安装ubuntu20.04 遇到的问题,及cuda、cudnn、tensorrt安装提示
网卡Realtek Semiconductor Co., Ltd. RTL8125 2.5GbE Controller 驱动异常
貌似是这款网卡和20.04的bug,网上搜索让替换驱动,但是驱动下了,跑去Ubuntu安装发现,gcc没有,make没有,,无奈,需要离线安装Ubuntu环境,这里记录一下过程
主要参考:https://blog.51cto.com/u_2221384/2547041
https://blog.csdn.net/lc_2014c/article/details/84190765
第一个教程,挂在iso的时候,报错无法point cdrom 无奈,改为挂载到/media 上了。
然后配置 source.list的时候,按照第一个教程不行,按照第二个教程的方法二,用sudo apt-cdrom -m -d=/media add 添加到source中成功,但是最后用apt按照的时候一直如图

搜索让一直enter就好,但是吧貌似是我没耐心,最后灵机一动,修改source 仿照教程一的格式,最后成功了。具体写法没记录下来,写在儿当提示,当然最好记得把source.list还原回去,之前记得备份。
也试过用iso里的main下,一个一个deb包的去离线装gcc,但是依赖太多,始终没法安装成功,也有这种操作,感觉能行但太麻烦还容易出错,最后还是挂载iso 改apt为本地源这个方法解决了问题。
开启vino Ubuntu自带远程桌面遇到的问题
更加推荐多人远程桌面的,见
开启vino:
按照教程一步步即可:https://www.jianshu.com/p/e670a9a26989
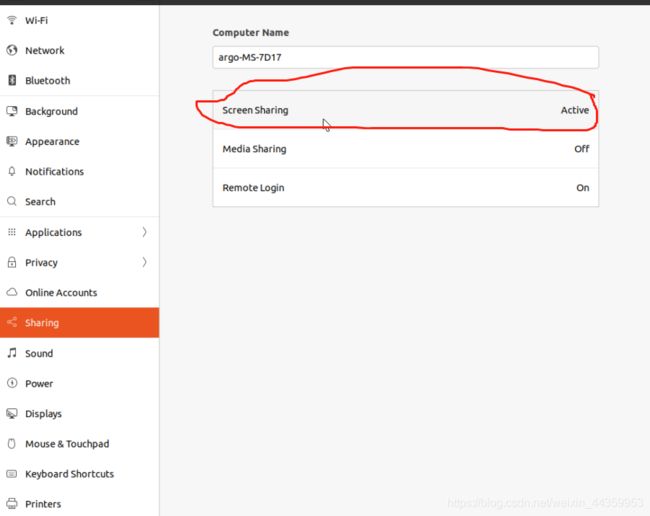
最后开启了自启动服务之后,不要终端reboot,要去右上角正常点击关机,最后选择重启,我最后这样菜成功开启了自启,感觉是玄学,估计是因为教程中的自启方法是基于gnome的,你终端reboot似乎无法触发,要桌面去重启,,,最后解决的办法,是去设置里找到sharing 然后把屏幕共享打开,后面反正我就不管怎么样重启也没问题了
更换软件源
更换清华源:
注意一定要对应好版本,否则悔恨终生啊。我就是之前装了20.04 lts 结果网上找教程更换清华源,结果复制的源是18.04的,,后面更新了一段时间后终于登录桌面之后黑屏,,最后发现是添加支持语言,语言输入法那块出了问题,最后修改源,重装输入法,解决。
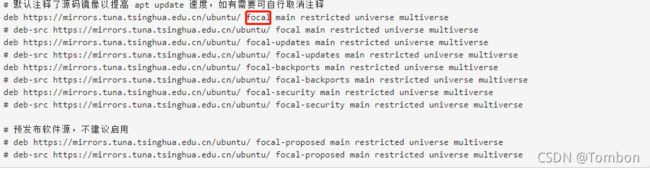
红框框其实就是Ubuntu版本代号,我之前弄错的是bionic,结果系统是20.04,却一直更新18.04的软件源,,你品,你细品,,,
设置中文输入法
为了友好使用,一开始系统语言都用的英文,那么去区域与语言里添加输入法是看不到中文智能拼音的。曲折点设置就是先把语言改成汉语,提示重新登录,之后在去添加输入法里就有智能拼音了,最后再把语言改成英文即可。哈哈哈
配置cuda、cudnn、tensorrt遇到的坑
前期由于rtx3080ti驱动版本的最高支持cuda版本是11.4,结果后面cuda装的11.4的,cudnn也配的11.4的,然后装pytorch,发现人家支持到11.1,吓一跳,结果装了之后还是正常跑,,结果意外来了,最后装tensorrt居然只支持到11.3……不信邪装上去,,最后sudo apt-get install tensorrt报错如下图:

让装cuda11.3,,,我特么,,,哎,决定装11.3了,,,,
所有下回装环境,一定要看各跟环节最高支持到cuda版本,选择其中最低的才最稳,,
关于驱动和cuda版本支持问题,一般用nvidia-smi下看到的cuda版本是最高支持版本,具体该驱动支持不支持cuda版本可用看:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
我的driver version是470.57.02 别看>= 看等于就好,,我特么470的驱动去装11.3就是不行,装完cuda,然后nvidia-smi就报错了,要么不匹配,要么重启之后干脆找不到设备,看nvidia-smi下面的cuda版本,那个才不容易出事。
用runfile在安装CUDA的时候别让它自动帮你安装驱动,你要去看看系统支持的驱动有哪些,如果和这个funfile里的可以对上可以考虑装,但一般别这样,自己根据系统支持的驱动选择高一个或者低点的版本安装
查看系统支持驱动:ubuntu-drivers devices 一般会有推荐的高的和推荐的低的各一个版本,桌面版你就别装server了,,
确认好显卡驱动之后,和tensorrt支持的cuda版本,两者做取舍,**最终安装了460版本的驱动,支持最高cuda11.2.2 然后tensorrt此时也能支持该版本的cuda。**最新的470版本支持cuda11.4,当前tensorrt无法支持的该版本cuda……
安装好显卡驱动之后,下面进入正题 cuda cudnn tensorrt安装
cuda安装提示
cuda地址
用deb的安装方式 把官网步骤走完,安装11.3.1完之后 /usr/local 下面多了三个文件夹 cuda cuda-11
uda-11.3
环境变量添加,官网安装最后的Post-installation Actions有提到
sudo vim ~/.bashrc
#添加 注意11.4,这个看自己安装的版本
export PATH=/usr/local/cuda-11.4/bin${PATH:+:${PATH}}
# when using the runfile installation method 即用的runfile安装的cuda还得加lib。我是64位
$ export LD_LIBRARY_PATH=/usr/local/cuda-11.4/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
source ~/.bashrc
nvcc -V看成功没有
RUNFILE安装之后配置环境变量有差异,文件夹也只有cuda-11.3,后面这种方式安装tensorrt安装失败故此先放弃runfile安装,同样我觉得runfile是给离线安装用的哈哈。
关于下载已安装cuda和cudnn 多次失败,用的这些语句删除,参考
To remove CUDA Toolkit:
$ sudo apt-get --purge remove "*cublas*" "*cufft*" "*curand*" \
"*cusolver*" "*cusparse*" "*npp*" "*nvjpeg*" "cuda*" "nsight*"
To remove NVIDIA Drivers:
$ sudo apt-get --purge remove "*nvidia*"
To clean up the uninstall:
$ sudo apt-get autoremove
然后在看看/usr/local下有没有cuda文件夹,有点话删除了就好。
cudnn安装提示
见官网教程
cudnn 下载地址
tar安装方式
解压之后关键下面这三句:
sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
sudo cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
看完教程,其实貌似用deb安装方式更好,因为后面验证是否安装成功的教程感觉是基于deb安装方式才有的,换句话说,tar安装方式你不知道如何去验证安装成功了没,,,。
卸载提示
dpkg -l | grep cudnn
看到包名
然后sudo dpkg -r xx即可
如果是tar包安装的方式,哈哈 建议/usr/local下的cuda文件夹删除就好了,,,当然了,,cuda跟着没了
tensorrt安装提示
主要看官网教程
tensorrt 下载
安装tensorrt 先装好cuda和cudnn pycuda
按照教程 对于
sudo apt-key add /var/nv-tensorrt-repo- o s − {os}- os−{tag}/7fa2af80.pub
可在 /var 下找到 /var/nv-tensorrt-repo … 其实就是说的这个,将此仓库用apt-ley添加,在进行后续安装
sudo apt-key add /var/nv-tensorrt-repo-ubuntu2004-cuda11.3-trt8.0.1.6-ga-20210626/7fa2af80.pub
最后安装完tensorrt之后 实际上只是c++的,
如果还要python的官网教程后面的安装pip Wheel File Installation,嗯也可以上面c++不装,独立装python的。

https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing-pip
至此大功告成!
当然以上是基于deb包的安装方式,第一步deb安装好了c++ 第二步安装对于python tensorrt的支持
官方教程里还有对于tar包安装方式的教程。我就没尝试了,,对于离线安装估计用这个合适
卸载tensorrt:sudo apt-get purge “libnvinfer*”
总结一下教训
一开始没有注意对应好显卡驱动、cuda版本、tensorrt最高支持cuda版本的问题,导致了后续一系列到底问题
如果只装python的倒是轻松,会自动匹配cuda版本装合适的tensorr版本及其依赖
记录一个坑,关于tensorrt版本不一致,tensorrt和对于cuda版本不一致
网上搜到的:
1、使用TensorRT生成.engine文件时报错:
TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.0
问题原因:CUDA版本不对
解决,重新安装对应版本。
我遇到的只是警告:
[W] [TRT] TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.4.1
估计是装的时候,cuda和tnesorrt还是对应上了的,只是不是最佳的对应所以有这么个警告
网上搜到的:
2、本机GPU为gtx 960M,目标机器GPU为P2000,程序在目标机器运行报错:
[E] [TRT] …/rtSafe/coreReadArchive.cpp (41) - Serialization Error in verifyHeader: 0 (Version tag does not match)
问题原因:猜测是显卡类型不一致导致目标机无法反序列化.engine文件
解决:在目标机器上编译生成.engine文件
我遇到的:转换文件是在rtx3080ti,tensorrt是8.0.1.6-1+cuda11.3 用在nx上跑,结果报错如下:
[TensorRT] ERROR: coreReadArchive.cpp (38) - Serialization Error in verifyHeader: 0 (Version tag does not match)
[TensorRT] ERROR: INVALID_STATE: std::exception
[TensorRT] ERROR: INVALID_CONFIG: Deserialize the cuda engine failed.
官网解决方案是升级到tensorrt版本一致最好,我打算升级到一致试一试,如果不行就尴尬了,可能还真跟设备扯上关系就只能在目标设备编译生成engine文件了。
测试结果,最后板卡和服务器的tensorrt环境一致了,结果报错:
[TensorRT] ERROR: 6: The engine plan file is generated on an incompatible device, expecting compute 7.2 got compute 8.6, please rebuild.
最后查资料:
https://111qqz.com/2020/03/tensorrt-model-compatibility-notes/
https://forums.developer.nvidia.com/t/problem-loading-trt-engine-plan-on-another-machine/68592
Engine plan 的兼容性依赖于GPU的compute capability 和 TensorRT 版本, 不依赖于CUDA和CUDNN版本.
简单来说,在使用同样TensorRT版本的前提下,在具有相同compute capability 的GPU上的模型是可以通用的.
但是cuda版本是依赖于GPU的compute capability的. 也就是比较新的GPU(对应较高的compute capability)无法使用低版本的cuda.
tensorrt 的序列化和反序列化操作只能在特定硬件上做,两个操作最好在同一硬件,至于compute capability一致的硬件行不行我也没试过,,,
哎愁啊