机器学习模型融合方法综述
每天给你送来NLP技术干货!
来自:NLP情报局
我理解的Kaggle比赛中提高成绩主要有3个地方:1)特征工程,2)调参,3)模型融合。
之前每次打比赛我都只做了前两部分,最后的模型融合就是简单的加权平均,对于进阶的Stacking方法一直没尝试,最近摸索了一下还是把Stacking方法给弄懂了。下面我重点讲解Stacking,Bagging和Boosting有很多权威的好教程,所以不详细介绍。
最早的Stacking思想早些年就有论文发表,但是应用Stacking方法到比赛中的相关文章还是少之甚少。本文不涉及到各个算法原理层次的深度,目的在于从宏观上帮助理解这几个模型融合方法。
一、Voting
模型融合其实也没有想象的那么高大上,从最简单的Voting说起,这也可以说是一种模型融合。
假设对于一个二分类问题,有3个基础模型,那么就采取投票制的方法,投票多者确定为最终的分类。
二、Averaging
对于回归问题,一个简单直接的思路是取平均。稍稍改进的方法是进行加权平均,权值可以用排序的方法确定。
举个例子,比如A、B、C三种基本模型,模型效果进行排名,假设排名分别是1,2,3,那么给这三个模型赋予的权值分别是3/6、2/6、1/6
这两种方法看似简单,其实后面的高级算法也可以说是基于此而产生的,Bagging或者Boosting都是一种把许多弱分类器这样融合成强分类器的思想。
三、Bagging
Bagging就是采用有放回的方式进行抽样,用抽样的样本建立子模型,对子模型进行训练,这个过程重复多次,最后进行融合。大概分为这样两步:
1.重复K次
1)有放回地重复抽样建模
1)训练子模型
2.模型融合
1)分类问题:voting
2)回归问题:average
Bagging算法不用我们自己实现,随机森林就是基于Bagging算法的一个典型例子,采用的基分类器是决策树。R和python都集成好了,能直接调用。
四、Boosting
Bagging算法可以并行处理,而Boosting的思想是一种迭代的方法,每一次训练的时候都更加关心分类错误的样例,给这些分类错误的样例增加更大的权重,下一次迭代的目标就是能够更容易辨别出上一轮分类错误的样例。
最终将这些弱分类器进行加权相加。引用加州大学欧文分校Alex Ihler教授的两页PPT:


同样地,基于Boosting思想的有AdaBoost、GBDT等,在R和python也都是集成好了直接调用。
PS:理解了这两点,面试的时候关于Bagging、Boosting的区别就可以说上来一些,问Randomfroest和AdaBoost的区别也可以从这方面入手回答。
也算是留一个小问题供大家思考:
随机森林、Adaboost、GBDT、XGBoost的区别是什么?
五、Stacking
Stacking方法其实弄懂之后应该是比Boosting要简单的,毕竟小几十行代码可以写出一个Stacking算法。我先从一种“错误”但是容易懂的Stacking方法讲起。
Stacking模型本质上是一种分层的结构,这里简单起见,只分析二级Stacking.假设我们有3个基模型M1、M2、M3。
1)基模型M1,对训练集train训练,然后用于预测train和test的标签列,分别是P1,T1
对于M2和M3,重复相同的工作,这样也得到P2,T2,P3,T3。
2)分别把P1,P2,P3以及T1,T2,T3合并,得到一个新的训练集和测试集train2,test2。

3)再用第二层的模型M4训练train2,预测test2,得到最终的标签列。

Stacking本质上就是这么直接的思路,但是这样肯定是不行的,问题在于P1的得到是有问题的,用整个训练集训练的模型反过来去预测训练集的标签,毫无疑问过拟合是非常非常严重的。
因此现在的问题变成了如何在解决过拟合的前提下得到P1、P2、P3,这就变成了熟悉的节奏——K折交叉验证。我们以2折交叉验证得到P1为例,假设训练集为4行3列

将其划分为2部分:

用train_a训练模型M1,然后在train_b上进行预测得到preb3和pred4:

在train_b上训练模型M1,然后在train_a上进行预测得到pred1和pred2:

然后把两个预测集进行拼接:

对于测试集T1的得到,有两种方法。注意到刚刚是2折交叉验证,M1相当于训练了2次,所以一种方法是每一次训练M1,可以直接对整个test进行预测,这样2折交叉验证后测试集相当于预测了2次,然后对这两列求平均得到T1。
或者直接对测试集只用M1预测一次直接得到T1。
P1、T1得到之后,P2、T2、P3、T3也就是同样的方法。理解了2折交叉验证,对于K折的情况也就理解也就非常顺利了。
所以最终的代码是两层循环,第一层循环控制基模型的数目,每一个基模型要这样去得到P1,T1,第二层循环控制的是交叉验证的次数K,对每一个基模型,会训练K次最后拼接得到P1,取平均得到T1。
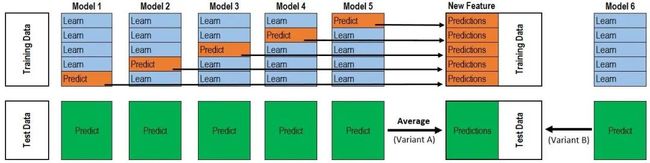
该图是一个基模型得到P1和T1的过程,采用的是5折交叉验证,所以循环了5次,拼接得到P1,测试集预测了5次,取平均得到T1。而这仅仅只是第二层输入的一列/一个特征,并不是整个训练集。
Python实现
用了一个泰坦尼克号的尝试了一下代码,从头到尾都是可以运行的。针对其中一段关键的稍作分析:
def get_oof(clf, x_train, y_train, x_test):
oof_train = np.zeros((ntrain,))
oof_test = np.zeros((ntest,))
oof_test_skf = np.empty((NFOLDS, ntest)) #NFOLDS行,ntest列的二维array
for i, (train_index, test_index) in enumerate(kf): #循环NFOLDS次
x_tr = x_train[train_index]
y_tr = y_train[train_index]
x_te = x_train[test_index]
clf.fit(x_tr, y_tr)
oof_train[test_index] = clf.predict(x_te)
oof_test_skf[i, :] = clf.predict(x_test) #固定行填充,循环一次,填充一行
oof_test[:] = oof_test_skf.mean(axis=0) #axis=0,按列求平均,最后保留一行
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1) #转置,从一行变为一列这里只实现了针对一个基模型做K折交叉验证,因为P1和T1都是多行一列的结构,这里是先存储为一行多列,最后进行转置。
Stacking方法其实在R中也有集成好的可以调用:caretEnsemble包下的caretStack()方法,关键代码如下:
algorithmList <- c('lda', 'rpart', 'glm', 'knn', 'svmRadial')
stackControl <- trainControl(method="repeatedcv", number=10, repeats=3, savePredictions=TRUE, classProbs=TRUE)
stack.glm <- caretStack(models, method="glm", metric="Accuracy", trControl=stackControl)最后放一张H2O分享的图片总结一下投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!