swin_transformer源码详解
注:为了更加实例化的说明,本文假设输入图像大小为(224,224,3)
整体架构
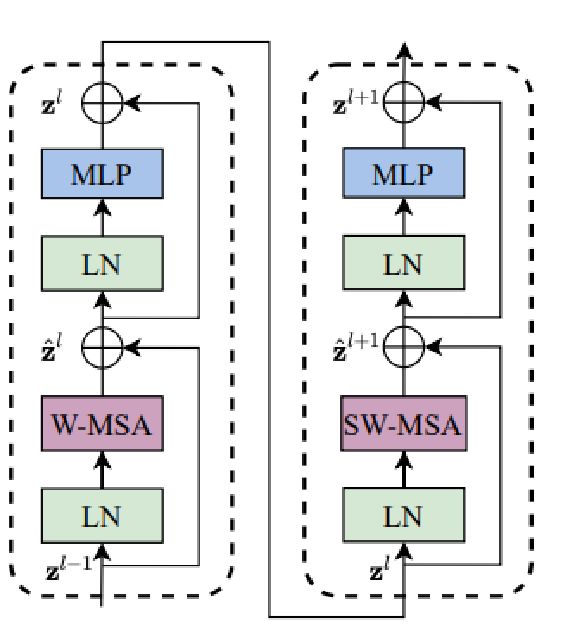
对于一张224*224的图像,首先,经过4*4的卷积,将图像维度化为 4,56,56,128的特征图,对特征图维度进行变换,得到4*3136*128的图像,即对图像进行了embeding,然后将图像输入transforer block,将特征图转变为8*8的窗口,进行注意力机制的计算,一个transformer block包含窗口自注意力W-MAS,计算8*8窗口内部的特征和滑动窗口自注意力SW-MSA,计算窗口间的特征,经过transformer的计算后,再进行patch mergeing将特征图大小减半,类似于卷积。

1.图像数据patch编码
首先,对于输入的图像,假设为224*224,我们采用4*4的卷积,然后将图像进行flatten,形成一个个patch,最后输出维度为batch_size * HW * Channels,H=W=224/4
代码如下:
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
# in_channels:3,out_channels:128
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# 卷积
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
# print(x.shape) #4 3136 96 其中3136就是 224/4 * 224/4 相当于有这么长的序列,其中每个元素是96维向量
if self.norm is not None:
x = self.norm(x)
# print(x.shape)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops3.transformer block
一个transformer block由w-MSA和SW-MSA组成
W-MSA/SW-MSA
输入维度为4,3136,128的序列x,首先将其维度变换为4,56,56,128,再经过维度变换,将维度变成 256, 49, 128,即表示,有256个特征图,每个特征图有49个tokens,每个token是128维的向量。
首先做W-MSA,对于W-SMA,不对窗口进行偏移,经过多头注意力的计算,得到结果,对于SW-MSA,窗口进行偏移,加入mask后,做相同的多头注意力的计算。最后将窗口再偏移回去。
多头注意力:首先构造维度为256, 4, 49, 32的q,k,v辅助向量,256表示有256个特征图,4表示有4个head,49表示有49个tokens,32表示,每个头32个向量,然后经过多头注意力的计算,其中,会加入相对位置编码
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
# num_windows, Wh*Ww, Wh*Ww
B_, N, C = x.shape
# 3, 256, 4, 49, 32
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# print(qkv.shape)
# 256, 4, 49, 32
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
# print(q.shape)
# print(k.shape)
# print(v.shape)
# 256, 4, 49, 49
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
# print(attn.shape)
# 相对位置编码 49*49*4
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
# print(relative_position_bias.shape)
# 4, 49, 49
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
# print(relative_position_bias.shape)
# 加入位置编码 256, 4, 49, 49
attn = attn + relative_position_bias.unsqueeze(0)
# print(attn.shape)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
# dropout层
attn = self.attn_drop(attn)
# print(attn.shape)
# qkv
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
# print(x.shape)
# 全连接层
x = self.proj(x)
# print(x.shape)
# dropout层
x = self.proj_drop(x)
# print(x.shape)
return x4.下采样
下采样操作,但是不同于池化,这个相当于间接的 (对H和W维度进行间隔采样后拼接在一起,得到H/2,W/2,C*4)

代码如下:
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
# 间隔采样
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops5.相对位置编码
有关swin transformer相对位置编码的理解:
假设window_size是7*7
那么窗口中共有49个patch,共有49*49个相对位置,每个相对位置有两个索引对应x和y两个方向,每个索引值的取值范围是[-6,6]。(第0行相对第6行,x索引相对值为-6;第6行相对第0行,x索引相对值为6;所以索引取值范围是[-6,6])
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
# 2, Wh*Ww, Wh*Ww, https://www.cnblogs.com/sgdd123/p/7603004.html
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
# Wh*Ww, Wh*Ww, 2, [i,j,:]表示窗口内第i个patch相对于第j个patch的坐标
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
此时,构建出来的relative_coords的shape是[49, 49, 2],[i, j, :]表示窗口内第i个patch相对于第j个patch的坐标。
由于此时索引取值范围中包含负值,可分别在每个方向上加上6,使得索引取值从0开始。此时,索引取值范围为[0,12]
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
有了这些相对位置坐标之后,就可以根据这些坐标获取对应的position bias,即论文中公式(4)中的B: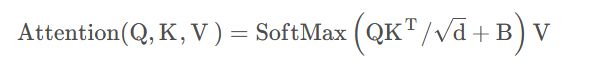
这个时候可以构建一个shape为[13,13]的table,则当相对位置为(i,j)时,B=table[i, j]。(i,j的取值范围都是[0, 12])
由于论文中使用的时multi-head-self-attention,所以table[i, j]的值应该是一个维度为num_heads的一维向量。
在代码中,实现如下:(注意,此时的table将二维的位置关系,合并为了一维的位置关系)
# define a parameter table of relative position bias # shape : 2*Wh-1 * 2*Ww-1, nH
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))
为了与table对应,根据相对位置坐标取值时,也需要将二维相对坐标(i, j)映射为一维相对坐标(i*13+j), 在代码中体现为:
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
最后,就可以根据映射后的坐标来对B进行取值了:
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
附注:
将二维相对坐标(i, j)映射为一维相对坐标时,最简单的映射方式是将i和j相加,但这样无法区分(0, 2)和(2, 0),因为相加的结果都是2;所以作者采用了i*13+j这种方式,其中13 = 2*window_size - 1, 即j取值的最大值。类似于将一个二维数组打平后,每个元素的位置。
参考信息:
https://blog.csdn.net/weixin_42364196/article/details/119954379