【文献阅读】VAQF: Fully Automatic Software-Hardware Co-Design Framework for Low-Bit Vision Transformer
题目:VAQF: Fully Automatic Software-Hardware Co-Design Framework for Low-Bit Vision Transformer
时间:2022
会议/期刊:eprint arXiv:2201.06618
研究机构:Northeastern University, University of California, Irvine University of Texas at Austin
VAQF: Fully Automatic Software-Hardware Co-Design Framework for Low-Bit Vision Transformer
参考链接:VAQF : 低比特Vision Transformer的全自动软硬件协同设计框架
摘要
具有注意机制的Transformer架构在自然语言处理 (NLP) 中取得了成功,Vision Transformer (ViT) 最近将应用领域扩展到了各种视觉任务。在实现高性能的同时,ViT 的模型尺寸大且计算复杂度高,这阻碍了它们在边缘设备上的部署。为了在硬件上实现高吞吐量并同时保持模型准确性,我们提出了 VAQF,这是一个在 FPGA 平台上构建推理加速器的框架,用于具有binary weights and low-precision
activations的quantized ViT。给定模型结构和所需的frame rate,VAQF 将自动输出激活所需的量化精度以及满足硬件要求的加速器优化参数设置。这些实现是在 Xilinx ZCU102 FPGA 板上使用 Vivado 高级综合 (HLS) 开发的,使用基于 DeiT 的模型的评估结果表明, a frame rate requirement of 24 frames per second (FPS) is satisfied with 8-bit activation quantization, and a target of 30 FPS is met with 6-bit activation quantization. 据我们所知,这是第一次在 FPGA 的 ViT 加速中加入量化,借助全自动框架来指导软件端的量化策略和给定目标帧的硬件端的加速器实现速度。与量化训练相比,编译时间成本非常低,并且生成的加速器显示了在 FPGA 上实现最先进的 ViT 模型实时执行的能力。
I. Introduction
在过去的几年中,注意力机制,尤其是Transformer架构 [40],在自然语言处理 (NLP) 方面取得了显着进展 [32],[3]。最近,视觉变换器(ViT)结构[11]首次将变换器引入图像分类任务,并提出无卷积架构可以实现最先进的性能。后来,transformers 已广泛用于多种视觉任务性能,例如检测 [4]、[51]、分割 [50]、[43] 和姿势估计 [20]、[19]。然而,出色的性能提升需要增加模型规模和计算复杂度,并且很难将这些庞大的模型部署到增强现实和自动驾驶等现实世界的应用中。
为了解决这个问题,人们致力于将繁琐的 Transformer 架构压缩成一个轻量级的对应物,包括知识蒸馏 [17]、[35]、[38]、[39]、修剪 [28]、[8]、[7]和量化[48]、[1]、[36]。在所有这些压缩技术中,量化是一种流行的解决方案,因为它仍然保留了原始网络架构。具体而言,量化旨在用低位宽表示替换 32 位参数。在 NLP 中,最近的 Binary-BERT [1] 通过权重二值化将 BERT 量化推向了极限,并在激活时引入了量化以带来额外的能量节省。然而,与语言中的 one-hot 标记相比,视觉中的输入图像块包含更丰富的信息,目前尚不清楚二值化在 ViT 中是否仍然有效。
在本文中,我们首先将二值化引入视觉Transformer。由于完全二值化会导致 ViT 的准确度显着下降,因此我们对权重采用二进制精度,对激活采用低精度。与 Binary-BERT 不同,我们的方法直接应用 1-bit convolution [34]、[24] 中的方法来实现二进制权重。为了支持 FPGA 上量化的 ViT 模型的推理,我们提出了一个 ViT Automatic Quantization Framework,即 VAQF,以根据real-time frame rate requirement生成 ViT 加速器。A compilation step is conducted to automatically determine the quantization precision for activations on the software side and the accelerator parameter settings on the hardware side when the model weights are compressed into binary format. 从特定的激活精度,可以推断出一组加速器参数,从而可以提前估计整体资源利用率和推理性能。如果估计的frame rate达到目标,则决定相应的激活精度来指导量化过程,并采用相应的加速器设置进行硬件实现。Depending on the specific model structure and target frame rate, this compilation step costs several minutes to several hours, which is less than one tenth of the training time for quantization. 至于 ViT 加速器,包含一个通用计算引擎来处理具有一次矩阵乘法的全连接 (FC) 层和执行多次矩阵乘法的多头注意力层。由于二进制权重,量化计算可以用加法和减法代替,因此可以在 FPGA 上使用查找表 (LUT) 来实现。The computations along the output channel, input channel, and head dimensions are totally or partially pipelined following the accelerator settings. 此外,采用data packing technique来减轻内存负担并提高实现的整体计算吞吐量。具体来说,当对权重进行二值化时,我们的量化 ViT 在 ImageNet-1K 验证集上可以达到 79.5%,与全精度模型 (81.8%) 相比,性能仅下降 2.3%,但模型尺寸减小了 32 倍。当进一步将激活量化为 8 位和 6 位时,我们的方法仍然可以分别达到 77.6% 和 76.5% 的准确率,这优于之前最先进的轻量级 ViT。加速器实现是使用 Vivado 高级综合 (HLS) 开发的,并在具有 DeiT 基础模型的 Xilinx ZCU102 FPGA 板上进行了评估。实验结果表明,24 帧/秒 (FPS) 的推理帧速率需要 8 位激活量化,而 30 FPS 则需要 6 位激活量化。
我们的主要贡献总结如下:
• 我们首先构建了具有二值权重和低精度激活的量化Vision Transformer,与其他轻量级 ViT 相比,实现了新的最先进的性能。
• 我们提出了 VAQF,一个指导量化训练和 FPGA 映射的全自动框架。给定目标frame rate,VAQF 为直接软件和硬件实现生成所需的量化精度和加速器描述。
• 我们设计了分层优化方案,并利用全面的FPGA优化技术,充分挖掘量化ViT模型的性能最大化和实时执行的数据效率、执行并行性和资源利用率。
本文的其余部分安排如下。第二节讨论了ViT压缩和硬件推理加速的相关工作。第三部分提供了 VAQF 的总体流程。第四节介绍了 ViT 量化方法,第五节介绍了在 FPGA 上进行量化的 ViT 加速的实现细节。第六节报告了实验结果。最后,第七节总结了论文。
II. Related Work
II.A Vision Transformers
II.B Transformer Quantization
NLP Transformer quantization …
However, all of them are designed for NLP, not for the computer vision tasks. The most recent work [25] evaluates the post-training quantization on ViT and achieves comparable performance with full-precision ViT. However, they just push the compression ratio to 4× (i.e. 8-bit) and the method is not tailored for acceleration on hardware like FPGAs.
II.C Lightweight ViTs
与 CNN 不同,ViT [11] 通常更繁琐且计算量更大。 因此,最近,许多研究试图使 ViT 轻量级和高效。 这些工作通常会修改 ViT [39] 的架构,并将 CNN 的图像特定归纳偏差引入 ViT [42]、[46]、[5],以减少参数的数量和复杂性。
(列举了现有的一些工作)
所有这些方法都大量修改了标准 ViT 的架构,而我们的量化 ViT 仍然保持原始网络架构。
II.D Transformer Acceleration on FPGAs
模型压缩技术已被应用并针对硬件上的Transformer加速进行了调整。 [18] 中的方法利用块循环结构进行权重表示,并将 FC 层中的矩阵向量乘法转换为 FPGA 上的 FFT/IFFT 计算。基于块的权重修剪被应用于具有块平衡稀疏性的 [31] 和具有列平衡块稀疏性的 [29] 中的Transformer。这些方法中的平衡意味着每个权重块中的稀疏行数或列数相同,或者每列的稀疏块数保持相同。这有助于充分利用计算资源和硬件实现的高吞吐量。
虽然剪枝需要平衡稀疏性以提高资源使用效率,但量化自然对 FPGA 实现更友好。 [22] 中的方法在 BERT 的不同部分采用 8 × 4 位和 8 × 8 位量化。
VAQF 与以往工作的不同之处在于以下几个方面:1)量化过程由编译步骤指导,该编译步骤在给定目标帧率的情况下确定所需的激活精度; 2)激活量化的精度选择范围更广,以满足特定的实时帧率要求。
III. VAQF Overview
一直提到帧速率(frame rate, FPS),是什么?
参见 https://towardsdatascience.com/no-gpu-for-your-production-server-a20616bb04bd
感觉就是每秒处理几张图像。
图 1 展示了构建基于 FPGA 的 ViT 推理加速器的 VAQF。 ViT 结构和所需的帧速率(目标 FPS)作为输入信息提供。权重为binary,执行编译步骤以确定加速器设置激活所需的精度以满足 FPS 目标。特别是对于激活精度,可以推断出一组加速器参数,从而可以提前估计整体资源利用率和推理性能。如果估计的帧率达到目标,则相应的激活精度和加速器设置也就同时确定。在软件方面,这种激活精度指导使用 PyTorch 库进行量化,如第 IV 节所述,量化后的 ViT 参数被发送到 FPGA 平台以进行模型推理。在硬件方面,加速器采用参数设置,如第五节所述。这个编译步骤需要几分钟到几个小时,具体取决于目标帧率、模型层数和层尺寸等因素。与需要数天训练的量化相比,编译时间很小。
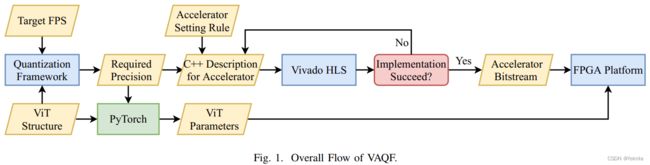
The accelerator description in C++ format is then generated and synthesized with the Vivado HLS tool. 设置加速器参数的规则包括在特定精度下最大化计算并行度的初始设置,以及如果 Vivado 实现因布局或布线问题而失败时的参数调整。参数可能会稍微调整一次或两次,成功的实现会生成要部署在 FPGA 上的比特流文件。加速器的synthesis和implementation需要几个小时,与量化训练相比也很小。
此流程的关键是确定所需的激活精度。For a baseline accelerator,16 位定点数用于表示 32 位浮点参数和未量化模型的激活,而不会引入精度损失。因此,激活精度将从 1 到 16 位范围内选择,以获得比基线设计更高的吞吐量。由于帧率与所有模型层的总推理时间呈倒数关系,因此最大化帧率相当于最小化模型推理时间。推理时间的计算将在第 V-C3 节中详细说明。假设激活精度为 1 位,即权重和激活都是binary的,则可以获得 ViT 结构的理论最大帧速率,用 FRmax 表示。对于给定的目标帧速率 FRtgt,首先通过比较 FRtgt 和 FRmax 来评估加速器实现的可行性。 若FRtgt ≤ FRmax,则支持不低于FRtgt帧率的加速器是可以实现的,通过二分查找过程找到合适的精度。选择范围为 1 到 16 位,最多可进行四轮搜索以找到所需的精度。此外,如果存在多个帧率目标,则可以评估所有可能的精度。
IV. ViT Quantization Method
IV.A Preliminary: Vision Transformer
本节回顾了ViT的结构。
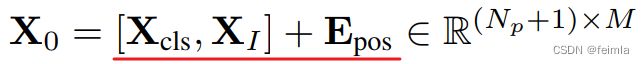
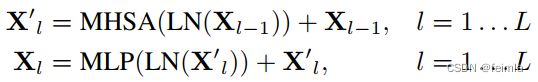
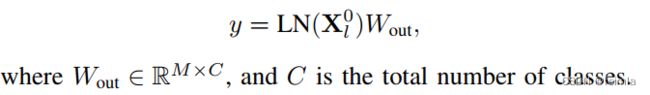
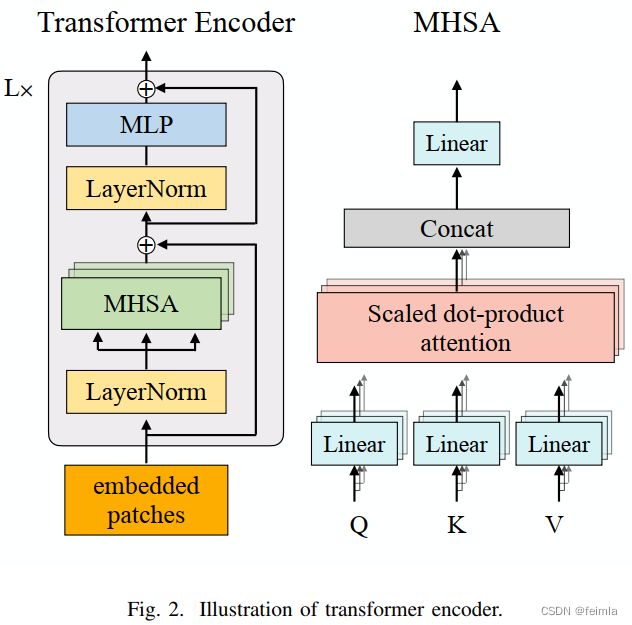
IV.B ViT Quantization
权重二值化,并降低activation的精度,以实现efficiency和accuracy的trade-off。
Binary Weights
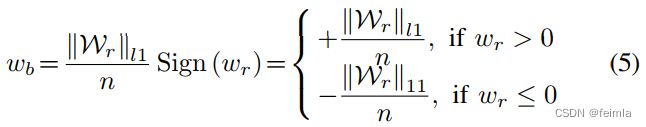
L1范数是向量中各个元素绝对值之和。量化的结果是矩阵的元素绝对值的平均值,1个权重矩阵的所有元素都变成正的或负的这个平均值。
Progressive Binary Training
Specifically, during the training process, we randomly select p% elements in W r W_r Wr, and only binarize these selected elements while keep other elements full-precision. p% is set to 0% at the beginning of the training, then it grows linearly with the increase of training epoch, and achieves 100% when the training process is completed. Therefore, W p W_p Wp consists of both binary weights and real-value weights during the training process.
Implementation Details
第一层patch embedding和输出head(输入输出)不做量化,只在encoder里量化权重和激活函数(attention和MLP)。
三步训练过程: 1)从头开始训练一个全精度的 ViT 并获得实值参数;2)通过渐进式二进制训练对全精度ViT进行微调,以获得具有二进制权重和全精度激活的ViT;3) 微调二元权重模型,以量化activation。
V. Vision Transformer Acceleration on Hardware
在本节中,我们首先讨论 ViT 层中不同类型计算的优化技术(第 V-A 和 V-B 节),然后提供在给定模型结构和所需帧速率的情况下优化加速器参数的详细流程(第 V-C 节)。
V.A Compute Engine for Fully-Connected and Attention Layers
ViT加速在FPGA上的实现细节如图3所示,变量和参数的符号如表1所示。由于FPGA的存储和计算资源有限,采用loop tiling技术把每层的输入、权重、输出分割为tiles,图 3(a) 中显示了未量化层的tiling作为示例。


ViT 中计算最密集的层包括存在于多层感知器 (MLP) 模块和多头注意力模块中的 FC 层,以及出现在多头注意力模块中的scaled dot-product attention layers。这两种层的主要计算都是矩阵乘法。虽然 FC 层只执行一次矩阵乘法,但多头注意力会并行重复计算多次,因此加速器的设计使得计算可以跨 Ph 个注意力头并行执行。为了使设计也兼容 FC 计算,FC 层中的 N 个输入通道被分成 Nh 组,其中的 Ph 个组由计算引擎一次同时处理。添加了一个控制信号来指示当前层是否是多头注意力。对于多头注意力,结果的 Nh 个头保持原样,而对于 FC 层,来自 Nh 个输入通道组的这些结果相加,使每个输出通道的最终结果从所有输入通道累积。
这两类层的主要计算流程如图 3(b) 所示。 L1 下的循环 L2、L3、L4 被展开和流水线化,以便计算引擎可以并行管理 Tm·Ph·Tn multiply-accumulate (MAC) 操作。For illustration simplicity of the MAC operation with the input and weight, the head and the input channel dimensions are shown separately. 图 3© 提供了一个有或没有量化的 ViT 层的处理流程。计算引擎所需的加速器参数包括Tm(Tmq)、Tn(Tnq)、G(Gq)和Ph,其设置和调整在V-C节中详细说明。高精度的未量化计算由 FPGA 上的 DSP 资源管理,而量化计算可以由 LUT 管理的加法或减法代替,因为权重值被二值化为 +1 或 -1。
V.B Processing of the Other Layers in Vision Transformer
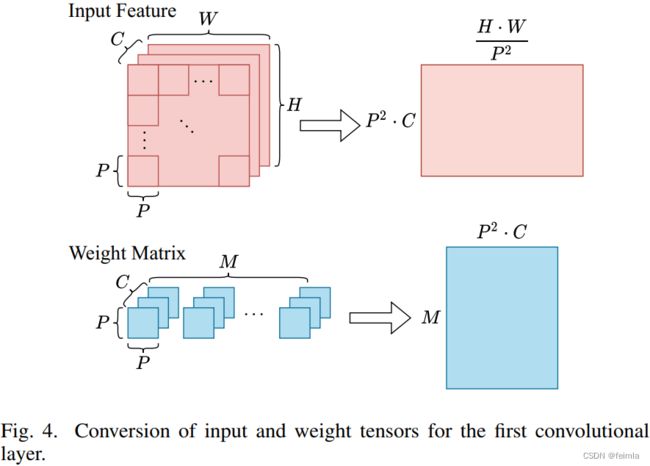
除了 MLP 和多头注意力模块中的矩阵乘法之外,ViTs 还包含卷积、scaling、softmax、激活、归一化和skip-connection操作。 ViT 的第一层是一个可以转换为 FC 层的卷积层,因为它的内核大小和步幅与patch大小 P 相同,这意味着当权重内核滑过输入特征图,如图 4 所示,其中 C、H 和 W 表示输入通道的数量,即原始输入特征的高度和宽度。scaling、softmax 和 GELU 激活操作在 FPGA 的主机 CPU 上执行,与矩阵乘法相比,这为嵌入式 FPGA 引入了非常小的延迟开销。
- 归一化层和 Skip-Connection 的处理:在 ViTs 中,层归一化应用在每个多头注意力和每个 MLP 模块的开头,并且there is an identity skip-connection linking the input activations of each normalization layer and the output activations of the subsequent module,从图 2 可以看出。在层的顺序处理中,需要存储归一化层的输入以供以后与后面的多头注意力或 MLP 模块的输出相加。由于归一化层不像 FC 层那样计算密集,因此它们的参数和输入没有被量化,而是保持更高的精度,即硬件上的 16 位以保持模型精度。因此,需要两个数据传输端口,一个用于归一化的输入,存储为非量化数据,另一个用于归一化的输出,也是后续 FC 层的输入,存储为量化数据。需要强调的是,the data transfer port for quantized FC inputs is necessary to minimize the input loading time for the FC layer as the input tiles would be loaded multiple times in the matrix multiplication with loop tiling.
V.C Design of FPGA-Based Vision Transformer Accelerator
在构建支持特定帧率的 ViT 加速器之前,为未量化模型实现基线加速器,其 32 位浮点参数和激活用 16 位定点数表示,以降低计算和存储资源的使用率,同时不降低精确度。让我们将基线设计的优化参数表示为 Tmbase、Tnbase 和 Gbase。这些参数被视为寻找所需激活精度和优化 ViT 加速器参数的起点。
提供目标帧率,VAQF 将确定适当的激活精度,这是一个逆过程,因为激活精度直接影响加速器设置,从而影响实际帧率。以下对硬件实现细节的讨论是基于特定的激活精度,但这并不意味着在第一步就已经确定了合适的精度。相反,它在资源利用率和推理性能方面的分析后发现了几个可能的精度。
-
Data Packing:数据打包技术用于减少block RAM (BRAM) 的使用以及片外存储器 (DDR) 和片上存储器 (BRAM) 之间的数据传输延迟。尽管 Xilinx FPGA 上的每个 BRAM 都可以容纳 18k-bit 数据,但整个 BRAM 的空间可能没有得到充分利用,导致 ViT 加速实现中的 BRAM 使用率很高。这主要是由于循环流水线和展开需要将每个相关数据数组划分为多个较小的数组。数据打包可以通过将多个低精度数字连接为一个数字来缓解此问题。当data packing factor为 G 时,整体 BRAM 使用量最多可减少 G 倍,输入加载和输出存储的时钟周期数也可减少 G 倍。
FPGA上的大小为Sport的每个 AXI 端口可以容纳 G 个未量化数据或 Gq 个量化数据。如果 Sport = 64,那么对于我们基线设计中使用的 16 位数据,G = 4,如果量化精度为 8 位,则 Gq = 8。一个特殊情况是当 Sport 不能被量化值的比特长度精确划分时。以 6 位量化精度为例, G q = ⌈ 64 / 6 ⌉ = 10 G_q = \lceil 64/6\rceil = 10 Gq=⌈64/6⌉=10,64 位中只有 60 位被利用。Data packing is performed in the input channel dimension of the weights and input activations, and in the output channel dimension of the output activations. It is not displayed in Section 3(b) for illustration simplicity of MAC operation. -
Determing Parameters for Best Computation Parallelism:尽管ViT模型的大部分层都进行了量化,但第一层和最后一层没有量化以更好地保持模型精度,并且加速器计算引擎仍然需要处理未量化的数据。因此,我们有两组加速器参数需要确定,即未量化层的 Tm、Tn 和 G,以及量化层的 Tmq、Tnq 和 Gq,而参数 Ph 在两种情况下都保持不变。 ViT 层是一一处理的,因此加速器不会同时执行非量化计算和量化计算。尽管如此,无论层是否被量化,都可以使用相同的 BRAM 用于输入、权重和输出数据。因此决定相关的加速器参数尽最大努力利用 BRAM。
在创建支持量化的 ViT 加速器时,首先将未量化层的加速器参数设置为 Tn = Tnbase 和 G = Gbase,并且 Tm 最初设置为接近 Tmbase并且可以被 G 和 Gq整除的值。如第 V-C1 节所述,Gq 直接根据 Sport 和所需的量化精度计算得出。然后通过 T n q = ⌊ T n ⋅ G q G ⌋ T_n^q = \lfloor T_n · \frac{G_q}{G} \rfloor Tnq=⌊Tn⋅GGq⌋ 计算 Tnq,以获得量化数据的 BRAM 的最大利用率。 Ph 通常是一个可以精确除以 Nh 的值。例如,如果 Nh = 6,则 Ph 设置为 3;如果 Nh = 8 或 Nh = 12,则 Ph 为 4。在下一步中,将 Tmq 设置为等于 Tm,并使用 Vivado HLS 作为初始尝试综合和实施具有所有这些参数的硬件设计。如果 FPGA 板由于布局或布线问题(通常是由于 LUT 的过度使用而导致)无法适应这种设计,则调整 Tm 和 Tmq 以适应电路板并最大限度地减少整体推理延迟。对于低激活精度,降低 Tm 并增加 Tmq,直到 FPGA 资源被充分利用。在这个过程中,为了方便输出存储,Tm 和 Tmq 都被保存为可以被 G 和 Gq 精确除的值。 -
Performance Analysis and Objective Function:本节等式中的主要变量在表 I 中进行了解释。对于 ViT 中的一层 i,输入tile加载、权重tile加载和输出tile存储所需的时钟周期数计算为
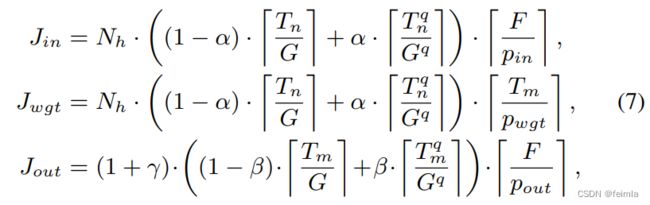
如果输入和权重被量化,α为1,否则为 0;如果输出被量化,β为1,否则为 0;如果当前层是多头注意力层,则 γ 为 Nh - 1,否则为 0。此外,一组tile计算的时钟周期数是

tile的数据加载和计算用双缓冲技术同时进行,以将数据传输与计算重叠。该进程的时钟周期数为
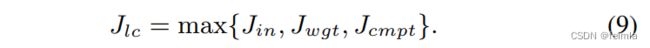
并且为了获得输出结果的累加,这个过程会被执行多次。计算整个output tile的时钟周期数是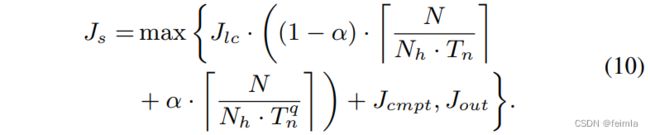
因此,a ViT layer i 的全部时钟周期数为
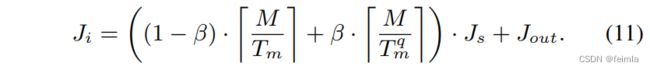
使用双缓冲,输入、权重和输出tiles 的 18k-bit BRAM 的 usage由下式给出
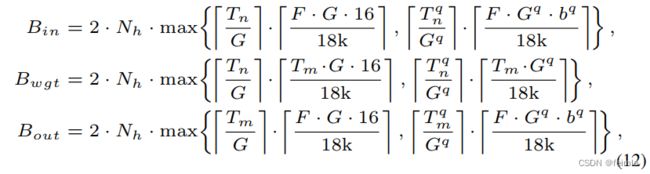
其中 bq 是量化中的激活位宽。至于DSP利用率,由于每个DSP可以处理一个16位输入和16位权重的未量化MAC操作,所以使用的DSP数量由Tm·Ph·Tn计算,以并行执行Tm·Ph·Tn MAC操作。
最后,我们的目标函数可以写成
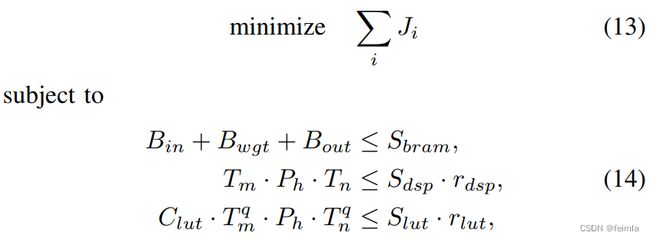
其中 rdsp 和 rlut 分别是用于 MAC 操作的 DSP 和 LUT 的最大比率,而 Clut 是一个带有量化操作数的 MAC 的 LUT 成本。 如第三节所述,最小化整体模型延迟等同于最大化帧速率。 如果最大帧率不低于目标帧率,则具有相应激活精度和参数设置的加速器是可行的。
VI. Evaluation
VII. Conclusion
这项工作提出了一个称为 VAQF 的框架,用于在所需帧速率下自动构建具有二值权重和低精度激活的 ViT 推理加速器。VAQF 首先进行编译,通过分析资源利用率和推理性能,使用与计算并行性相关的加速器设置来确定所需的激活精度。然后对于加速器的实现,设计了一个通用的 FC 层和多头注意力层的计算引擎,并将量化计算替换为使用 LUT 实现的加法和减法。数据打包和循环流水线等优化技术与不同的因素一起用于非量化和量化计算,以提高计算并行性和内存利用效率。基于DeiT模型的实验结果表明,8位激活量化加速器的推理速度达到24.8 FPS,6位激活量化加速器达到31.6 FPS,可以满足各种实时性要求。