10、卷积神经网络(补充)
(1)用卷积神经网络实现GoogleNet中的Inception Module
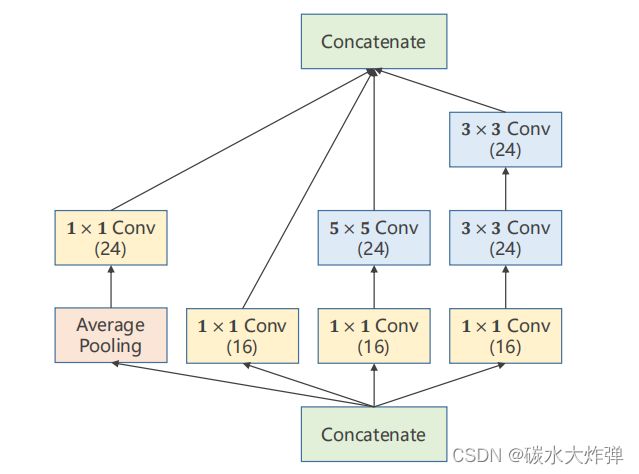
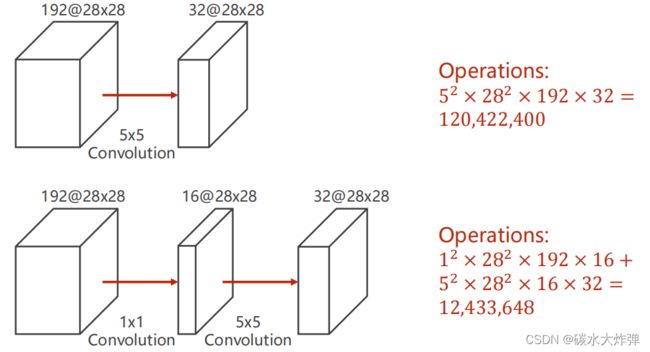
(2)1x1卷积核目的:减少计算量
(3)在MNIST数据集上,用卷积神经网络实现GoogleNet代码:
'''
Inception Module
1x1卷积:目的是减少计算量
GoogleNet
concat:沿着通道拼接
'''
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import torch.nn as nn
batch_size = 64
transform = transforms.Compose([
# convert the PIL Image to tensor,单通道变为多通道
transforms.ToTensor(),
#数据标准化,切换到(0.1)分布,均值mean和标准差std,对MNIST所有像素值计算的结果
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_dataset = datasets.MNIST(root='./mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='./mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
shuffle=False,
batch_size=batch_size
)
class InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA,self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1)
#dim=1沿着第一个维度拼接,(batch,c,w,h),dim=1表示沿着通道c拼接
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
#把模型迁移到GPU上
device = torch.device("cuda:0"if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
#带冲量的梯度下降,冲量可以优化训练过程
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx %300 == 299:
print('[%d, %5d] loss:%.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct / total, correct, total))
if __name__ =='__main__':
for epoch in range(10):
train(epoch)
test()输出结果:

(4)有时候层数不是越多越好,在有的数据集上会出现叠加的层数越多性能越差的问题,有可能是梯度消失导致
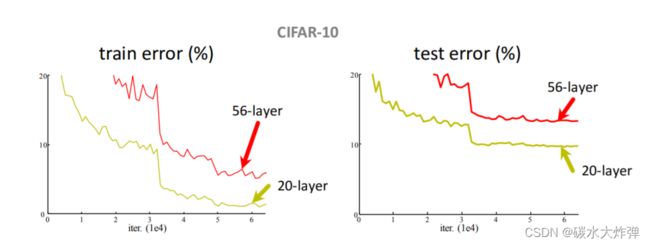
(5)梯度消失:求梯度时,用链式法则把一连串的值乘起来,若梯度都小于1,连乘后趋于0,梯度趋于0,权重w=w-αg得不到更新,没有办法得到充分训练
为解决梯度消失,引入Residual Net残差网络,H(x)=z=F(x)+x,这样权重就可以得到更新


(6)在MNIST数据集上,引入Residual Net实现GoogleNet代码:
'''
Inception Module
1x1卷积:目的是减少计算量
GoogleNet
concat:沿着通道拼接
'''
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import torch.nn as nn
batch_size = 64
transform = transforms.Compose([
# convert the PIL Image to tensor,单通道变为多通道
transforms.ToTensor(),
#数据标准化,切换到(0.1)分布,均值mean和标准差std,对MNIST所有像素值计算的结果
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_dataset = datasets.MNIST(root='./mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='./mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
shuffle=False,
batch_size=batch_size
)
class InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA,self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1)
#dim=1沿着第一个维度拼接,(batch,c,w,h),dim=1表示沿着通道c拼接
'''
解决梯度消失
'''
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels, channels,kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels,kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x+y)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512, 10)
def forward(self,x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
#把模型迁移到GPU上
device = torch.device("cuda:0"if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
#带冲量的梯度下降,冲量可以优化训练过程
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx %300 == 299:
print('[%d, %5d] loss:%.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct / total, correct, total))
if __name__ =='__main__':
for epoch in range(10):
train(epoch)
test()
输出结果:
