面试必备——MySQL的MVCC实现原理
文章目录
- 1 问题背景
- 2 前言
- 3 什么是MVCC
- 4 必备知识
-
- 4.1 行记录的三个隐藏字段
- 4.2 版本链
- 4.3 一致性读(快照读)和锁定读(当前读)
- 4.4 Read View
-
- 4.4.1 简介
- 4.4.2 ReadView类
- 5 实现原理
-
- 5.1 如何通过ReadView来判断记录的哪个版本是否可见
- 5.2 何时生成ReadView快照
- 6 总结
1 问题背景
生产环境上的电商项目中,常常遇到MySQL等待锁超时的报错,实际场景常见于批量更新店铺的税费(针对地区批量更新)、批量更新商品系列的内容等等,这涉及了写-写操作。研究了关于MySQL的存储架构、MySQL锁知识,详情见MySQL高级专栏。今天来研究MySQL的MVCC知识。
参考自
- MySQL官方文档——InnoDB Multi-Versioning
- MySQL专有名词文档——MySQL Glossary
- 【MySQL笔记】正确的理解MySQL的MVCC及实现原理
- 面试题60:请概述一下,什么是MVCC?那版本链呢?ReadView又有什么用?
- ReadView 类的官方文档介绍
2 前言
- 本篇博客注重讲述实现原理,很多处地方可能晦涩难懂,读一次半次理解不了是很正常的,笔者在上班工作之余,花了一个月学习MySQL存储架构、锁、MVCC等相关的知识点。需要反复阅读并思考,细细品味才能慢慢理解。前两三次不必追求背诵它,先浏览并理解个大概,再反复细致阅读并思考。
- 此博客的用意在于更好地理解工作中CRUD的底层原理,以及理解MySQL是如何处理并发请求的。学习MVCC对自身价值也能有很大帮助(比如自身的知识体系广度以及深度,提高分析、定位生产问题的能力,面试等)。
- 笔者学习MVCC的方式是以MySQL官方文档为主(避免学习了别人错误的理解),以别人的博客、微信公众号的相关推文为辅(他人写出来的文档思路非常值得学习,也助于自身理解)。
- 本文如有不正确的地方或疑惑,请于评论处指正,能将自己学习到的知识讲明白给大伙听是笔者创作的动力,觉得文章不错可以给个赞或收藏或评论。
3 什么是MVCC
官方原文:
InnoDB is a multi-version storage engine. It keeps information about old versions of changed rows to support transactional features such as concurrency and rollback. This information is stored in undo tablespaces in a data structure called a rollback segment. See Section 15.6.3.4, “Undo Tablespaces”. InnoDB uses the information in the rollback segment to perform the undo operations needed in a transaction rollback. It also uses the information to build earlier versions of a row for a consistent read. See Section 15.7.2.3, “Consistent Nonlocking Reads”.
MVCC,全称Multi-Version Concurrency Control,译为多版本并发控制。InnoDB是一个多版本的存储引擎。它会保存着被变更的记录的老版本信息,以此来支持事务的特性,比如并发、回滚。这些信息以被称为回滚段的数据结构被存储在undo表空间(一个回滚段中有若干条undo log,若干条undo log会形成一个链表(常称为版本链),一个undo表空间中有若干个回滚段)。详情看Section 15.6.3.4, “Undo Tablespaces”。InnoDB使用回滚段中的信息来执行事务回滚过程中所需的回滚操作。InnoDB也使用回滚段中的信息来构建一行记录的早期版本,以此来实现一致性读取。详情见Section 15.7.2.3, “Consistent Nonlocking Reads”。
总结:MVCC是InnoDB的一种机制,用于支持事务的某些特性,比如并发、回滚。实际场景有回滚和一致性读取。实现原理涉及到undo log。记录的若干版本信息存储在回滚段中,即一个回滚段有若干条undo log
4 必备知识
学习以下这些必备知识,能更加容易理解MVCC的实现原理
4.1 行记录的三个隐藏字段
-
DB_TRX_ID:6个字节,该字段表示插入或更新行记录时的最新事务标识。一个delete操作被内部当成一个update操作来处理,行记录的一个特定的比特位会被标记,作为该行记录已被删除。 -
DB_ROLL_PTR:7个字节,该字段称作回滚指针。回滚指针指向回滚段中的一条undo log记录,其实就是指向记录的上一个版本。如果行记录被更新,undo log记录会保存必要的信息来重构行记录被更新前的内容。 -
DB_ROW_ID:6个字节,该字段称作行ID,当有新行被插入时,行ID会自增。如果 InnoDB自动生成聚集索引,则索引包含行 ID 值。否则,该 DB_ROW_ID列不会出现在任何索引中。
4.2 版本链
MySQL官方文档并没有关于版本链的介绍,但理解这个概念相当重要。此处仅简单介绍版本链是什么,后面会详细介绍其中的细节。
假设现在有一张表
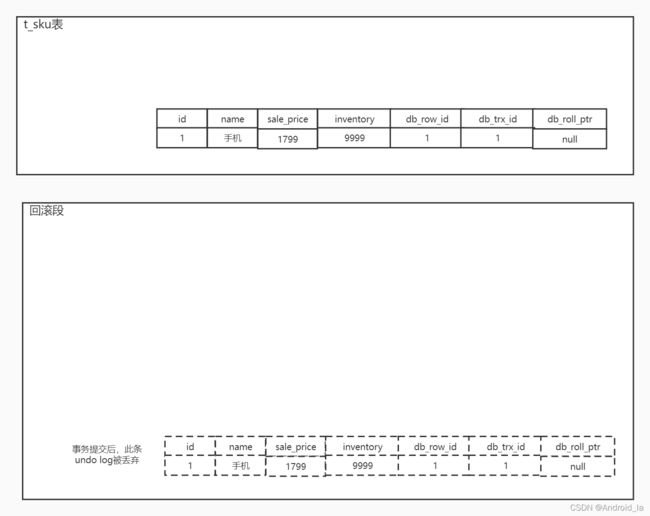
t_sku,记录商品sku的售价、原价、库存、sku名称等等。现在事务A往该表 插入一条记录,此时t_sku表的情况如下所示:

每次insert、update操作后,该条记录被变更前的信息都会被放入回滚段中,被放入回滚段中的这条记录称为undo log。因为是insert操作,事务提交后,该条undo就会立刻被销毁【1】
解释[1]:
官方原文:
Undo logs in the rollback segment are divided into insert and update undo logs. Insert undo logs are needed only in transaction rollback and can be discarded as soon as the transaction commits. Update undo logs are used also in consistent reads, but they can be discarded only after there is no transaction present for which InnoDB has assigned a snapshot that in a consistent read could require the information in the update undo log to build an earlier version of a database row. For additional information about undo logs, see Section 15.6.6, “Undo Logs”.笔者翻译:回滚段中的若干 undo log被分为插入类型的 undo log 和更新类型的 undo log 。插入类型的 undo log仅仅被用于事务回滚,当事务提交时,插入类型的 undo log 会被立刻丢弃。更新类型的 undo log 不仅被用于事务回滚,还被用于一致性读取(快照读),在一致性读取中,InnoDB需要使用更新类型的 undo log 来构建早期版本的数据库行记录(即生成所谓的快照),因此仅当没有事务使用该更新类型的 undo log时,该更新类型的 undo log 会被丢弃。(这块知识点有点绕,需要思考并品味。)
此时回滚段中的情况如下:
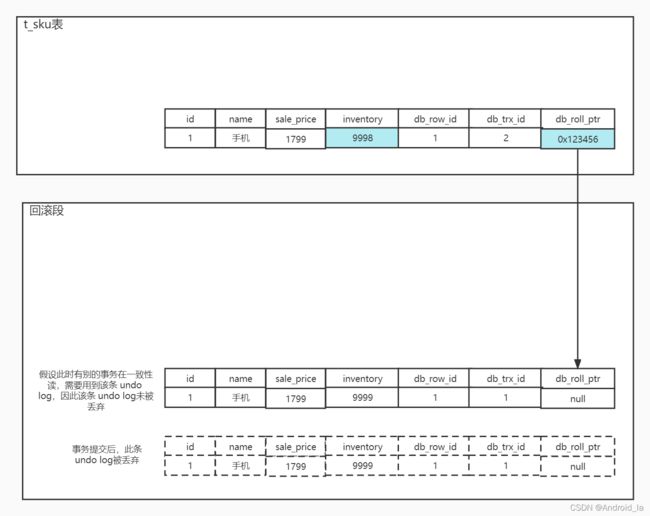
此时事务B修改
id = 1这条记录的库存字段inventory为9998,情况如下:
此时事务C修改
id = 1这条记录的库存字段inventory为9997,情况如下:
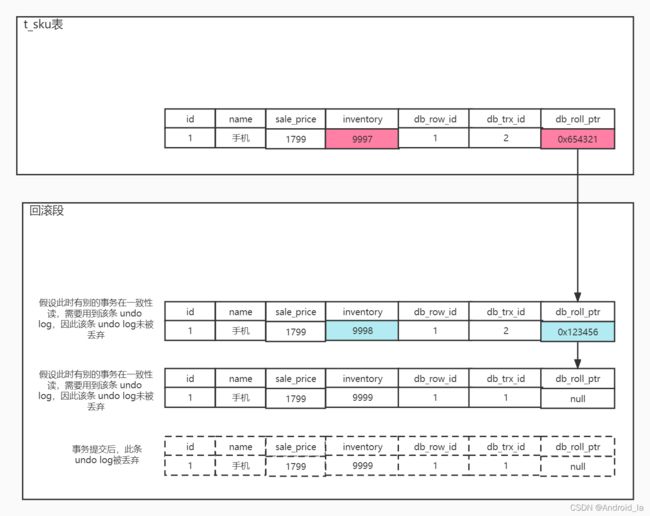
如上若干张图所示,经过数据库的DML操作,会出现一条版本链
4.3 一致性读(快照读)和锁定读(当前读)
一致性读是MySQL官方文档的专业术语,根据其解释的意思,网络广泛称其为快照读。锁定读是MySQL官文档的专业术语,根据其解释的意思,网络广泛称其为当前读
一致性读(快照读):
-
尽管同一时间会有其他事务执行变更记录的操作,一个读操作会使用某个时间点的 快照信息呈现查询结果。如果被查询的数据被其他事务修改,InnoDB会通过
undo log的内容重构被更改前的原始数据。这种技术避免一些锁定问题(InnoDB常常通过强制事务B等待事务A完成来减少并发)。 -
使用 REPEABLE READ(简称RR,可重复读) 隔离级别,快照是在执行 第一次 读操作的时候被建立起来的。使用 READ COMMITTED(简称RC,读已提交) 隔离级别,快照是在 每一次 一致性读操作时候被建立的。所以,这就能理解,为什么可重复读的隔离级别,都能读到相同的数据,即使事务B插入或更新了某条记录,事务A每一次读仍能读到相同的数据。而读已提交的隔离级别,事务B插入或更新了某条记录,即使事务B未提交事务,事务A已经能读到事务B操作之后的数据了。
-
一致性读是InnoDB在读已提交和可重复读隔离级别下处理
SELECT语句的默认模式。因为一致性读在访问数据表的时候不会给表加任何锁,所以其他会话可以在对表执行一致性读时自由修改这些表。
锁定读(当前读):
- 一个
SELECT语句也可以在InnoDB表上执行锁定操作。比如SELECT ... FOR UPDATE或者SELECT ... LOCK IN SHARE MODE。但是它有可能产生死锁,具体取决于事务的隔离级别。与非锁定读取相反,锁定读不允许用于只读事务(暂时不用过于钻研该概念,下面仅作简介)中的全局表。使用
只读事务:
官方原文:
A type of transaction that can be optimized for InnoDB tables by eliminating some of the bookkeeping involved with creating a read view for each transaction. Can only perform non-locking read queries. It can be started explicitly with the syntax START TRANSACTION READ ONLY, or automatically under certain conditions. See Section 8.5.3, “Optimizing InnoDB Read-Only Transactions” for details.
只读事务是事务中的一种类型。InnoDB表可以通过消除每个事务创建 Read View (该概念很重要,后面会介绍)时所涉及的一些薄记来优化只读事务。只读事务只能执行非锁定读取的查询。可以用START TRANSACTION READ ONLY显示地开启只读事务。或者在某些情况下自动开启。
总结:快照读读取到的不一定是最新版本的数据,有可能是历史版本的。不加锁的SELECT操作就是快照读。快照读的实现是MVCC,可以认为MVCC是行锁的变种,减少了加锁操作,降低了资源开销。当前读读取到的是最新版本的数据,SELECT LOCK IN SHARE MODE(共享锁,也叫S锁); SELECT... FOR UPDATE; UPDATE; INSERT; DELETE(排他锁,也叫X锁)这些操作都是当前读。为了保证其他并发事务不能修改当前记录,读取时会对记录进行加锁。
4.4 Read View
4.4.1 简介
官方原文:
An internal snapshot used by the MVCC mechanism of InnoDB. Certain transactions, depending on their isolation level, see the data values as they were at the time the transaction (or in some cases, the statement) started. Isolation levels that use a read view are REPEATABLE READ, READ COMMITTED, and READ UNCOMMITTED.
Read VIew 是InnoDB的内部快照,被用于MVCC机制中。InnoDB会根据Read View以及事务的隔离级别来判断,当事务开始时事务能看到哪个版本的数据(这个很重要)。可重复读、读已提交、读未提交都会使用Read View。
4.4.2 ReadView类
ReadView也是一个类,有属性和方法,只不过不是用Java写的,详情看官方介绍 ReadView Class Reference
ReadView类是用来做什么的?官方给出如下解释:
Read view lists the trx ids of those transactions for which a consistent read should not see the modifications to the database.
结合Read View是InnoDB的内部快照来理解,ReadView类是列出事务的id,哪些事务的id?是A事务进行一致性读取时,其余B、C、D等事务对数据库修改,列出对于A事务不可见的事务ID,或者说对于此次一致性读取不可见的事务id(比如A事务看不到B、C事务对数据库的修改,那么就列出B事务、C事务的id)。怎么判断是否可见?ReadView类本身会有算法方法进行判断 。(此处不必深究理解,笔者也可能存在理解错误,需要根据下面的原理去理解)
此处介绍ReadView几个重要的属性。
-
m_creator_trx_id:创建当前一致性读的事务ID。比如事务A,要读取数据库,InnoDB在可重复读的隔离级别下,大多数场景会使用一致性读,此时产生的一致性读,是由事务A触发产生的,那么m_creator_trx_id = 事务A的事务id -
m_ids:生成快照(ReadView)时,当前InnoDB中活跃的事务id列表。 -
m_low_limit_id:生成快照(ReadView)时,InnoDB应该分配给下一个事务的事务id。官方文档给了一个别名理解为high water mark。为什么用low单词命名?笔者理解应该是id是递增的,最新生成的id同时也是最小的,但比已有的id都大。 -
m_up_limit_id: 生成快照(ReadView)时,InnoDB的活跃事务id列表中最小的事务id。官方文档给了一个别名为the low water mark。
5 实现原理
5.1 如何通过ReadView来判断记录的哪个版本是否可见
通过前面一系列的知识,我们知道每一条记录基本都会存在一条版本链用于回滚或一致性读。当事务A发生一致性读时,怎么判断记录的版本链上,哪个版本对于事务或ReadView是可见的,哪个版本是不可见的?
必读!!!: 首先,必须要搞清楚,是对谁可见。ReadView是由事务触发的,其实从文章开始到此处,很多概念基本都是可以模糊理解成一样的,比如事务、一致性读、ReadVIew、快照,因为大部分情况下事务都会发起一致性读,那么就会产生一个快照,快照就是ReadView,ReadView也是快照。每条记录的版本链上的版本对谁是否可见?这个对谁是指对事务、对快照、对ReadView、对一致性读。因为这几个概念在此场景上基本能认为是一致的。
判断的标准,其实就是比较记录的版本上的
trx_id隐藏字段(详情看第4.1节)、ReadView类的m_low_limit_id、m_up_limit_id、m_ids、m_creator_trx_id字段,他们谁大谁小。
-
如果
trx_id=m_creator_trx_id,则表明当前事务在访问它修改过的记录,所以该版本 可以被当前事务访问。 -
如果
trx_id<m_up_limit_id,则表明生成该版本的事务(trx_id对应的事务) 在当前事务生成ReadView之前已经提交了,所以该版本 可以被当前事务访问。笔者总结为,版本的trx_id比最小的id都要小,则可以被当前事务访问。 -
如果
trx_id>m_low_limit_id,则表明生成该版本的事务(trx_id对应的事务) 在 当前事务 生成Read View之后才开启,所以该版本 不可以 当前事务访问。 笔者总结为,版本的trx_id比最大的id都要大,则不可以被当前事务访问。 -
如果
trx_idinm_ids,则表明生成ReadView时,生成该版本的事务还处于活跃状态,该版本不可以被当前事务访问。 -
如果
trx_idnot inm_ids,则表明生成ReadView时,生成该版本的事务已经被提交,该版本 可以 被当前事务访问。 -
如果 版本对当前事务不可见,则 顺着版本链找到下一个版本的数据,并继续执行上面的步骤判断版本是否可见,以此类推,直到版本链中的最后一个版本。
5.2 何时生成ReadView快照
在 读已提交(Read Committed, 简称RC) 隔离级别下,每一次读取数据前都生成一个ReadVIew。而在可重复读(Repeatable Read,简称RR)隔离级别下,在一个事务中,只在 第一次读取数据前生成一个ReadVIew。
6 总结
- 并发环境下,写-写操作有加锁解决方案,但为了提高性能,InnoDB存储引擎提供MVCC,目的是为了解决读-写,写-读操作下不加锁仍能安全进行。
- MVCC的原理涉及若干知识点,有行记录的3个隐藏字段、事务的隔离级别、undo log、一致性读、版本链、ReadView以及版本的可见性算法
- MVCC的过程,本质就是访问版本链,并判断哪个版本可见的过程。该判断算法是通过版本上的
trx_id与快照ReadView的若干个信息进行对比。 - 快照生成的时机因隔离级别不同,读已提交隔离级别下,每一次读取前都会生成一个快照ReadView;而可重复读则仅在一个事务中,第一次读取前生成一个快照。