representations like sequence and images. The concept of unordered set is first introduced into computer vision by (Charles et al. 2017) (PointNet) to tackle point cloud tasks. Using unordered set, PointNet can avoid the noise and the extension of data caused by quantization, and obtain a high performance. Since then, set-based methods have been wildly used in point cloud field(Wangetal.2018c;ZhouandTuzel2018; Qi et al. 2017).
大多数深度学习工作都致力于常规输入表示,如序列和图像。 无序集的概念首先被(Charles et al.2017)(PointNet)引入到计算机视觉中,以解决点云任务。PointNet使用无序序列,可以避免由量化引起的噪声和数据扩展,并获得更好的性能。于是,基于序列的方法被广泛用于点云领域(列举相关文献)。
Recently, such methods are introduced into computer vision domains like content recommendation (Hamilton, Ying, and Leskovec 2017) and image captioning (Krause et al. 2017) to aggregate features in a form of a set. (Zaheer et al. 2017) further formalized the deep learning tasks defined on sets and characterizes the permutation invariant functions. To the best of our knowledge, it has not been employed in gait recognition domain up to now.
最近,这些方法被引入计算机视觉领域,如内容推荐和图像字幕,用于聚合一个序列的特征。Zaheer等人进一步给出了深度学习任务中的序列描述和排列不变函数。据我们所知,它至今尚未被用于步态识别领域。
3. GaitSet
In this section, we describe our method for learning discriminative information from a set of gait silhouettes. The overall pipeline is illustrated in Fig. 2.
在本节中,我们将介绍从一组步态轮廓中学习判别信息的方法。 整个流程如图2所示。
3.1 问题表述
We begin with formulating our concept of regarding gait as a set.
首先,将步态视为一组序列。
Given a dataset of N people with identities yi,i ∈ 1,2,...,N, we assume the gait silhouettes of a certain person subject to a distribution Pi which is only related to its identity.
给定一个数据集,数据集中一共N个人,每个人用yi表示(共有y1,y2,...yN这么多个表示)。假设某个人的步态轮廓分布Pi只与这个人的ID有关(就是说一个人的轮廓和这个人是一一对应的,不会搞错,其实就是步态识别的可行基础,即每个人的步态独具特色)。
Therefore, all silhouettes in one or more sequences of a person can be regarded as a set of n silhouettes Xi = {x(ij) | j = 1,2,...,n}, where x(ij) ∼Pi. (为了方便打字,本文用x(ij) 代表 )
)
因此,在一个或多个序列中,所有的轮廓可以被看做是Xi = {x(ij) | j = 1,2,...,n}, 其中 x(ij) ∼Pi。
插入一段解释或者说是总结(以CASIC-B数据集为例):
数据集中有N=124个人,每个人用yi表示,比如我没记错的话ID=109的那个人的视频好多连人都没出现视频就结束了,那么在这个论文中就说y109视频不全。
在全部数据集中闭着眼睛任选出来一个轮廓怎么表示那?假如选到的轮廓图所在序列一共有20帧,选的的轮廓图是序列中的第3帧,那么表示方法就是x(20 3),其所在序列表示为X20。
Under this assumption, we tackle the gait recognition task through 3 steps, formulated as:
在这个假设下,我们通过3个步骤解决步态识别任务,表述为:
![]()
where F is a convolutional network aims to extract framelevel features from each gait silhouette.
其中F是卷积网络,旨在从每个步态轮廓中提取帧级特征。
The function G is a permutation invariant function used to map a set of framelevel feature to a set-level feature (Zaheer et al. 2017). It is implemented by an operation called Set Pooling (SP) which will be introduced in Sec. 3.2.
函数G是用于将一组帧级特征映射到序列级特征的排列不变函数。该函数通过Set Pooling(SP)实现,详细信息在Sec.3.2中介绍。
The function H is used to learn the discriminative representation of Pi from the set-level feature. This function is implemented by a structure called Horizontal Pyramid Mapping (HMP) which will be discussed in Sec. 3.3.
函数H用于从序列级特征中学习Pi的辨别表示。(就是对序列级特征进行分类,对应到每个人身上)这个函数是通过一个叫做Horizontal Pyramid Mapping(HPM此处原文应该是打错了)的结构实现的,将在Sec.3.3中介绍。
The input Xi is a tensor with four dimensions, i.e. set dimension, image channel dimension, image hight dimension, and image width dimension.
输入Xi是具有四个维度的tensor,分别是序列维度,图像通道维度,图像高度和图像宽度维度。tensor.shape=(n帧,2通道,64,64)
3.2 Set Pooling
The goal of Set Pooling (SP) is to aggregate gait information of elements in a set, formulated as z = G(V ), where z denotes the set-level feature and V = {vj|j = 1,2,...,n} denotes the frame-level features. (vj表示 )
)
Set Pooling(SP)的目的在于收集一下整个序列的步态信息,公式化表示成z = G(V ),其中z表示序列级特征, V = {vj|j = 1,2,...,n}表示帧级特征。
There are two constraints in this operation.
此处有两个约束条件。
First, to take set as an input, it should be a permutation invariant function which is formulated as:
第一,将序列作为输入,它应该是一个排列不变函数,其表达式为:

其中π为任意排列组合。
Second, since in real-life scenario the number of a person’s gait silhouettes can be arbitrary, the function G should be able to take a set with arbitrary cardinality.
第二,因为现实生活场景中,一个人的步态轮廓数可是是任意的,函数G应该可以输入任意基数的序列。(就是这个序列可长可短,多少帧都行,这是GaitSet宣传的一大优势)
Next, we describe several instantiations of G. It will be shown in the experiments that although different instantiations of SP do have sort of influence on the performances, they do not differ greatly and all of them exceed GEI-based methods by a large margin.
下面,我们介绍了函数G的几个实例。在实验中将显示尽管SP的不同实例确实对性能有影响,但它们没有很大差异并且它们都大大超过基于GEI的方法。
Statistical Functions 统计函数
To meet the requirement of invariant constraint in Equ. 2, a natural choice of SP is to apply statistical functions on the set dimension. Considering the representativeness and the computational cost, we studied three statistical functions: max(·), mean(·) and median(·). The comparison will be shown in Sec. 4.3.
在满足Equ. 2中不变约束的要求下,SP一个很自然的选取是在序列维度上应用统计函数。 考虑到典型性和计算成本,研究了三个统计函数:max(·),mean(·)和median(·)。 比较将在Sec.4.3中展示。
Joint Function 联合函数
We also studied two ways to join 3 statistical functions mentioned above:
我们也研究了两种上述3个统计函数共同作用的情况:

其中,cat表示在通道维度连接,1_1C表示1×1卷积层,max、mean、median都是应用在序列维度。Equ.4 是Equ.3的增强版,多出来的1×1卷积层可以学习合适的权重以组合不同统计函数提取的信息。
Attention 注意力机制
这部分原文大量使用了refine这个词,我大概有个理解,但是没想好这个词怎么翻译才合理。
Since visual attention was successfully applied in lots of tasks, we use it to improve the performance of SP.
由于视觉注意力已成功应用于大量任务中,因此我们使用它来提高SP的性能。
Its structure is shown in Fig. 3. The main idea is to utilize the global information to learn an element-wise attention map for each frame-level feature map to refine it.
其结构如图3所示。主要思想是利用全局信息来学习每个帧级特征图的元素注意力图,以便提炼更有价值信息。
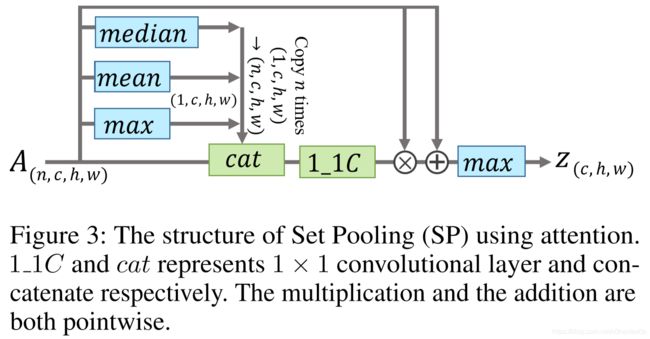
图3 Set Pooling(SP)应用注意力机制的结构。1_1C和cat分别代表1×1卷积层和连接。乘法和加法都是逐点的。
Global information is first collected by the statistical functions in the left. Then it is fed into a 1×1 convolutional layer along with the original feature map to calculate an attention for the refinement. The final set-level feature z will be extracted by employing MAX on the set of the refined frame-level feature maps. The residual structure can accelerate and stabilize the convergence.
首先由左侧(上面)的统计函数收集全局信息。然后,将其与原始特征图一起送入1×1卷积层计算注意力以精炼特征信息。通过在所设置的帧级特征映射的集合上使用MAX来提取最终的设置级特征z。最终的序列级特征z将被MAX应用在序列维度。残余结构可以加速并稳定收敛。
3.3 Horizontal Pyramid Mapping
In literature, splitting feature map into strips is commonly used in person re-identification task.The images are cropped and resized into uniform size according to pedestrian size whereas the discriminative parts vary from image to image.
在文献中,将特征图分割成条的方式经常用于人的重新识别任务。根据行人大小裁剪图像并将其尺寸调整为均匀尺寸,但辨别部分仍然因图像而异。
(Fu et al. 2018) proposed Horizontal Pyramid Pooling (HPP) to deal with it. HPP has 4 scales and thus can help the deep network focus on features with different sizes togather both local and global information. We improve HPP to make it adapt better for gait recognition task.
(Fu et al.2018)提出了Horizontal Pyramid Pooling(HPP) 来处理上述问题。 HPP有4个等级,因此可以帮助深度网络同时提取局部和全局特征。我们改进了HPP使其更适合步态识别任务。
Instead of applying a 1×1 convolutional layer after the pooling, we use independent fully connect layers (FC) for each pooled feature to map it into the discriminative space, as shown in Fig. 4. We call it Horizontal Pyramid Mapping (HPM).
如图4所示,我们对每个池化后的特征使用独立的完全连接层(FC)将其映射到判别空间,而不是在合并后应用1×1卷积层。我们称这样的操作为Horizontal Pyramid Mapping (HPM)。

图4 HPM结构图
Specifically, HPM has S scales. On scale s ∈ 1,2,...,S, the feature map extracted by SP is split into  strips on height dimension, i.e.
strips on height dimension, i.e.  strips in total.
strips in total.
具体而言,HPM具有S个尺度。再尺度s ∈ 1,2,...,S上,由SP提取的特征图在高度尺寸上被分成条,即总共条。
(举个例子,假如S=3,则一个人的特征在竖直方向上如下图被分割成3种尺度,=4条,所有尺度的条加在一起一共是1+2+4=7=)

Then a Global Pooling is applied to the 3-D strips to get 1-D features. For a strip zs,t where t ∈ 1,2,..., stands index of the strip in the scale, the Global Pooling is formulated as f's,t = maxpool(zs,t) + avgpool(zs,t), where maxpool and avgpool denote Global Max Pooling and Global Average Pooling respectively. Note that the functions maxpool and avgpool are used at the same time because it outperforms applying anyone of them alone.
然后,用一个全局池化将3维条变成1维特征。对于一个条zs,t来说,t ∈ 1,2,...,代表尺度s种条的角标,全局池化的公式是 f's,t = maxpool(zs,t) + avgpool(zs,t),其中maxpool和avgpool分别代表全局最大池化和全局平均池化。注:同时使用maxpool和avgpool是因为同时使用比只使用其中一种效果要好。
The final step is to employ FCs to map the features f‘ into a discriminative space. Since strips in different scales depict features of different receptive fields, and different strips in each scales depict features of different spatial positions, it comes naturally to use independent FCs, as shown in Fig. 4.
最后一步是使用FC(全连接)将特征f'映射到辨别空间。因为不用的条在不同的尺度中描述不同的感受野,并且不同的条在每个尺度中秒速不同空间位置的特征,因此如图4,很自然会想到用独立的FC。
3.4 Multilayer Global Pipeline
Different layers of a convolutional network have different receptive fields. The deeper the layer is, the larger the receptive field will be. Thus, pixels in feature maps of a shallow layer focus on local and fine-grained information while those in a deeper layer focus on more global and coarse-grained information.
不同层的卷积网络具有不同的感受野。越深层具有越大的感受野。因此,浅层特征更注重细粒度,而深层特征蕴含更多全局粗粒度信息。
The set-level features extracted by applying SP on different layers have analogical property. As shown in the main pipeline of Fig. 2, there is only one SP on the last layer of the convolutional network. To collect various-level set information, Multilayer Global Pipeline (MGP) is proposed. It has a similar structure with the convolutional network in the main pipeline and the set-level features extracted in different layers are added to MGP.
SP提取的序列级特征在不同层有相似的属性。如图2所示的主流程,在卷积网络的最后只有一个SP。为了收集不同级别的序列信息而提出Multilayer Global Pipeline (MGP)。
The final feature map generated by MGP will also be mapped into features by HPM. Note that the HPM after MGP does not share parameters with the HPM after the main pipeline.
最终由MGP生成的特征也被HPM分成条特征。注意:在MGP后面的HPM不会和主流程后面的HPM共享参数。
3.5 训练和测试
训练损失函数
As aforementioned, the output of the network is  features with dimension d. The corresponding features among different samples will be used to compute the loss.
features with dimension d. The corresponding features among different samples will be used to compute the loss.
如上所述,网络的输出是具有d个维度的个特征。不同样本对应的特征将被用于计算损失。
In this paper, Batch All (BA+) triplet loss is employed to train the network (Hermans, Beyer, and Leibe 2017).
本文中,训练网络使用Batch All(BA+)三元损失。(BA+三元损失在文章《In Defense of the Triplet Loss for Person Re-Identification》中的Sec.2的第6段介绍。)
A batch with size of p×k is sampled from the training set where p denotes the number of persons and k denotes the number of training samples each person has in the batch.
从训练集中拿出一个大小是p*k的batch,其中p是人数,k是每个人拿k个样本(样本其实是视频,而不是帧图像,此处为根据评论区信息更正)。
Note that although the experiment shows that our model performs well when it is fed with the set composed by silhouettes gathered from arbitrary sequences, a sample used for training is actually composed by silhouettes sampled in one sequence.
注:虽然我们的模型在输入任意序列中的轮廓测试时表现良好,但是训练的时候其实是用一个序列中的轮廓训练的。(我理解的这句话意思是:测试阶段,可以混合输入一个人任意序列中的某些轮廓,但是训练时,是每个人每次只输入一个序列中的某些轮廓)
测试
Given a query Q, the goal is to retrieve all the sets with the same identity in gallery set G. Denote the sample in G as g. The Q is first put into GaitSet net to generate multiscale features, followed by concatenating all these features into a final representations Fq as shown in Fig. 2. The same process is applied on each g to get Fg. Finally,Fq is compared with every Fg using Euclidean distance to calculate Rank 1 recognition accuracy.
给定一个待验证序列Q,目标是在图片序列G中遍历全部序列找到与给定相同的ID。设G中的样本为g。首先将Q输入到GaitSet网络中生成多尺度特征,然后将这些特征连接起来形成最终的表示Fq,如图2所示。每一个样本g都走一遍一样的流程,即输入Gait Set网络并连起来,生成Fg。最终,Fq与每一个Fg计算欧式距离来判断一次命中的识别正确率。
4 实验
Our empirical experiments mainly contain three parts. The first part compares GaitSet with other state-of-the-art methods on two public gait datasets: CASIA-B (Yu, Tan, and Tan 2006) and OU-MVLP (Takemura et al. 2018b). The Second part is ablation experiments conducted on CASIA-B. In the third part, we investigated the practicality of GaitSet in three aspects: the performance on limited silhouettes, multiple views and multiple walking conditions.
我们的实验注意包含3个部分。第一部分是比较GaitSet和其他顶级算法在2个公开数据集CASIA-B和OU-MVLP上的效果。第二部分是对CASIA-B进行的消融实验(类似控制变量)。第三部分从三个方面研究了GaitSet的实用性:有限轮廓下的性能表现,多视图和多步行条件下的性能。
4.1 数据集和训练细节
CASIA-B
CASIA-B dataset (Yu, Tan, and Tan 2006) is a popular gait dataset. It contains 124 subjects (labeled in 001-124), 3 walking conditions and 11 views (0◦,18◦,...,180◦). The walking condition contains normal (NM) (6 sequences per subject), walking with bag (BG) (2 sequences per subject) and wearing coat or jacket (CL) (2 sequences per subject). Namely,eachsubjecthas 11×(6+2+2) = 110 sequences.
CASIA-B 数据集是一个流行的步态数据集。内含124个对象(标记为001-124号),3种走路状态和11个角度(0°,18°,...,180°)。行走状态包含正常(NM)(每人6组)、背包(GB)(每人2组)、穿外套或夹克衫(CL)(每人2组)。也就是,每个人有 11×(6+2+2) = 110 个序列。
As there is no official partition of training and test sets of this dataset, we conduct experiments on three settings which are popular in current literatures. We name these three settings as small-sample training (ST), medium-sample training (MT) and large-sample training (LT). In ST, the first 24 subjects (labeled in 001-024) are used for training and the rest 100 subjects are leaved for test. In MT, the first 62 subjects are used for training and the rest 62 subjects are leaved for test. In LT, the first 74 subjects are used for training and the rest 50 subjects are leaved for test.
因为数据集不存在官方规定的训练和测试部分,我们用当前文献中流行的3种分配方法进行实验。我们将这3种分配方法取名为小样本训练(ST)、中样本训练(MT)、大样本训练(LT)。ST是前24人用作训练集,余下的后100人作为验证集。MT是前62人用作训练集,余下的后62人作为验证集。LT是前74人作为训练集,余下的后50人作为验证集。
In the test sets of all three settings, the first 4 sequences of the NM condition(NM #1-4) are kept in gallery, and the rest 6 sequences are divided into 3 probe subsets, i.e. NM subsets containing NM #5-6, BG subsets containing BG #1-2 and CL subsets containing CL #1-2.
在所有三种设置的测试集中,NM条件的前4个序列(NM#1-4)保持在图库中,其余6个序列被分成3个探针子序列,即包含NM#5-6的NM,BG#1-2,CL#1-2的CL子序列。
OU-MVLP
OU-MVLP dataset (Takemura et al. 2018b) is so far the world’s largest public gait dataset. It contains 10,307 subjects,14views(0◦,15◦,...,90◦;180◦,195◦,...,270◦)per subject and 2 sequences (#00-01) per view. The sequences are divided into training and test set by subjects (5153 subjects for training and 5154 subjects for test). In the test set, sequences with index #01 are kept in gallery and those with index #00 are used as probes.
OU-MVLP 数据集是迄今为止世界最大的公开步态数据集。其中包含10307个人, 每人14个角度,每个角度2个序列。全部序列被分成训练集和验证集(训练集包含5153个人,测试集包含5154个人)。测试集中,#01号序列被归为图库,#00号序列被用作探针。
训练细节
In all the experiments, the input is a set of aligned silhouettes in size of 64 × 44. The silhouettes are directly provided by the datasets and are aligned based on methods in (Takemura et al. 2018b). The set cardinality in the training is set to be 30. Adam is chosen as an optimizer (Kingma and Ba 2015). The number of scales S in HPM is set as 5. The margin in BA+ triplet loss is set as 0.2. The models are trained with 8 NVIDIA 1080TI GPUs. 1)
在所有的实验中,输入都是一系列64×44的对齐轮廓。轮廓有数据集直接提供并且对齐是基于Takemure的方法。训练集使用每个人每个序列的30张图片。优化器是Adam优化器。HPM种的尺度S=5。三元损失BA+的margin设置为0.2。用8个NVIDIA 1080TI GPU训练的模型。
1) In CASIA-B, the mini-batch is composed by the manner introduced in Sec. 3.5 with p = 8 and k = 16. We set the number of channels in C1 and C2 as 32, in C3 and C4 as 64 and in C5 and C6 as 128. Under this setting, the average computational complexity of our model is 8.6GFLOPs. The learning rate is set to be 1e − 4. For ST, we train our model for 50K iterations. For MT, we train it for 60K iterations. For LT, we train it for 80K iterations.
1)CASIA-B中,mini-batch由前面Sec.3.5中介绍的p=8,k=16两部分组成。将C1和C2的通道数设置成32,C3和C4的通道数设置成64,C5和C6的通道数为128。按照这种设置,我们模型的平均计算复杂度是8.6GFLOPs。学习率是1e-4。ST训练时,模型训练50000轮,MT 60000轮,LT80000轮。
2)In OU-MVLP, since it contains 20 times more sequences than CASIA-B, we use convolutional layers with more channels (C1 = C2 = 64,C3 = C4 = 128,C5 = C6 = 256) and train it with larger batch size (p = 32,k = 16). The learning rate is 1e−4 in the first 150K iterations, and then is changed into 1e−5 for the rest of 100K iterations.
2)OU-MVLP中比CASIA-B多了20倍的序列,因此我们使用更深的卷积层(C1 = C2 = 64,C3 = C4 = 128,C5 = C6 = 256)并且训练的batch size更大(p = 32,k = 16)。前150000轮学习率是1e-4,后100000轮学习率衰减到1e-5。
4.2 主要结果
CASIA-B
Tab. 1 shows the comparison between the stateof-the-art methods 1 and our GaitSet. Except of ours, other results are directly taken from their original papers. All the results are averaged on the 11 gallery views and the identical views are excluded. For example, the accuracy of probe view 36◦ is averaged on 10 gallery views, excluding gallery view 36◦
Tab.1展示了Gait Set与顶级算法之间的比较。出来GaitSet,其他数据是直接从各自的文章中引用的。所有结果均在11个视角中取平均值,并且不包括相同的视角。例如,视角36°探针的正确率是平均了除36°以外的10个视角。
An interesting pattern between views and accuracies can be observed in Tab. 1. Besides 0◦ and 180◦ , the accuracy of 90◦ is a local minimum value. It is always worse than that of 72◦ or 108◦.
从表1中可以看出视角和正确率有一种有趣的关系。除0°和180°外,90°的精度是局部最小值。 90°时总是比72°或108°更差。
The possible reason is that gait information contains not only those parallel to the walking direction like stride which can be observed most clearly at 90◦, but also those vertical to the walking direction like a left-right swinging of body or arms which can be observed most clearly at 0◦ or 180◦. So, both parallel and vertical perspectives lose some part of gait information while views like 36◦ or 144◦ can obtain most of it.
可能的原因是,步态信息不仅包含与步行方向平行的步幅信息,例如在90°时可以最清楚地观察到的步幅,还包括与行走方向垂直的步态信息,如可以观察到的身体或手臂的左右摆动最明显的是0°或180°。 因此,平行视角(90°)和垂直视角(0°&180°)都会丢失部分步态信息,而像36°或144°这样的视图可以获得大部分信息。
Small-Sample Training (ST)
Our method achieves a high performance even with only 24 subjects in the training set and exceed the best performance reported so far (Wuetal. 2017) over 10 percent on the views they reported. There are mainly two reasons.
我们的方法在仅有24个目标的训练集依然能够获得迄今为止所有算法中最佳效果切超过此前最好值10%有如下两个主要原因:
1) As our model regards the input as a set, images used to train the convolution network in the main pipeline are dozens of times more than those models based on gait templates. Taking a mini-batch for an example, our model is fed with 30×128 = 3840 silhouettes while under the same batch size models using gait templates can only get 128 templates.
1)由于我们的模型将输入视为一组图像,用于训练主流水线中的卷积网络的图像比基于步态模板的模型多几十倍。拿一个mini-batch举例子,我们的模型输入30×128=3840个轮廓而同样batch size的步态模板类模型只能获得128个模板。
2)Since the sample sets used in training phase are composed by frames selected randomly from the sequence, each sequence in the training set can generate multiple different sets. Thus any units related to set feature learning like MGP and HPM can also be trained well.
2)由于训练阶段中使用的样本序列由从序列中随机选择的帧组成,因此训练集中的每个序列可以生成多个不同的集合。 因此,与MGP和HPM等序列特征学习相关的任何单元也可以很好地得到训练。
Medium-Sample Training (MT) & Large-Sample Training (LT)
Tab. 1 shows that our model obtains very nice results on the NM subset, especially on LT where results of all views except 180◦ are over 90%. On the BG and CL subsets, although the accuracies of some views like 0◦ and 180◦ are still not high, the mean accuracies of our model exceed those of other models for at least 18.8%.
Tab.1显示我们的模型在NM子序列上获得了非常好的结果,特别是在LT上,除180°以外的所有视图的结果都超过90%。 在BG和CL子序列上,虽然0°和180°等一些视图的准确度仍然不高,但我们模型的平均精度超过其他模型的平均精度至少18.8%。
OU-MVLP
Tab. 3 shows our results. As some of the previous works did not conduct experiments on all 14 views, we list our results on two kinds of gallery sets, i.e. all 14 views and 4 typical views (0◦,30◦60◦90◦). All the results are averaged on the gallery views and the identical views are excluded. The results show that our methods can generalize well on the dataset with such a large scale and wide view variation. Further, since representation for each sample only needs to be calculated once, our model can complete the test (containing 133780 sequences) in only 7 minutes with 8 NVIDIA 1080TI GPUs. It is note worthy that since some subjects miss several gait sequences and we did not remove them from the probe, the maximum of rank-1 accuracy cannot reach 100%. If we ignore the cases which have no corresponding samples in the gallery, the average rank-1 accuracy of all probe views is 93.3% rather than 87.1%.
Tab.3显示了我们的结果。由于之前的工作没有涵盖全部14个视角的实验,我们列出了两种图库序列的结果,即14个视角和4个典型视角(0◦,30◦60◦90◦)。所有结果均在全部视角中取平均值,并且不包括相同的视角。结果显示,我们的方法在如此大规模多角度的数据集上仍然具有很强的泛化能力。此外,由于每个样本的表达仅需要计算一次,因此用8块NVIDIA 1080TI GPU测试一次模型(包含133780个序列)只需要7分钟。值得注意的是,由于一些目标错过了几个步态序列并且我们没有从探针中移除它们,因此一次命中率的最大值不能达到100%。如果忽略掉上述有问题的样本,一次命中率会从87.1%提高到93.3%。

4.3 AblationExperiments 消融实验
Tab. 2 shows the thorough results of ablation experiments. The effectiveness of every innovation in Sec. 3 is studied.
Tab.2展示了消融实验的全部结果。研究了Sec.3中每项创新的有效性。

Set VS. GEI
The first two lines of Tab. 2 show the effectiveness of regarding gait as a set. With fully identical networks, the result of using set exceeds that of using GEI by more than 10% on NM subset and more than 25% on CL subset. The only difference is that in GEI experiment, gait silhouettes are averaged into a single GEI before being fed into the network.
Tab.2的前两行显示了将步态作为序列的有效性。对于完全相同的网络来讲,使用序列而不是GEI可以对NM子序列识别率提高10%,CL提高25%。前两行实验唯一不同的是GEI实验中,步态轮廓在送入网络之前按照均匀权值合并成一张GEI。
There are mainly two reasons for this phenomenal improvement. 1) Our SP extracts the set-level feature based on high-level feature map where temporal information can be well preserved and spatial information has been sufficiently processed. 2) As mentioned in Sec. 4.2, regarding gait as a set enlarges the volume of training data.
这种显著改善主要有两个原因。1)SP基于高级的特征图提取了序列级特征,可以很好的保留时间信息同时也充分运用空间信息。2)如Sec.4.2中提到的,将步态视作序列相当于增强训练数据。
Impact of SP
In Tab. 2, the results from the third line to the eighth line show the impact of different SP strategies. SP with attention, 1×1 convolution (1 1C) joint function and max(·) obtain the highest accuracy on the NM, BG, and CL subsets respectively. Considering SP with max(·) also achieved the second best performance on the NM and BG subset and has the most concise structure, we choose it as SP in the final version of GaitSet.
Tab.2中,3-8行的结果显示不同SP策略的影响,分别是SP+注意力机制,1×1卷积连接函数和max(·),3种SP策略在各个子序列中都有获得最高正确率。但考虑到max(·)除了在CL子序列中获得最高正确率,还在NM和BG子序列中获得第二高的正确率,我们选择max(·)作为SP的最终策略。
Impact of HPM and MGP
The second and the third lines of Tab. 2 compare the impact of independent weight in HPM. It can be seen that using independent weight improves the accuracy by about 2% on each subset.In the experiments, we also find out that the introduction of independent weight helps the network converge faster.The last two lines of Tab.2 show that MGP can bring improvement on all three test subsets. This result is consistent the theory mentioned in Sec. 3.4 that set-level features extracted from different layers of the main pipeline contain different valuable information.
Tab.2的第2、3行比较了HPM独立权重的影响。可以看出,独立权重可以使每种子序列的正确率提高2%。实验中,我们还发现引入独立权重可以帮助网络更快的聚合。 Tab.2的最后两行显示除MGP可以同时提高所有子序列的正确率。这个结果的理论依据如Sec.3.4所述帧级特征是从主流程中不同层里提取到的,包含了不同的有价值信息。
4.4 Practicality 实用性
Due to the flexibility of set, GaitSet has great potential in more complicated practical conditions. In this section, we investigate the practicality of GaitSet through three novel scenarios. 1) How will it perform when the input set only contains a few silhouettes? 2) Can silhouettes with different views enhance the identification accuracy? 3) Whether can the model effectively extract discriminative representation from a set containing silhouettes shot under different walking conditions. It is worth noting that we did not retrain our model in these experiments. It is fully identical to that in Sec. 4.2 with setting LT. Note that, all the experiments containing random selection in this section are ran for 10 times and the average accuracies are reported.
由于序列的灵活性,GaitSet仍有很大潜力可以挑战更复杂的实际情况。在这部分,我们通过3个新颖的场景来研究Gait Set的实用性。1)GaiSet能否在输入仅有几个轮廓时表现仍然良好?2)具有不同视角的轮廓是否可以提高识别准确度?3)模型是否可以有效的从一个包含不同行走状态轮廓的序列中提取表达特征?值得注意的是,我们没有在这些实验中重新训练我们的模型。模型时与Sec.4.2中的LT配置完全相同的。注:所有包含随机选取的实验都运行了10次并报告10次实验的平均精度。
Limited Silhouettes 有限轮廓数量
In real forensic identification scenarios, there are cases that we do not have a continuous sequence of a subject’s gait but only some fitful and sporadic silhouettes. We simulate such a circumstance by randomly selecting a certain number of frames from sequences to compose each sample in both gallery and probe. Fig. 5 shows the relationship between the number of silhouettes in each input set and the rank-1 accuracy averaged on all 11 probe views.
在真实法医鉴定场景中,很多情况下我们无法获取目标的连续步态序列,只有一些断断续续零星的轮廓。我们通过随机选取连续序列中的一些帧来模拟上述场景。Fig.5中显示了每组输入序列轮廓的数量和11个视角的一次命中率之间的关系。

图5.CASIA-B数据集使用LT训练,平均一次命中率受轮廓数量的约束。正确率是11个视角中除去相同视角的平均值。并且最终报告的结果是10次实验的平均值。
Our method attains an 82% accuracy with only 7 silhouettes. The result also indicates that our model makes full use of the temporal information of gait. Since 1) the accuracy rises monotonically with the increase of the number of silhouettes. 2) The accuracy is close to the best performance when the samples contain more than 25 silhouettes. This number is consistent with the number of frames that one gait period contains.
我们的方法在仅输入7个轮廓就可以得到82%的正确率。结果还表明我们的模型充分利用了步态的时间信息。因为:
1)随着轮廓数量的增加,精度单调上升。
2)当样本含量超过25个轮廓后,正确率接近最佳状态。这个数字与一个步态周期所包含的帧数一致。
MultipleViews 多视角
There are conditions that different views of one person’s gait can be gathered. We simulate these scenarios by constructing each sample with silhouettes selected from two sequences with the same walking condition but different views. To eliminate the effects of silhouette number, we also conduct an experiment in which the silhouette number is limited to 10. Specifically, in the contrast experiments of single view, an input set is composed by 10 silhouettes from one sequence. In the two-view experiment, an input set is composed by 5 silhouettes from each of two sequences. Note that in this experiment, only probe samples are composed by the way discussed above, whereas sample in the gallery is composed by all silhouettes from one sequence.
有些情况下收集到的是一个人不同视角的步态信息。我们通过从具一个人的相同步态情况不同视角序列中抽取轮廓的方式模拟上述情况。为了消除轮廓数的影响,我们还进行了一个实验,其中轮廓数限制为10。具体而言,在单视角对比实验中,一个输入 序列由10个轮廓构成。在2个视角实验中,一个输入序列由每个序列抽取5个轮廓共计10个轮廓组成。值得注意的是,实验中只有探针是如上组成,图库中其他样本是由一个序列中的全部轮廓构成的。

Tab. 4 shows the results. As there are too many view pairs to be shown, we summarize the results by averaging accuracies of each possible view difference. For example, the result of 90◦ difference is averaged by accuracies of 6 view pairs (0◦&90◦,18◦&108◦,...,90◦&180◦). Further, the 9 view differences are folded at 90◦ and those larger than 90◦ are averaged with the corresponding view differences less than 90◦. For example, the results of 18◦ view difference are averaged with those of 162◦ view difference.
Tab.4显示了结果。由于需要展示的视角对太多了,我们将每个可能的相差视角结果取了平均值。例如:90°一列6个视角对(0◦&90◦,18◦&108◦,...,90◦&180◦)的平均值。另外,视角差共计有9中可能,大于90°和小于90°部分对称合并求取平均值了。例如:18°视角差和162°视角差的正确率合并在一起计算平均正确率。
It can be seen that our model can aggregate information from different views and boost the performance. This can be explained by the pattern between views and accuracies that we have discussed in Sec. 4.2. Containing multiple views in the input set can let the model gather both parallel and vertical information, resulting in performance improvement.
可以看出,我们的模型可以聚合来自不同视图的信息并提高性能。这可以通过我们在Sec.4.2中讨论的视图和准确度之间的模式来解释。包含多视角输入序列可以让模型聚集平行视角(90°)和垂直视角(0°&180°)信息,以获得更好的表现。
Multiple Walking Conditions
In real life, it is highly possible that gait sequences of the same person are under different walking conditions. We simulate such a condition by forming input set with silhouettes from two sequences with same view but different walking conditions. We conduct experiments with different silhouette number constraints. Note that in this experiment, only probe samples are composed by the way discussed above. Any sample in the gallery is constituted by all silhouettes from one sequence. What’s more, the probe-gallery division of this experiment is different. For each subject, sequences NM #02, BG #02 and CL #02 are kept in the gallery and sequences NM #01, BG #01 and CL #01 are used as probe.
现实生活中,很可能同一个人有不同的行走状态。我们通过从同一个同样视角的两个不同行走状态的序列中抽取轮廓构成模拟上述情况的序列。我们用不同轮廓数量进行实验。注意:只有探针样本是如上方法构造的,其他样本还是用一个序列中的全部轮廓。另外,该实验的探针划分有些不同。对于每个目标而言,序列 NM #02, BG #02 和 CL #02还保持在图库中,但是NM #01, BG #01 和CL #01作为探针。

Tab. 5 shows the results. First, the accuracies will still be boosted with the increase of silhouette number. Second,when the number of silhouettes are fixed, the results reveal relationships between different walking conditions. Silhouettes of BG and CL contain massive but different noises, which makes them complementary with each other. Thus, their combination can improve the accuracy. However, silhouettes of NM contain few noises, so substituting some of them with silhouettes of other two conditions cannot bring extra information but only noises and can decrease the accuracies.
Tab.5显示了结果。首先,正确率还是回随着轮廓数量的增加而增长。第二,当轮廓数量固定时,揭示了不同行走条件之间的关系。轮廓BG和 CL包含了大量不同的轮廓且噪声不同,这使得他们互补。因此,他们的结合可以提升准确率。 但是,NM轮廓包含很少的噪声,因此用其他两个条件的轮廓代替NM中的一些不能带来有用的信息,只能产生噪音,并且会降低精度。
5 结论
In this paper, we presented a novel perspective that regards gait as a set and thus proposed a GaitSet approach. The GaitSet can extract both spatial and temporal information more effectively and efficiently than those existing methods regarding gait as a template or sequence. It also provide a novel way to aggregate valuable information from different sequences to enhance the recognition accuracy. Experiments on two benchmark gait datasets has indicated that compared with other state-of-the-art algorithms, GaitSet achieves the highest recognition accuracy, and reveals a wide range of flexibility on various complex environments, showing a great potential in practical applications. In the future, we will investigate a more effective instantiation for Set Pooling (SP) and further improve the performance in complex scenarios.
在本文中,我们提出了一种新的视角,将步态视为一组序列,从而提出了一种GaitSet方法。GaitSet可以比那些将步态作为模板或序列的现有方法更有效地提取空间和时间信息。它还提供了一种从不同序列聚合有价值信息的新方法,以提高识别准确性。两个基准步态数据集(公开标准数据集)的实验表明,与其他最先进的算法相比,GaitSet实现了最高的识别精度,并在各种复杂环境中显示出广泛的灵活性,在实际应用中显示出巨大的潜力。后续,我们将研究更有效的Set Pooling(SP)实例化,并进一步提高复杂场景的性能。