腾讯魏巍:Eunomia云原生资源编排优化
2022年11月10日,在中国信通院、腾讯云、FinOps产业标准工作组联合发起的《原动力x云原生正发声 降本增效大讲堂》系列直播活动第10讲上,腾讯Light云计算平台负责人魏巍分享了Eunomia云原生资源编排优化实践。本文整理自魏巍的分享。
云上资源优化背景
相较传统的IDC部署方式,容器化部署在物理硬件、操作系统之上增加了一层容器运行时。当前云上部署的APP及二进制等均运行在容器运行时之上,Eunomia编排器的作用范围也在于此。
我们认为,上云的过程中并没有新技术,更多是一种新部署理念的产生。在上云之后,应实现CPU、内存等资源利用率上升,成本大幅下降,然而当前上云时的资源浪费现象十分常见,造成浪费的原因可分为三种。
- 应用资源使用设置不合理
云原生的资源管理方式要求应用在部署之前,需提前设置好CPU、内存、磁盘的最小和最大资源使用量,并且之后不能改动(除非重建所有实例),这就要求应用在正式上线前预估其资源需求。
线上的资源需求可以通过压测来模拟,但难免和实际情况有出入。此外,应用上线之后,其资源使用会随着业务、策略的动态更新而发生变化,因此在创建之初设置的资源使用量并不能很好地反映实际资源需求,容易造成资源浪费或资源不足。
- 同类Pod各项资源有差异
在实际运行过程中,即使是相同的Pod,其CPU、内存、磁盘、网络等监控指标也会有很大的差异,极端情况下相差甚至会高达60%,有时还会有大部分Pod的CPU利用率低、个别Pod的CPU利用率却长期在90%以上的情况产生。对此最稳妥的解决方式是扩容,但这会造成资源的大量浪费。
- 多维度空闲资源碎片化严重
集群在运行一段时间后,随着节点不断上、下架,Pod不断扩、缩容,会有越来越多的空闲资源分散在整个集群中,此类多维度闲散资源通常难以集中并下架,最终会造成资源的浪费。
资源使用的痛点、难点
- 突发流量洪峰导致资源不足
游戏安全服务在正常运行时有着明显的周期性,并且周期与周期之间峰值变化不大,一般情况下晚上九、十点流量最高,后半夜流量最低。但是在某些突发情况下(突发性热点、大型节假日等),服务的请求量会在短时间内大幅上涨,造成资源不足,影响服务正常运行产生告警。
- 资源维度有限
原生的调度策略只基于CPU、内存、磁盘三个维度来判断节点资源是否充足。然而实际情况下,磁盘IO、网络IO、连接数、定时器等资源同样是决定业务是否正常运行的关键,因此资源维度的匮乏会对业务正常的保障造成影响。
为了解决资源浪费与使用时的痛点,业界有诸多不同的解决方案,如HPA、超卖等。
- HPA:基于业务实际运行的性能指标(一般位CPU)自动变更Pod数量;
- 超卖:基于节点监控,按一定比例提升CPU或Mem可分配资源上限;
- 反亲和性:设置Pod反亲和属性,使得相同Pod尽量部署在不同节点,优化均衡性;
- 在离线混部:在同一集群混合部署在离线业务,离线业务在在线业务的低峰期扩容,提高低峰期利用率;
- Deschedule:定期扫描节点资源和部署情况,通过驱逐Pod平均节点负载以及均衡Pod部署;
- Dynamic Scheduler:基于节点实际负载调度Pod,优先调度到低负载节点,优化均衡性;
- 高低水位线:设置高低水位线,扩容时Pod优先调度到负载处于高低水位线之间的节点,缩容时优先部署在低水位线下节点的Pod。

Eunomia的实践经验
Eunomia主要由预测模型、求解器以及调度器三大模块组成。
- 预测模型

对于游戏安全的实时计算业务,资源使用往往具备明显的周期性且周期之间变动不大,因此可以基于Pod的历史监控数据预测未来的资源使用情况,以解决资源设置不合理问题。
- 求解器

如果把预测的Pod模型看做物品、Node看做箱子,那么资源优化问题就可以转化为一个多维度的装箱问题,我们可以从各个角度、根据项目的实际需求来求解最优的装箱方案。
- 调度器

根据求解器给出的部署方案,再结合业务的可调度性和现有集群的部署现状,可以利用Kuhn-Munkres算法优化调度代价,对集群实施离线、实时等调度策略。
整体工作流程预测模型
在做预测之前,首先需要找到模型是什么,这就面临“找到模型基准值”的挑战。
对于实时在线集成业务,由于在成本核算时CPU权重较大,所以这里仅以CPU的利用率来分析模型的基准值。如果业务特征不同、维度不同,则应该采用不同的方式来锚定基准值。
为了达到80%的CPU整机利用率,我们首先采集了各Pod 的95日峰值,并对其进行集中部署。虽然各Pod集中部署在了同一节点,但在实际运行中,由于其CPU并不在同一时刻达到峰值,CPU的整机利用率依旧不达预期,相差达30%。
 Node实测值CPU的整机利用率 < 51%
Node实测值CPU的整机利用率 < 51%
 曲线对比(绿:Node实测值、其他:各Pod曲线)
曲线对比(绿:Node实测值、其他:各Pod曲线)
于是,我们更新使用带时间序列的高维模型(1H),在模型中引入时间维度,可以有效改善错峰情况。
 Node实测值CPU的整机利用率 < 56%
Node实测值CPU的整机利用率 < 56%  曲线对比(红:Node实测值、橙:Pod 95峰值、绿:Pod总和、蓝:Pod平均数总和)
曲线对比(红:Node实测值、橙:Pod 95峰值、绿:Pod总和、蓝:Pod平均数总和)
1H精度下,实际与理论仍有较大差距,所以我们在模型中引入高精度的时间维度,进一步提高精度到10M。
 Node实测值CPU的整机利用率 < 63%
Node实测值CPU的整机利用率 < 63%
 曲线对比
曲线对比
(红:Node实测值、橙:Pod平均数总和、绿:Pod总和、蓝:Pod 95峰值)
虽然精度已进一步提升至10M,聚集性更加明显,但可以看到距离CPU利用率80%的目标值仍有差异。
 相同业务的不同Pod间的细粒度曲线
相同业务的不同Pod间的细粒度曲线
如上图所示,在细粒度的时间维度下,同一个业务不同实例间有着天然的巨大差异。此外,不同母机不尽相同的工况也会使Pod的表现存在差异。也就是说,期望精准的控制Pod是不切实际的。
若业务自身拥有巨大的不确定性,应使用能够削峰的曲线模型,采用中位数的带高精度时间序列的高维模型(10M)无疑可以列入考量。
如下图所示,引入中位数后,消除了Pod的个性化差异,Node实测值已达到77%,初步达成目标要求,如果把目标设定为90%,也可以得到接近的实测值。
 Node实测值CPU的整机利用率 < 77%
Node实测值CPU的整机利用率 < 77%  曲线对比
曲线对比
(绿线:pod 95峰值、橙线:node实测值、黄线:pod中位数、蓝线:pod总和)
预测模型的方法及比较
预测模型旨在基于Pod的历史多个周期资源监控数据,预测下个周期的资源使用数据,求解最优部署方案,有多种方式可以实现。
- 方式一:直接使用历史数据
逻辑简单,可解释性好,但准确率低,相同类型Pod预测结果相同。
- 方式二:周期因子法
逻辑简单,可解释性好,但无法预测趋势,只适合周期性场景,对节假日、活动等特殊场景无法建模。
- 方式三:Prophet
预测准确率高,可综合考虑趋势项、周期项、节假日项等,同时可处理异常值和缺失值。但计算速度慢,预测结果存在波动,鲁棒性较差。
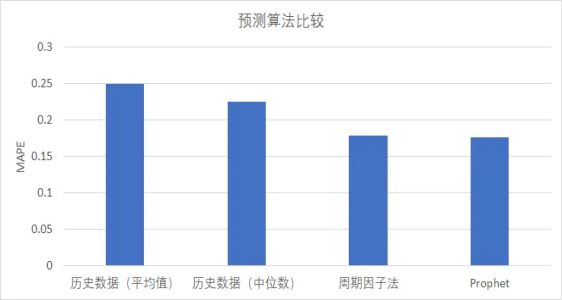
基于MAPE(Mean Absolute Percentage Error)评价指标,对未来两周的CPU进行预测,可以清晰地看到预测数值与实际数值具备很强的相似性
求解器
求解器的目标是把Pod用最优的排列方式部署到Node中,其中Node数量越少越好。与此同时,我们可以把业务调度需求转化为约束条件:
- CPU/Mem/Disk/Net等资源的均衡;
- 对业务进行反相似性和错峰部署;
- 业务自定义的Socket/定时器等资源做管理;
- 小核心/大核心业务的部署策略;
- 亲和性/非亲和性/反亲和性;
- 无损/有损业务的部署方案。
调度器
在得到较好的部署方案后,需要在实践中对现有的集群进行迁移,可以通过三步实现。
- 计算映射关系:计算当前集群的节点和部署方案的映射关系。
- 无损驱逐:将节点上不符合部署方案的Pod驱逐。
- 再调度:新创建的Pod按照调度方案部署到理想的节点。
计算映射关系
计算映射关系的目标是将当前集群节点和部署方案中的节点一一对应,使得对业务影响最小。
- 部署方案中的节点不一定按顺序和部署现状中的节点匹配。
- 业务影响 = Pod调度代价。
- 节点转换到不同部署方案所需的调度代价不同
- 节点调度代价 = 当前多余Pod调度代价总和;
- 多余Pod = 已部署的超出部署方案范围的Pod。
如下图所示,在计算时我们通常将集群节点和部署方案抽象为二分图,将计算映射关系转换成求解二分图的最佳匹配。

其中顶点集是集群节点和部署方案的节点,顶点集中的顶点两两之间各有一条匹配,匹配权重则是节点调度代价,最后形成当前集群节点和部署方案节点的映射关系。
无损驱逐
无损驱逐的目标是将不符合部署方案的Pod驱逐,并保证对业务服务无影响。在做无损驱逐时,服务可被分为无状态服务、弱状态服务及强状态服务三类。
- 无状态服务:Pod立即停止对当前业务没有影响。
- 业务支持灰度;
- 调度时保证部分Pod正常运行(通过设置合理的就绪探针、存活探针判断运行状态)。

- 弱状态服务:Pod立即停止对当前业务有一定影响,但不致命。
- 业务支持灰度;
- 调度时保证部分Pod正常运行(通过设置合理的就绪探针、存活探针判断运行状态);
- 可以在低峰期调度。

- 强状态服务:Pod立即停止对当前业务有影响,并且致命。
- 业务支持灰度;
- 调度时保证部分Pod正常运行(通过设置合理的就绪探针、存活探针判断运行状态);
- 在低峰期调度;
- 设置Prestop回调、捕获处理TERM信号;
- 切断转发到Pod的流量。
再调度
再调度的目标是将新创建的Pod按照部署方案调度到理想的节点,一般基于Scheduling Framework,添加过滤和评分插件实现。
- 过滤:基于资源及部署方案,分别过滤资源不足与不符合方案的节点。
- 评分:优先部署方案内的节点,其次方案外的冗余节点。
成果展示
通过对某一集群做资源编排优化,可以在成本及稳定性等多个方面实现较大提升,如平均CPU利用率峰值可从28%增长至75%,告警可由88个/周降低至3个/周。此外,节点CPU利用率的周峰值均可达到80%以上。
 优化前Vs.优化后
优化前Vs.优化后
 节点部署负载多样
节点部署负载多样
 不同负载节点间部署均衡
不同负载节点间部署均衡
【原动力×云原生正发声降本增效大讲堂】第一期聚焦在优秀实践方法论、资源与弹性、架构设计;第二期聚焦全场景在离线混部、K8s GPU资源效率提升、K8s资源拓扑感知调度主题;第三期邀请4家业界知名企业分享各企业云原生降本增效技术实践,为开发者带来更多样化场景业务下的技术干货。点击『此处』进入活动专题页,带你体验云原生降本增效实践案例、了解如何解决企业用云痛点、掌握降本增效关键技能……