ACL2022 | Meta AI提出prompt-free的NLP小样本学习框架,效果超越prompt
每天给你送来NLP技术干货!
来自:圆圆的算法笔记

现阶段在NLP领域解决few-shot learning最火的方法就是prompt了。Prompt通过设计特定任务的具体模板,以及如何将预测结果映射到对应label,基于预训练语言模型给出预测结果。即使样本量很少,甚至没有样本,也能取得比较好的效果。
然而,基于prompt的few-shot learning方法的问题在于,需要人工针对不同任务设计将输入转化为prompt模板的方法,以及将预测结果映射到label的方法。并且之前的研究也表明,这种方法的效果对于prompt的设计或者label映射的方法选择非常敏感,即使模板中一个单词的变化,也会带来效果的大幅波动。
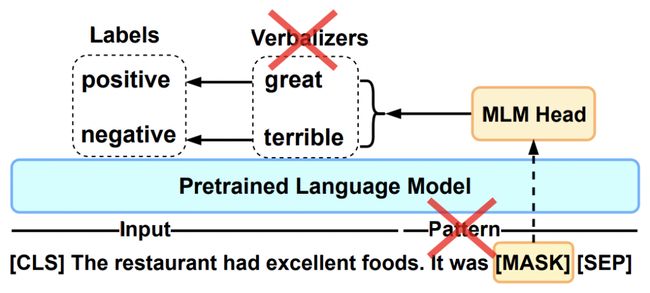
ACL 2022 Meta AI发表了一篇文章PERFECT: Prompt-free and Efficient Few-shot Learning with Language Models,提出在few-shot learning场景下,不需要依赖prompt模板和verbalizer的设计,也能达到优异效果的方法,并且finetune的效率也很高。这种方法比较适合样本量不是特别少(比如只有几个样本或者没有样本)的few-shot learning场景。
推荐阅读:
NLP Prompt系列——Prompt Engineering方法详细梳理
NLP中的绿色Finetune方法
最新NLP Prompt代表工作梳理!ACL 2022 Prompt方向论文解析
1
Adapter Layer
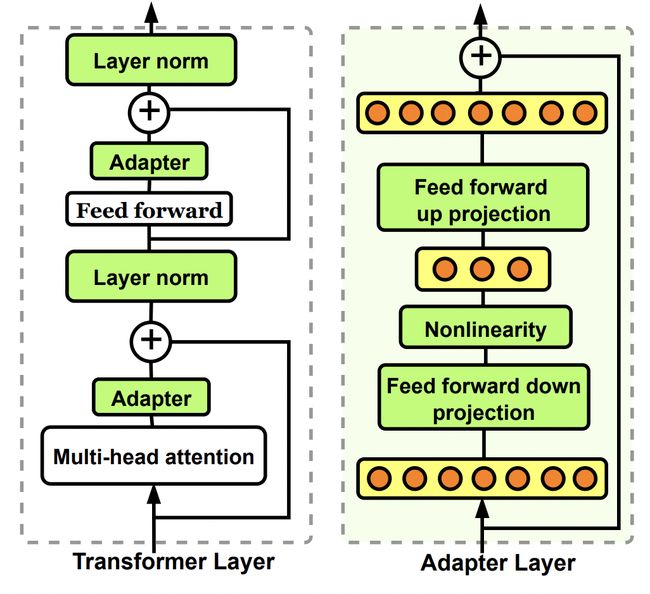
PERFECT采用了adapter-finetune的思路,下面首先让我们回顾一下adapter-finetune的原理。Adapter-finetune是在Parameter-Efficient Transfer Learning for NLP(ICML 2019)这篇文章中提出的,是一种更轻量级的迁移学习方法,只需要finetune少量参数就能达到和finetune整个模型不相上下的效果。
具体做法为,在原来的Bert模型的每层中间加入两个adapter。Adapter通过全连接对原输入进行降维进一步缩小参数量,经过内部的NN后再将维度还原,形成一种bottleneck的结构。在finetune过程中,原预训练Bert模型的参数freeze住不更新,只更新adapter的参数,大大减少了finetune阶段需要更新和保存的参数量。
2
PERFECT核心结构
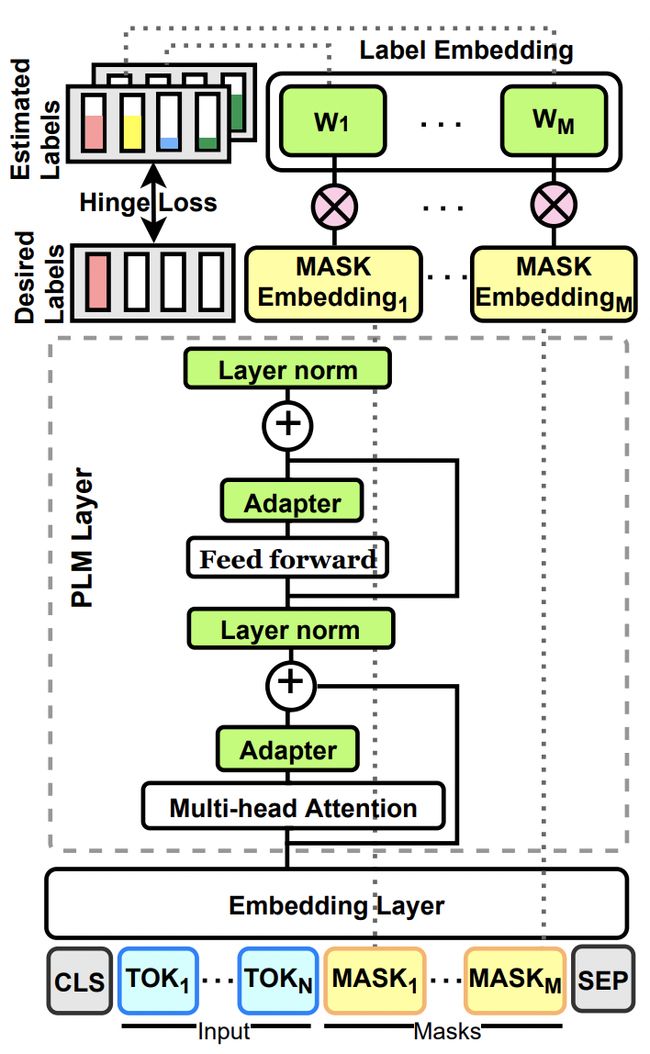
PERFECT模型的核心结构如下图所示。主要包括Pattern-Free Task Description、Multi-Token Label Embeddings两个部分。
Pattern-Free Task Description对应的是传统Prompt方法中的模板设计。PERFECT中不再对输入进行人工的模板设计,而是直接使用每个task独有的adapter layer,让adapter layer自动学习每个任务的隐含task描述。这种方法相比原来的人工设计prompt方法,可以减少对人工设计的依赖,相比对prompt的设计比较敏感,这种方法更稳定。在训练过程中会freeze住语言模型其他参数,只finetune adapter部分,资源开销占用也比较小。
Multi-Token Label Embeddings对应着传统Prompt方法中的verbalizer设计部分。核心做法是:每个输入后面接多个[MASK],每个[MASK]都做一遍多分类任务。这里首先定义了label embedding,它是一个K*M*H的张量,其中K表示类别的数量,M表示每个类别要使用多少个token表示,H表示每个label embedding的维度。这个label embedding起到了替代传统prompt中verbalizer的作用。每个label对应M个向量表示,对应着输入后面添加的多个M个[MASK]。
为了训练这些label embedding,PERFECT将输入文本后面拼接M个[MASK] token,经过Transformer后,每个[MASK] token得到一个隐状态表示。每个[MASK] token的隐状态表示和对应位置的label embedding计算内积,得到每个token计算出的K分类结果。最后通过Hinge Loss计算每个位置token对每个label的打分和真实label的差异。
在Inference阶段,采用的是比较当前样本表示和训练数据中各个label样本平均表示的方法,融合多个位置的[MASK] token得到最终分类结果。对于一个样本,模型会产出M个[MASK] token,计算每个[MASK] token产出的embedding,和某个label所有训练样本在这个位置上的[MASK] token平均embedding的相似度,作为衡量当前样本在当前位置和这个label距离。最后融合各个位置的结果得到最终label。这个过程可以表示为如下公式,其中hi表示当前样本在i位置[MASK] token的表示,ciy表示训练数据中所有label=y的样本在i位置[MASK] token的平均表示:
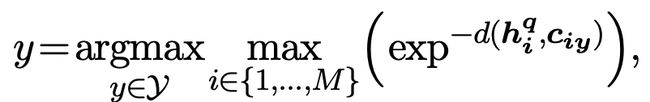
3
对比模型介绍—PET
本文实验中主要对比的模型是PET,是目前基于prompt的few-shot learning的SOTA方法。出自论文Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference(2021)。下面对PET进行一个简单介绍,也方便和本文的方法进行对比。
PET采用知识蒸馏的方法对不同prompts进行融合。在构造多个prompts后,使用每个prompt分别finetune一个模型,然后用不同prompts finetune的模型给数据打一个soft label的多模型融合结果,用这个soft label去学习一个下游模型,就是知识蒸馏的思想。为了让不同prompts模型有信息交互,会进行多轮finetune,每个模型每轮时候的数据,都会增加上一轮其他模型(随机采样几个)在无标签数据上的预测结果。随着finetune轮数增加,每个模型的训练数据集越来越大,融入了越来越多其他模型的打分结果。该方法的多轮finetune的示意图如下,每个M是用每个prompt finetune得到模型,T代表每个模型finetune时使用的数据集。
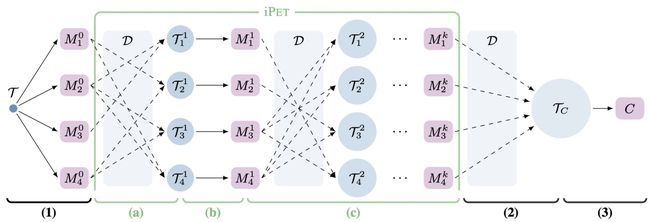
4
实验结果
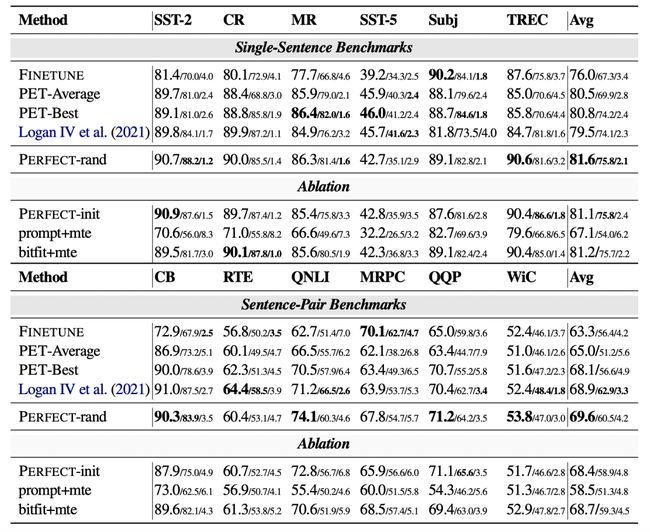
下表展示了在多个数据集PERFECT模型相比基础的Finetune方法,以及基于Prompt的SOTA方法PET的效果对比,PERFECT在多个数据集上都取得最优效果。
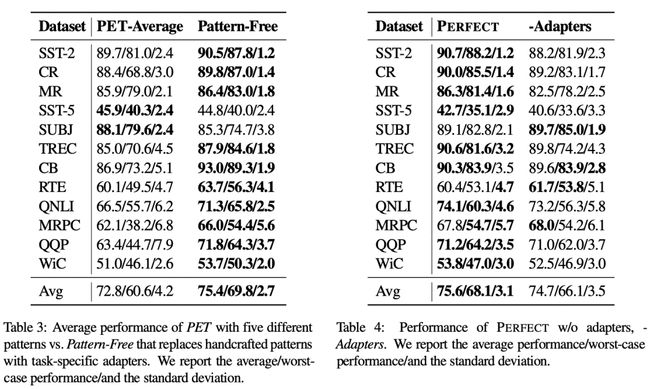
文中重点对Adapter Layer的效果进行了对比实验。下表中第一列是平均效果,第二列是最差效果,第三列是标准差。在PET中,将人工设计的prompt替换成Adapter Layer,效果会有一定提升。如果去掉PERFECT中的adapters,效果会出现比较明显的下降,特别是最差效果会显著下降。这表明。使用Adapter Layer可以很好的提升模型稳定性。
5
总结
通过本文,可以看出目前NLP中few-shot learning的两种不同思路。基于Prompt的思路,依赖人工设计模板、答案和label的映射关系;本文提出PERFECT,采用隐式学习的方式,不依赖人工设计模板,可以提升模型稳定性。对于有一定数量训练数据的场景中,可以取得比较好的效果。