Python pandas 筛选 Excel 特定行和列全集
一、筛选特定行
1. 行中的值满足某个条件
2. 行中的值属于某个集合
3. 行中的值匹配特定模式
4. 在所有工作表 sheet 中筛选特定的行
5. 在一组工作表 sheet(并不是所有的) 中筛选特定的行
二、筛选特定列
1. 根据列索引值筛选
2. 根据列标题筛选
3. 在所有工作表 sheet 中筛选特定的列
三、同时筛选指定行和列
原数据下载
一、筛选特定行
1. 行中的值满足某个条件
要求:筛选出销售总额大于 1400.0 的。在某些情况可以需要用 replace(',', '') replace('$', '')等 对数据进行处理。
原数据
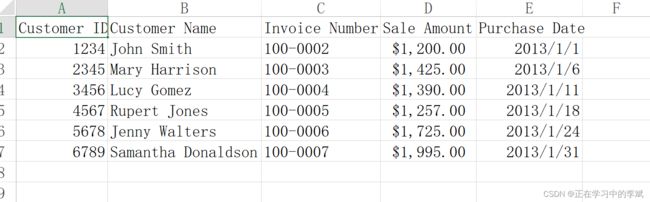
结果

import pandas as pd
input_file = "E:\work\input_file.xlsx"
output_file = "E:\work\output_file.xlsx"
data_frame = pd.read_excel(input_file, 'january_2013', index_col=None)
# astype 数据类型转换
data_frame_value_meets_condition = data_frame[data_frame['Sale Amount'].astype(float) > 1400.0]
writer = pd.ExcelWriter(output_file)
data_frame_value_meets_condition.to_excel(writer, sheet_name='output_sheet', index=False)
writer.save()
2. 行中的值属于某个集合
要求:筛选出购买日期在 ['01/24/2013','01/31/2013'] 这个集合里面的数据
isin
结果

import pandas as pd
input_file = "E:\work\input_file.xlsx"
output_file = "E:\work\output_file.xlsx"
data_frame = pd.read_excel(input_file, 'january_2013', index_col=None)
important_dates = ['01/24/2013','01/31/2013']
data_frame_value_in_set= data_frame[data_frame['Purchase Date'].isin(important_dates)]
writer = pd.ExcelWriter(output_file)
data_frame_value_in_set.to_excel(writer, sheet_name='output_sheet', index=False)
writer.save()
3. 行中的值匹配特定模式
要求:筛选出客户姓名包含一个特定模式。比如 以 J 开头的数据
str.startswith("J")
结果

import pandas as pd
input_file = "E:\work\input_file.xlsx"
output_file = "E:\work\output_file.xlsx"
data_frame = pd.read_excel(input_file, 'january_2013', index_col=None)
data_frame_value_matches_pattern = data_frame[data_frame['Customer Name'].str.startswith("J")]
writer = pd.ExcelWriter(output_file)
data_frame_value_matches_pattern.to_excel(writer, sheet_name='output_sheet', index=False)
writer.save()
4. 在所有工作表 sheet 中筛选特定的行
原数据见开始处链接
要求:筛选出所有工作表中 sale amount 大于1400 的
append
concat
结果
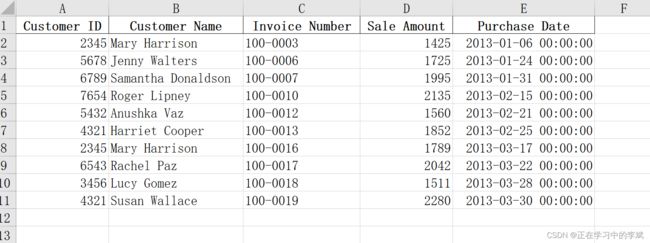
import pandas as pd
input_file = "E:\work\input_file.xlsx"
output_file = "E:\work\output_file.xlsx"
data_frame = pd.read_excel(input_file, sheet_name=None, index_col=None)
row_output = []
for worksheet_name, data in data_frame.items():
# 先用数组的形式存起来,3组数据
row_output.append(data[data['Sale Amount'].replace('$', '').astype(float) > 1400.0])
# 合并成一个 data_frame 格式的数据
filtered_rows = pd.concat(row_output, axis=0, ignore_index=True)
writer = pd.ExcelWriter(output_file)
filtered_rows.to_excel(writer, sheet_name='output_sheet', index=False)
writer.save()
5. 在一组工作表 sheet(并不是所有的) 中筛选特定的行
原数据见开始处链接
要求:筛选出所有工作表中 sale amount 大于1400 的
sheet_name 用数组表示,填入指定的 sheet 索引 my_sheets = [0, 1]
结果
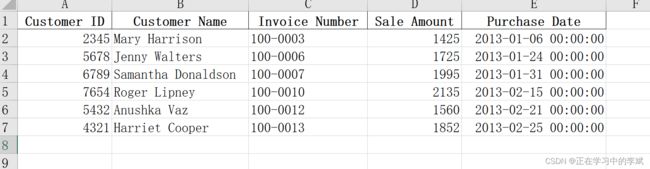
import pandas as pd
input_file = "E:\work\input_file.xlsx"
output_file = "E:\work\output_file.xlsx"
my_sheets = [0, 1]
data_frame = pd.read_excel(input_file, sheet_name=my_sheets, index_col=None)
row_list = []
for worksheet_name, data in data_frame.items():
row_list.append(data[data['Sale Amount'].replace('$', '').replace(',', '').astype(float) > 1400.0])
filtered_rows = pd.concat(row_list, axis=0, ignore_index=True)
writer = pd.ExcelWriter(output_file)
filtered_rows.to_excel(writer, sheet_name='set_of_worksheets', index=False)
writer.save()
二、筛选特定列
1. 根据列索引值筛选
iloc 有两个参数,第一个表示行,第二个表示列。
iloc[:, [0, 3]] 表示筛选索引为 0(Customer ID)和 3 (Purchase Date)的列
iloc[:, 0] 表示只筛选索引为 0(Customer ID)
原数据
结果
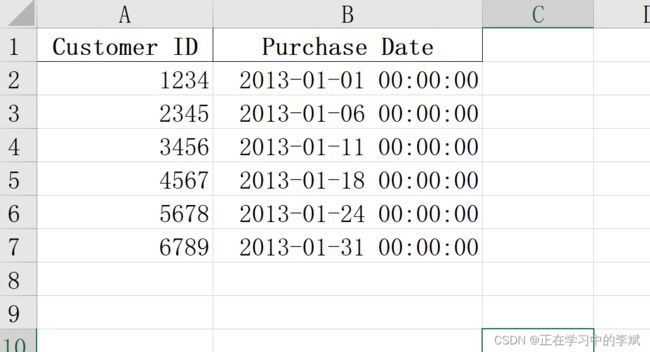
import pandas as pd
input_file = "E:\work\input_file.xlsx"
output_file = "E:\work\output_file.xlsx"
data_frame = pd.read_excel(input_file, 'january_2013', index_col=None)
# 只筛选一列的时候可以不用数组[]
# data_frame_column_by_name = data_frame.iloc[:, 1]
data_frame_column_by_index = data_frame.iloc[:, [0, 3]]
writer = pd.ExcelWriter(output_file)
data_frame_column_by_index.to_excel(writer, sheet_name='output_sheet', index=False)
writer.save()
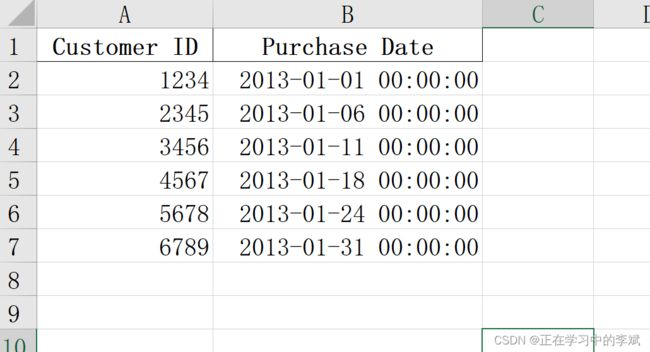
2. 根据列标题筛选
loc 有两个参数,第一个表示行,第二个表示列。
loc[:, ['Customer ID', 'Purchase Date']] 表示筛选列标题为 Customer ID 和 Purchase Date 的列
结果
import pandas as pd
input_file = "E:\work\input_file.xlsx"
output_file = "E:\work\output_file.xlsx"
data_frame = pd.read_excel(input_file, 'january_2013', index_col=None)
data_frame_column_by_name = data_frame.loc[:, ['Customer ID', 'Purchase Date']]
writer = pd.ExcelWriter(output_file)
data_frame_column_by_name.to_excel(writer, sheet_name='jan_13_output', index=False)
writer.save()
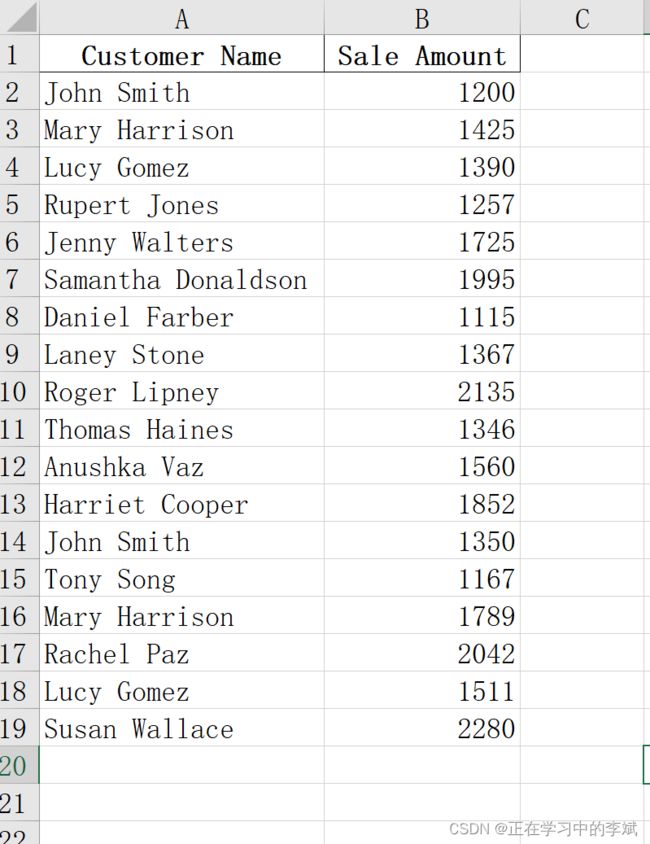
3. 在所有工作表 sheet 中筛选特定的列
原数据见开始处链接
要求:筛选出所有工作表中 'Customer Name', 'Sale Amount'两列
结果
import pandas as pd
input_file = "E:\work\input_file.xlsx"
output_file = "E:\work\output_file.xlsx"
data_frame = pd.read_excel(input_file, sheet_name=None, index_col=None)
row_output = []
for worksheet_name, data in data_frame.items():
row_output.append(data[data['Sale Amount'].replace('$', '').astype(float) > 1400.0])
filtered_rows = pd.concat(row_output, axis=0, ignore_index=True)
writer = pd.ExcelWriter(output_file)
filtered_rows.to_excel(writer, sheet_name='output_sheet', index=False)
writer.save()
三、同时筛选指定行和列
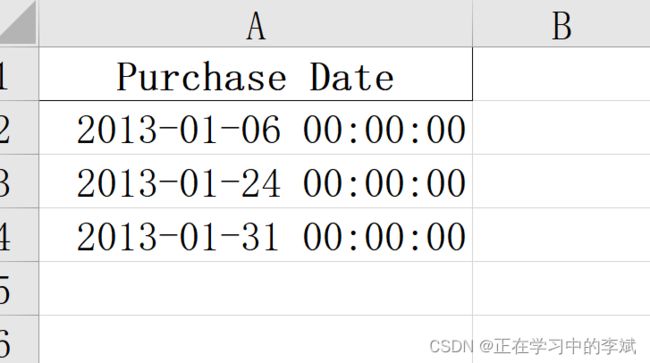
1. 两步走,先筛选行,再筛选列
import pandas as pd
input_file = "E:\work\input_file.xlsx"
output_file = "E:\work\output_file.xlsx"
data_frame = pd.read_excel(input_file, 'january_2013', index_col=None)
data_frame_value_meets_condition = data_frame[data_frame['Sale Amount'].astype(float) > 1400.0]
data_frame_column_by_name = data_frame_value_meets_condition.loc[:, 'Purchase Date']
writer = pd.ExcelWriter(output_file)
data_frame_column_by_name.to_excel(writer, sheet_name='jan_13_output', index=False)
writer.save()
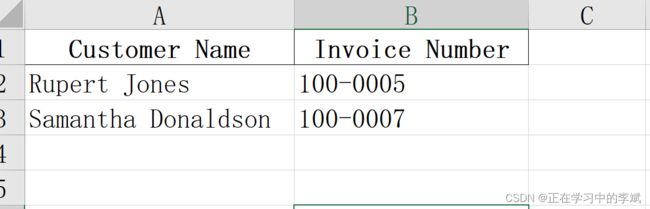
2. 直接使用 loc 或者 iloc 函数
筛选索引为 3 和 5 行中的 ,列索引为 1 和 2 的数据。
结果
import pandas as pd
input_file = "E:\work\input_file.xlsx"
output_file = "E:\work\output_file.xlsx"
data_frame = pd.read_excel(input_file, 'january_2013', index_col=None)
data_frame_column_by_name = data_frame.iloc[[3, 5], [1, 2]]
writer = pd.ExcelWriter(output_file)
data_frame_column_by_name.to_excel(writer, sheet_name='jan_13_output', index=False)
writer.save()