开箱即用!中文关键词抽取(Keyphrase Extraction),基于LDA与PageRank(TextRank, TPR, Salience Rank, Single TPR)
Keyphrase Extraction Algorithm
项目地址:https://github.com/JackHCC/Chinese-Keyphrase-Extraction
无监督学习:中文关键词抽取(Keyphrase Extraction),基于LDA与PageRank(TextRank, TPR, Salience Rank, Single TPR)
Keyphrase Extraction Algorithm
基于无监督学习的中文关键词抽取(Chinese Keyphrase Extraction)
-
基于统计:TF-IDF,YAKE
-
基于图:
-
基于统计:TextRank,SingleRank,SGRank,PositionRank
-
基于类似文件/引文网络:ExpandRank,CiteTextRank
-
基于主题:
-
基于聚类:TopicRank(TR)
-
基于LDA:TPR(TopicPageRank), Single TPR,Salience Rank
- 英文Keyphrase Extraction参考:https://github.com/JackHCC/Keyphrase-Extraction
-
-
基于语义方法:
- 基于知识图谱:WikiRank
- 基于预训练词嵌入: theme-weighted PageRank
-
-
基于嵌入:EmbedRank, Reference Vector Algorithm (RVA),SIFRank
-
基于语言模型:N-gram

Introduction
Statistics-based
| Algorithm | Intro | Year | ref |
|---|---|---|---|
| TF-IDF | 一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词 | 1972 | link |
| YAKE | 首次将主题(Topic)信息整合到 PageRank 计算的公式中 | 2018 | paper |
Graph-based
| Algorithm | Intro | Year | ref |
|---|---|---|---|
| TextRank | 基于统计,将PageRank应用于文本关键词抽取 | 2004 | paper |
| SingleRank | 基于统计,TextRank的一个扩展,它将权重合并到边上 | 2008 | paper |
| SGRank | 基于统计,利用了统计和单词共现信息 | 2015 | paper |
| PositionRank(PR) | 基于统计,利用了单词-单词共现及其在文本中的相应位置信息 | 2017 | paper |
| ExpandRank | 基于类似文件/引文网络,SingleRank扩展,考虑了从相邻文档到目标文档的信息 | 2008 | paper |
| CiteTextRank | 基于类似文件/引文网络,通过引文网络找到与目标文档更相关的知识背景 | 2014 | paper |
| TopicRank(TR) | 基于主题,使用层次聚集聚类将候选短语分组为单独的主题 | 2013 | paper |
| TPR | 基于主题,首次将主题(Topic)信息整合到 PageRank 计算的公式中 | 2010 | paper |
| Single TPR | 基于主题,单词迭代计算的Topic PageRank | 2015 | paper |
| Salience Rank | 基于主题,引入显著性的Topic PageRank | 2017 | paper |
| WikiRank | 基于语义,构建一个语义图,试图将语义与文本联系起来 | 2018 | paper |
Embedding Based
| Algorithm | Intro | Year | ref |
|---|---|---|---|
| EmbedRank | 使用句子嵌入(Doc2Vec或Sent2vec)在同一高维向量空间中表示候选短语和文档 | 2018 | paper |
| Reference Vector Algorithm (RVA) | 使用局部单词嵌入/语义(Glove),即从考虑中的单个文档中训练的嵌入 | 2018 | paper |
| SIFRank/SIFRank+ | 基于预训练语言模型的无监督关键词提取新基线 | 2020 | paper |
Dependencies
sklearn
matplotlib
nltk==3.6.7
gensim==3.8.3
scipy==1.5.4
jieba==0.42.1
networkx==2.5
numpy==1.19.5
xlrd==1.2.0
openpyxl==3.0.7
pandas==1.1.5
matplotlib==3.3.4
thulac==0.2.1
overrides==3.1.0
elmoformanylangs
File
main.py:主程序入口process.py:数据预处理和配置加载lda.py:潜在迪利克雷分配ranks.py:Rank算法实现utils.py:工具函数distribution_statistics.py:关键词输出结果统计model/:基于嵌入的算法模型目录
Data
本项目采用新浪新闻8个领域(体育,娱乐,彩票,房产,教育,游戏,科技,股票)的新闻数据共800条作为实验数据。
数据集位于data/data.xlsx下,由两列组成,第一列content存放新闻标题和新闻的正文内容,第二列是type是该新闻的话题类型。
在模型训练过程只需要利用excel文件中的content列,第二列是根据提取的关键词来衡量提取的准确性。
如何使用自己的数据
按照data.xlsx的数据格式放置你的数据,只需要content列即可。
Config
config目录下可以配置:
jieba分词库的自定义词典jieba_user_dict.txt,具体参考:Jieba- 添加停用词(
stopwords)stop_words.txt - 添加词性配置
POS_dict.txt,即设置提取最终关键词的词性筛选,具体词性表参考:词性表
如果需要使用SIF_rank算法,需要加载elmo模型和thulac模型:
elmo模型的下载地址:这里,具体放置参考:这里thulac模型下载地址:这里,具体放置参考:这里- 百度网盘备份:这里,提取码:jack
Usage
Install
git clone https://github.com/JackHCC/Chinese-Keyphrase-Extraction.git
cd Chinese-Keyphrase-Extraction
pip install -r requirements.txt
Run
# TextRank
python main.py --alg text_rank
# PositionRank
python main.py --alg position_rank
# TR
python main.py --alg tr
# TPR
python main.py --alg tpr
# Single TPR
python main.py --alg single_tpr
# Salience Rank
python main.py
# EmbedRank
python main.py --alg embed_rank
# SIFRank(适合单条数据抽取)
python main.py --alg SIF_rank
Custom
python main.py --alg salience_rank --data ./data/data.xlsx --topic_num 10 --top_k 20 --alpha 0.2 --lambda_ 0.7
alg:选择Rank算法,选项包括:text_rank,SG_rank,position_rank,expand_rank,tr,tpr,single_tpr,salience_rank,embed_rank,SIF_rankdata:训练数据集路径topic_num:确定潜在迪利克雷分配的主题数量top_k:每个文档提取关键词的数量alpha:salience_rank算法的超参数,用于控制语料库特异性和话题特异性之间的权衡,取值位于0到1之间,越趋近于1,话题特异性越明显,越趋近于0,语料库特异性越明显lambda_:基于图的Rank算法中PageRank的超参数,取值位于0到1之间window_size:PositionRank算法的参数,共现矩阵的共现窗口大小max_d:TopicRank算法层次聚类的最大距离plus:SIFRank算法参数,True表示使用SIFRank+,False表示使用SIFRank
Train Your own Embedding
EmbedRank
如果使用EmbedRank算法,这里采用gensim的Doc2Vec训练嵌入矩阵,如果使用你自己的数据,在运行该算法之前,你应该优先执行以下语句:
cd model
# Train Doc2Vec to get Embedding Matrix
python embed_rank_train.py
训练得到的模型存储在./model/embed_rank目录下。
然后回到上一级目录执行:
cd ..
# EmbedRank
python main.py --alg embed_rank
Result
RunTime
- 包括加载数据到关键词抽取完成
| Algorithm | Time(s) |
|---|---|
| TextRank | 90 |
| SGRank | - |
| PositionRank(PR) | 142 |
| ExpandRank | - |
| TopicRank(TR) | 212 |
| TPR | 192 |
| Single TPR | 128 |
| Salience Rank | 108 |
| EmbedRank | 235 |
| SIF_rank | ++ |
Keyphrase Extract
- TextRank前十条数据提取关键词结果
0 : 训练;大雨;球员;队员;队伍;雨水;热身赛;事情;球队;全队;国奥;影响;情况;比赛;伤病
1 : 战术;姑娘;首战;比赛;过程;记者;主帅;交锋;信心;剪辑;将士;软肋;世界杯;夫杯;遭遇
2 : 冠军;活动;女士;文静;游戏;抽奖;俱乐部;眼镜;大奖;特等奖;奖品;现场;环节;教练;球队
3 : 俱乐部;球员;工资;危机;宏运;球队;奖金;管理;老队员;教练;笑里藏刀;前提;集体;集团;经验
4 : 警方;立案侦查;总局;产业;电话;足球;外界;消息;公安部门;依法;中体;主席;裁判;检察机关;委员会
5 : 比赛;鹿队;机会;命中率;队员;联赛;调整;开赛;压力;包袱;外援;主场;状态;体育讯;金隅
6 : 火箭;球队;比赛;原因;时间;效率;开局;事实;教练组;变化;轨道;过程;漫长;判断能力;时机
7 : 胜利;球队;队友;火箭;篮板;比赛;关键;垫底;句式;小牛;新浪;战绩;体育讯;活塞;时间
8 : 火箭;交易;活塞;球队;球员;情况;筹码;价值;命运;市场;续约;掘金;遭遇;球星;核心
9 : 湖人;比赛;球队;后卫;揭幕战;沙农;时间;出场;阵容;板凳;火力;外线;念头;贡献;证明
10 : 公牛;球员;球队;教练;数据;比赛;能力;体系;主教练;命中率;交流;研究;水平;记者;小时
- 最终提取结果写入excel表格中,具体在
result目录下。
Topic Distribution
获取关键词抽取结果的主题分布,执行下面语句(前提是先根据对应算法生成了对应的结果)
python distribution_statistics.py
Salience Rank算法抽取关键词Top 6的主题分布结果:
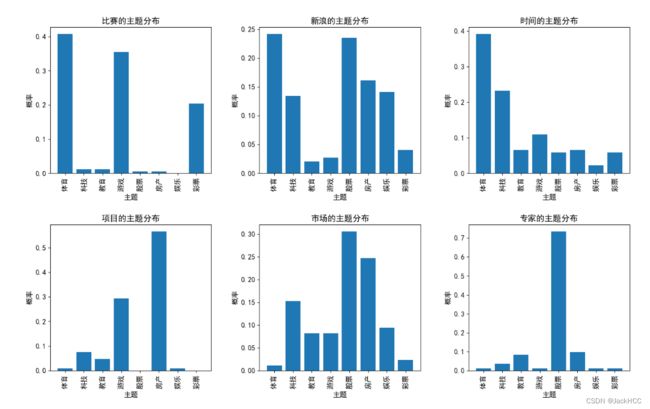
提取关键词后每个主题下的Top-K关键词:
主题: 体育 Top-10关键词: 比赛;时间;球队;体育讯;新浪;球员;篮板;助攻;奇才;投篮
主题: 娱乐 Top-10关键词: 电影;影片;观众;演员;票房;新浪;娱乐;独家;记者;合作
主题: 彩票 Top-10关键词: 主场;比赛;主队;客场;足彩;足球彩票;公司;联赛;球队;赔率
主题: 房产 Top-10关键词: 项目;户型;建筑;发展;新浪;生活;市场;活动;开发商;区域
主题: 教育 Top-10关键词: 学生;大学;学校;工作;教育;国家;专业;留学生;课程;英语
主题: 游戏 Top-10关键词: 比赛;电子竞技;游戏;总决赛;项目;玩家;赛事;赛区;世界;冠军
主题: 科技 Top-10关键词: 时间;科技;研究;消息;科学家;新浪;技术;公司;人员;市场
主题: 股票 Top-10关键词: 专家;压力;老师;网友;走势;股票;新浪;突破;经济;分析
FAQ
如果你需要使用SIF_rank算法,该模块用到了nltk包,如果你无法根据该包获取stopwords或者关于该包的一些其他问题,你可以:
- 前往 nltk_data,下载该仓库
- 通过比较可以发现压缩包中的文件结构和
%appdata%/Roaming/nltk_data下的目录结构是一致的,所以把packages里面的东西复制到%appdata%/Roaming/nltk_data里面就可以了
Reference
- Papagiannopoulou E, Tsoumakas G. A review of keyphrase extraction.