ResNet(残差网络模型)原理解读-包括residual block与BN原理介绍
《Deep Residual Learning for Image Recognition》
《Identity Mappings in Deep Residual Networks》
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。
1.论文解读
Abstract
提出残差学习的框架来减轻深层网络训练的难度:重新构建了网络以便学习包含推理的残差函数,而不是学习未经过推理的函数。实验结果显示,残差网络更容易优化,并且加深网络层数有助于提高正确率。
网络能表达的深层特征是许多视觉识别任务的关键。残差网络的深度更深。也取得了比较好的效果。
Introduction
更深的网络导致分类效果不好:随着网络层数的增加,训练的问题随之凸显。比较显著的问题有梯度消失与梯度爆炸,这会在一开始就影响收敛。收敛的问题可以通过正则化来得到部分的解决。
退化现象:在深层网络能够收敛的前提下,随着网络深度的增加,正确率开始饱和甚至下降,称之为网络的退化(degradation)问题。 如下图,56层的网络相对于20层的网络,不管是训练误差还是测试误差都显著增大。

网络的退化说明不是所有的系统都很容易优化。在极端条件下,如果增加的所有层都是前一层的直接复制( y=x),这种情况下深层网络的训练误差应该和浅层网络相等。因此,网络退化的根本原因还是优化问题。 为了解决优化的难题,作者提出了残差网络。在残差网络中,不是让网络直接拟合原先的映射,而是拟合残差映射。

残差网络可以理解为在前向网络中增加了一些快捷连接(shortcut connections)。这些连接会跳过某些层,将原始数据直接传到之后的层。新增的快捷连接不会增加模型的参数和复杂度。
使用残差块后的结果:随着网络的不断加深,效果变的更好。

1. Shortcut Connections(快捷连接)
高速网络(highway networks)和快捷连接有相似之处,但是高速网络中含有参数。高速网络中的gate在训练过程中可能关闭,相反,残差网络中的连接不会关闭,残差函数可以被学习。
2. Deep Residual Learning(深度残差)
左边是VGG-19的模型,中间是原始网络,右边是残差网络。
测试18层和34层的ResNet。34层的训练和测试误差都要比18层的小。这说明网络退化的问题得到了部分解决,通过加深网络深度,可以提高正确率。注意到18层的plainnet和18层的ResNet可以达到相近的正确率,但是ResNet收敛更快。

3. Deeper Bottleneck Architectures.(residual block)
右图加入了1*1卷积进行降维升维

总结
ResNet和Highway Network的思路比较类似,都是将部分原始输入的信息不经过矩阵乘法和非线性变换,直接传输到下一层。这就如同在深层网络中建立了许多条信息高速公路。ResNet通过改变学习目标,即不再学习完整的输出F(x),而是学习残差H(x)−x,解决了传统卷积层或全连接层在进行信息传递时存在的丢失、损耗等问题。通过直接将信息从输入绕道传输到输出,一定程度上保护了信息的完整性。同时,由于学习的目标是残差,简化了学习的难度。
2.residual block
首先,为什么会有resnet?
当模型深度增加时,模型的效果并不会变好(网络退化)。
那为什么网络会发生退化呢?
过拟合(overfitting)吗?(网络模型过度拟合训练数据),显然不是,现在的问题是深层网络的训练误差与测试误差都很大,而过拟合的现象是训练误差小、测试误差大。
梯度弥散/爆炸吗?反向传播时梯度一直大于1,经过层层回传,梯度将会呈几何倍数增长,这就是梯度爆炸现象;正向传播时如果梯度一直小于1,那么梯度会呈几何倍数下降,直到0,这就是梯度消失(弥散)现象。也不是因为这个原因,因为BN层的作用,BN层的本质是控制每层输入的数据分布,所以梯度问题已经被解决了。
那退化现象的原因是什么呢?
按常理,网络模型深度越深,模型的效果应该越来越好,但是随着堆叠一层又一层网络,效果似乎越来越差了,那什么都不做不就好了吗。
ops! 什么都不做!!!
由于非线性激活函数ReLU的存在,导致输入输出不可逆,造成了模型的信息损失,更深层次的网络使用了更多的ReLU函数,导致了更多的信息损失,这使得浅层特征随着前项传播难以得到保存,那么有没有什么办法能保留浅层网络提取的一些特征呢?
恒等映射(y=x),简单来说就是让模型在向更深层次前进的过程中,还有保留特征的能力,以至于不会发生退化现象。
ResNet的核心思想就是引入一个恒等快捷连接(identity shortcut connection),直接跳过一个或者多个层。
结构如下:左边的残差结构是针对层数较少网络,例如ResNet18层和ResNet34层网络。右边是针对网络层数较多的网络,例如ResNet101,ResNet152等。右侧的残差结构能够减少网络参数与运算量(1*1卷积的降维与升维)。注意需要保证主分支与shortcut分支的输入特征矩阵相同(图中输出可以相加)。
残差块原理:
原先的网络输入x,可以拟合输出为F(x),希望输出H(x)。现在我们令H(x)=F(x)+x,那么我们的网络就只需要学习输出一个残差F(x)=H(x)-x。两层全连接层学习到的映射为H(x),也就是说这两层可以渐进拟合H(x)。假设 H(x)与x维度相同,那么拟合 H(x) 与拟合残差函数 H(x)-x 等价,令残差函数 F(x)=H(x)-x,则原函数变为 F(x)+x ,于是直接在原网络的基础上加上一个跨层连接,这里的跨层连接也很简单,就是 将x的恒等映射传递过去。与其让F(x)直接学习潜在的映射,不如去学习残差H(x)−x,即F(x):=H(x)−x,这样原本的前向路径上就变成了F(x)+x,用F(x)+x来拟合H(x)。作者认为这样可能更易于优化,因为相比于让F(x)学习成恒等映射,让F(x)学习成0要更加容易。
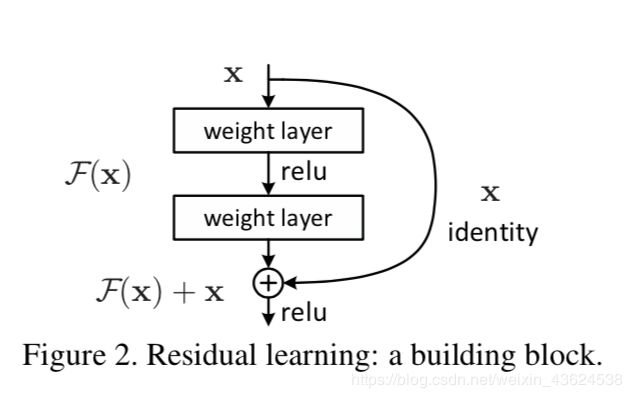
自适应深度:网络退化问题就体现了多层网络难以拟合恒等映射这种情况,也就是说 H(x)难以拟合 x ,但使用了残差结构之后,拟合恒等映射变得很容易,直接把网络参数全学习到为0,只留下那个恒等映射的跨层连接即可。于是当网络不需要这么深时,中间的恒等映射就可以多一点,反之就可以少一点;
差分放大器:假设最优 H(x)更接近恒等映射,那么网络更容易发现除恒等映射之外微小的波动;
缓解梯度消失:针对一个残差结构对输入 x 求导就可以知道,由于跨层连接的存在,总梯度在 F(x) 对 x 的导数基础上还会加1;
普通网络与深度残差网络的最大区别在于,深度残差网络有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这些支路就叫做shortcut。传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
3.BN(batch normalization)
使一批(batch)的feature map满足均值为0,方差为1的数据分布。具体可以看看这篇博客:Batch Normalization详解以及pytorch实验
4. 网络结构:

仅作为学习记录,侵删。