Caffe 训练记录
1.训练一个结合分类学习和相似度学习的多任务网络,一开始使用GPU训练,在第一次迭代时便出现了out of memory的错误。于是减小了了batch size,但是效果还是一样,在第三四次迭代时同样报错。后来改用CPU训练(因为电脑内存有8Gb,而显存只有2Gb),发现caffe每次迭代时都会读入图片,当所有训练图片全部读入时,基本上内存不在上升了。注意,Test阶段也会读入图片。最终内存占用在80%左右。
2.blas选择:caffe默认的是atlas,后来尝试了intel 的mkl,发现在使用atlas训练是CPU占用只有100%(电脑CPU为i5,四核),在使用mkl训练是CPU占用高达380%,训练速度明显加快,开始内存占用率也不断飙升。
3.第一次训练出现loss值发生震荡,后来发现训练数据出错了,我把标签从1开始标注的,应该从0开始!!!(训到一半发现不对终止了)

图中红色线为精度,蓝色线为损失值。
solver参数:
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
stepsize: 25000
max_iter: 50000
momentum: 0.9
weight_decay: 0.00054.第二次训练:
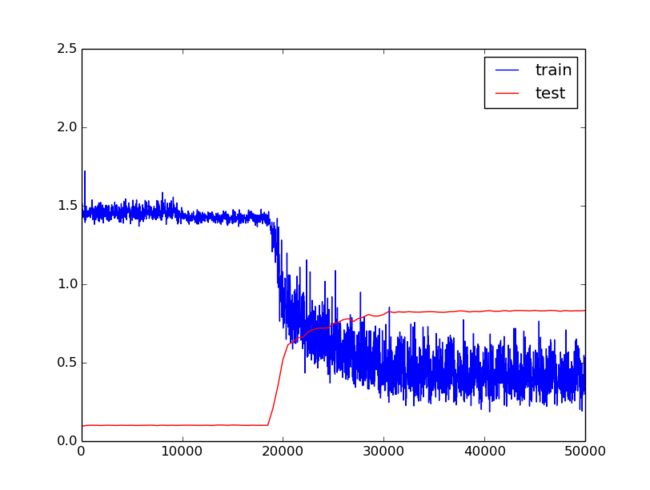
训练参数:
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 10000
display: 20
max_iter: 50000
momentum: 0.9
weight_decay: 0.0005这次训练迭代了5w次,但是真正有效果的只有 1.8w-2w 和 2w-3w 这两个阶段,此时学习速率为0.001和0.0001。且后期loss值震荡的幅度变大,总体趋势不变。此次训练最终精度为0.83 。
I1113 17:05:13.096009 5943 solver.cpp:317] Iteration 50000, loss = 0.443654
I1113 17:05:13.096043 5943 solver.cpp:337] Iteration 50000, Testing net (#0)
I1113 17:06:30.027653 5943 solver.cpp:404] Test net output #0: cls_accuracy = 0.8310555.第三次训练

训练参数:
test_iter: 20
test_interval: 100
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
stepsize: 25000
display: 100
max_iter: 50000
momentum: 0.9
weight_decay: 0.0005参数主要改动:1.初始学习速率为0.001(这里主要是由于第二次训练前期根本没效果)2.增大了训练时的batch_size,前两次为32,第三次为100。可能正是由于batch_size的增大使得训练效果提升,loss值曲线震荡减弱(这里还有一个因素,增大了display值)。
根据这次训练,可以发现在数据量不大的情况(1w张训练图片),2w次迭代基本稳定了。
最终训练结果:
I1120 07:12:12.403172 2612 solver.cpp:317] Iteration 50000, loss = 0.0262005
I1120 07:12:12.403241 2612 solver.cpp:337] Iteration 50000, Testing net (#0)
I1120 07:13:34.096788 2612 solver.cpp:404] Test net output #0: cls_accuracy = 0.907
I1120 07:13:34.096894 2612 solver.cpp:404] Test net output #1: cls_loss = 0.355025 (* 0.6 = 0.213015 loss)
I1120 07:13:34.096915 2612 solver.cpp:404] Test net output #2: sim_loss = 0.73487 (* 0.4 = 0.293948 loss)改用Oxford 102类数据集
原始图片大约有8190张,每类至少有40张图片。我是这样处理的:每类图片抽取20%作为验证集,其余80%为训练集。
1.第一次训练
网络参数:
batch:32
分类损失函数weight:0.6超参数
test_iter: 64
test_interval: 100
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
stepsize: 25000
display: 50
max_iter: 50000
momentum: 0.9
weight_decay: 0.0005最终结果:
I1130 13:44:24.584110 16849 solver.cpp:317] Iteration 50000, loss = 0.0190341
I1130 13:44:24.584166 16849 solver.cpp:337] Iteration 50000, Testing net (#0)
I1130 13:44:30.371933 16849 solver.cpp:404] Test net output #0: cls_accuracy = 0.828125
I1130 13:44:30.372097 16849 solver.cpp:404] Test net output #1: cls_loss = 0.91818 (* 0.6 = 0.550908 loss)
I1130 13:44:30.372126 16849 solver.cpp:404] Test net output #2: sim_loss = 3.76009 (* 0.4 = 1.50404 loss)
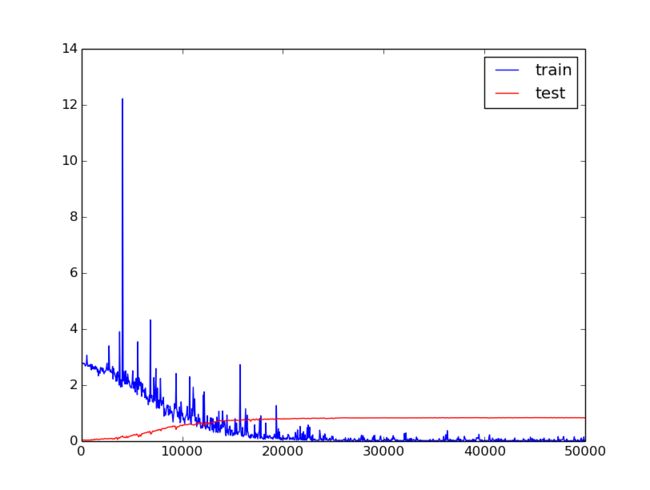
这里面有些奇怪的loss值…
这是别人的结果:(差距有点大)
I0215 15:28:06.417726 6585 solver.cpp:246] Iteration 50000, loss = 0.000120038
I0215 15:28:06.417789 6585 solver.cpp:264] Iteration 50000, Testing net (#0)
I0215 15:28:30.834987 6585 solver.cpp:315] Test net output #0: accuracy = 0.9326
I0215 15:28:30.835072 6585 solver.cpp:251] Optimization Done.
I0215 15:28:30.835083 6585 caffe.cpp:121] Optimization Done.2.第二次训练
这次只改了分类损失函数的权重,增加为0.9。
训练结果:

I1130 18:59:06.483604 18297 solver.cpp:317] Iteration 50000, loss = 0.0058511
I1130 18:59:07.547617 18297 solver.cpp:337] Iteration 50000, Testing net (#0)
I1130 18:59:13.265532 18297 solver.cpp:404] Test net output #0: cls_accuracy = 0.919922
I1130 18:59:13.265609 18297 solver.cpp:404] Test net output #1: cls_loss = 0.436957 (* 0.9 = 0.393261 loss)
I1130 18:59:13.265631 18297 solver.cpp:404] Test net output #2: sim_loss = 10.1873 (* 0.1 = 1.01873 loss)
I1130 18:59:13.265641 18297 solver.cpp:322] Optimization Done.
I1130 18:59:13.265647 18297 caffe.cpp:222] Optimization Done.3.第三次训练
这次将分类损失函数的权重设为一个极端,1.0

I1130 22:43:48.455011 18645 solver.cpp:317] Iteration 50000, loss = 2.95808e-05
I1130 22:43:48.455075 18645 solver.cpp:337] Iteration 50000, Testing net (#0)
I1130 22:43:54.192484 18645 solver.cpp:404] Test net output #0: cls_accuracy = 0.926758
I1130 22:43:54.192545 18645 solver.cpp:404] Test net output #1: cls_loss = 0.482888 (* 1 = 0.482888 loss)
I1130 22:43:54.192555 18645 solver.cpp:404] Test net output #2: sim_loss = 51.5887
I1130 22:43:54.192564 18645 solver.cpp:322] Optimization Done.
I1130 22:43:54.192569 18645 caffe.cpp:222] Optimization Done.4.第四次训练
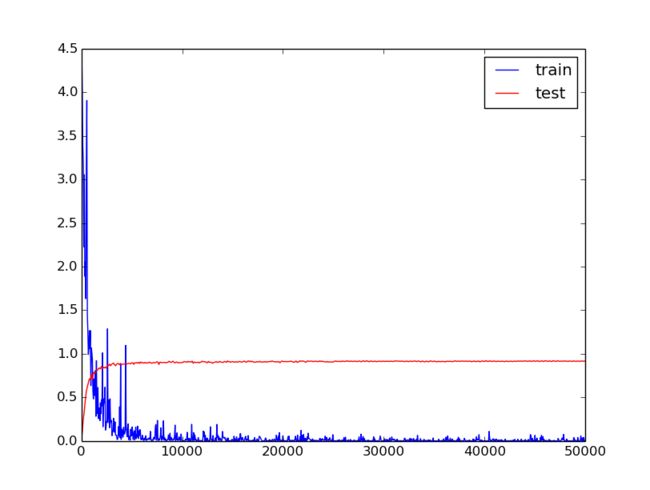
I1202 13:39:32.073395 22096 solver.cpp:317] Iteration 50000, loss = 0.0018768
I1202 13:39:32.073449 22096 solver.cpp:337] Iteration 50000, Testing net (#0)
I1202 13:39:37.829488 22096 solver.cpp:404] Test net output #0: cls_accuracy = 0.916992
I1202 13:39:37.829610 22096 solver.cpp:404] Test net output #1: cls_loss = 0.440948 (* 0.95 = 0.418901 loss)
I1202 13:39:37.829622 22096 solver.cpp:404] Test net output #2: sim_loss = 13.0659 (* 0.05 = 0.653293 loss)
I1202 13:39:37.829632 22096 solver.cpp:322] Optimization Done.
I1202 13:39:37.829637 22096 caffe.cpp:222] Optimization Done.度量学习(Metric Learning)
在以前的基础上微调。
1.第一次训练
test_iter: 50
test_interval: 100
base_lr: 0.00001
lr_policy: "step"
gamma: 0.1
stepsize: 20000
display: 50
max_iter: 30000
momentum: 0.9
weight_decay: 0.0005
snapshot: 20000
最终结果
I1220 08:03:54.094050 14448 solver.cpp:317] Iteration 30000, loss = 0.16902
I1220 08:03:54.094084 14448 solver.cpp:337] Iteration 30000, Testing net (#0)
I1220 08:04:30.142140 14448 solver.cpp:404] Test net output #0: contrastloss = 0.118982 (* 1 = 0.118982 loss)
I1220 08:04:30.631690 14448 solver.cpp:322] Optimization Done.
I1220 08:04:30.631724 14448 caffe.cpp:222] Optimization Done.