DHU 数据科学技术与应用【8】 第1-4次单元测验 答案
目录
- 写在更前面
- 写在前面
- 其他章节选择题答案
- 第一次单元测验 多维数据结构与运算 答案
-
- 1 单选(1分)
- 2 单选(1分)
- 3 单选(1分)
- 4 单选(1分)
- 5 单选(1分)
- 6 单选(1分)
- 7 多选(1分)
- 8 单选(1分)
- 9 单选(1分)
- 10 多选(1分)
- 第二次单元测验 数据汇总与统计(一) 答案
-
- 1 单选(1分)
- 2 单选(1分)
- 3 单选(1分)
- 4 单选(1分)
- 5 单选(1分)
- 6 单选(1分)
- 7 单选(1分)
- 8 多选(1分)
- 9 多选(1分)
- 10 判断(1分)
- 第三次单元测验 数据汇总与统计(二) 答案
-
- 1 单选(1分)
- 2 单选(1分)
- 3 单选(1分)
- 4 单选(1分)
- 5 单选(1分)
- 6 单选(1分)
- 7 单选(1分)
- 8 判断(1分)
- 9 填空(1分)
- 10 填空(1分)
- 第四次单元测验 数据可视化 答案
-
- 1 单选(1分)
- 2 单选(1分)
- 3 单选(1分)
- 4 单选(1分)
- 5 单选(1分)
- 6 多选(1分)
- 7 填空(1分)
- 8 填空(1分)
- 9 填空(1分)
- 10 填空(1分)
写在更前面
本文章免费提供给需要的同学使用
我知道可能动了有些人的蛋糕(有人第四次开课时发的,题目差不多,但是收费),被举报抄袭了,笑死
知识无价,做作业是为了更好地了解知识,并且获得学分,我个人在任何平台,从来没有因为这个收过人一分钱
去年就有同学问我借账号看答案,说有人收费,觉得不值得花这个钱,我也这么觉得
文章全部是我自己手打,制作的答案
没错,为了给大家提供答案,我甚至还再选了一次做完了全部
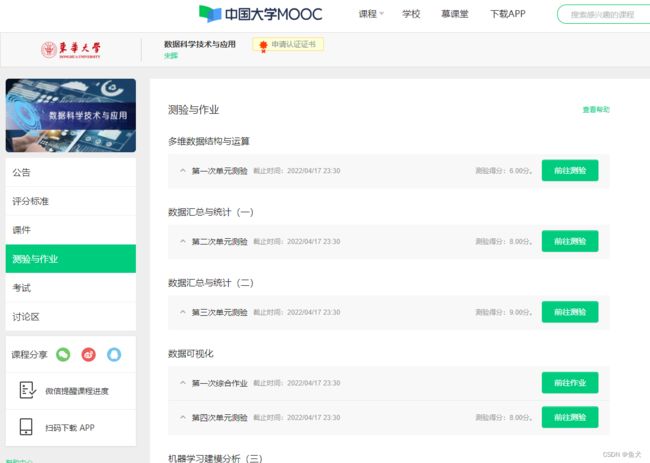
目前,我只好把文章给整合一下,可能到时候比较难找,先看看这样行不行吧
被判成非原创吧…对我账号的数据之类的应该没什么问题,但是上面会显示一条转载链接,感觉挺恶心的,因为本来就是我最近自己做好的。。。又不是复制粘贴的人家的。。。收费的心血就比免费的来得高贵吗?我当然不认。。。
写在前面
课程链接:数据科学技术与应用
第五次开课,对应校内的学期是2022s
一晃两年过去了,世界线却像remake了一样,看到有人要付费才能订阅这些答案,之前也被同学问过要选择题答案,因为之前的课程过期了无法查看,于是干脆再次加入重做一遍
虽然盲考拿到过市二级数据科学的证书,但是用进废退,权当再复习一遍吧
用自己的号测试了两次,都是一样的题,应该大家都是一样的
其他章节选择题答案
第5-7次单元测验
第8次单元测验
第一次单元测验 多维数据结构与运算 答案
1 单选(1分)
下面________不是大数据的特征。
A.规模性
B.高速性
C.多样性
D.低价值性
2 单选(1分)
下面关于数据科学与大数据之间的关系描述,错误的是________。
A.大数据属于数据科学的范畴
B.大数据分析遵循数据科学处理问题的基本工作流程
C.大数据分析采用的技术完全不同于数据科学技术
D.大数据技术是指数据量达到某种规模时引入的分布式存储、计算和传输等方法
3 单选(1分)
names=np.array([’马化腾’,’李彦宏’,’雷军’,’扎克伯格’]),names[2]的值是________。
A.马化腾
B.李彦宏
C.雷军
D.扎克伯格
4 单选(1分)
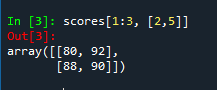
记录同学成绩的scores数组如下,scores[ 1:3, [2,5]] 取得的数据是________。
scores: array([[70, 85, 77, 90, 82, 84, 89],
[60, 64, 80, 75, 80, 92, 90],
[90, 93, 88, 87, 86, 90, 91],
[80, 82, 91, 88, 83, 86, 80],
[88, 72, 78, 90, 91, 73, 80]])
A.array( [ [80,92], [88,90]] )
B.array( [ [64,80], [93,86]] )
C.array( [ [85,84],[64,92], [93,90]] )
D.array( [ [64,92], [93,90],[82,86]] )
闲得无聊的验算:
import numpy as np
scores = np.array([[70, 85, 77, 90, 82, 84, 89],[60, 64, 80, 75, 80, 92, 90],[90, 93, 88, 87, 86, 90, 91],[80, 82, 91, 88, 83, 86, 80],[88, 72, 78, 90, 91, 73, 80]])
输出:
5 单选(1分)
names记录同学名字,subjects记录考试科目数据中,scores记录同学成绩,求Python课程成绩的最高分的语句________。
names:array([‘王微’, ‘肖良英’, ‘方绮雯’, ‘刘旭阳’,‘钱易铭’, dtype=‘
[60, 64, 80, 75, 80, 92, 90],
[90, 93, 88, 87, 86, 90, 91],
[80, 82, 91, 88, 83, 86, 80],
[88, 72, 78, 90, 91, 73, 80]])
A.scores[subjects==‘Python’].max()
B.scores[:,subjects= =‘Python’].max()
C.scores(subjects==‘Python’).max()
D.scores[subjects==‘Python’, : ].max()
闲得无聊的验算:
import numpy as np
names = np.array(['王微', '肖良英', '方绮雯', '刘旭阳','钱易铭'], dtype=')
subjects = np.array(['Math', 'English', 'Python', 'Chinese', 'Art', 'Database', 'Physics'], dtype=')
scores = np.array([[70, 85, 77, 90, 82, 84, 89],[60, 64, 80, 75, 80, 92, 90],[90, 93, 88, 87, 86, 90, 91],[80, 82, 91, 88, 83, 86, 80],[88, 72, 78, 90, 91, 73, 80]])
输出:
就这句代码有输出,但不懂为啥输出不是93

6 单选(1分)
将一维数组转化为多维数组的numpy函数是________。
A.arange()
==B.reshape() ==
C.zeros()
D.ones()
7 多选(1分)
下列能实现将shape为dtype[5,7] 的scores数组所有元素都加10的语句是________。
A.scores + 10
B.np.add(scores, 10)
C.scores[10].add(10)
D.scores + [10,10,10,10,10,10,10]
8 单选(1分)
subjects=np.array([‘Math’, ‘English’, ‘Python’, ‘Chinese’, ‘Art’, ‘Database’, ‘Physics’]),
mask=(subjects==‘English’|subjects==‘Art’)。
则mask数组中值为True的元素个数是________。
A.2
B.3
C.4
D.5
9 单选(1分)
淘宝卖家销售10斤一箱的陕西红富士,应采用________来模拟生成40箱苹果的重量较合理。
A.np.random.radint(6, 15, 40)
B.np.random.uniform(8,12,40)
C.np.random.normal(10, 5, 40)
D.np.random.normal(10, 1, 40)
10 多选(1分)
如果某便利店开有多家门店,为了分析各门店各种奶制品每天的销售情况,需要建立________,以便分析。
A.2个一维数组,分别存放门店名称、商品名称
B.3个一位数组,分别存放门店名称、商品名称、时间
C.2个二维数组,1个存放每个门店的每个商品在本月的总销量,1个存放每天每个商品在所有门店的销量
D.1个三维数组,存放每个门店的每个商品在每天的销量
第二次单元测验 数据汇总与统计(一) 答案
1 单选(1分)
DataFrame对象的列索引通常表示________。
A.每列数据的总数
B.列的位置信息
C.列的数据类型
D.每列数据对应的现实概念
2 单选(1分)
DataFrame对象df中基于位置序号选取第2行第3列数据的方式是_______。(序号从0开始)
A.df.find(1,2)
B.df.iloc[1,2]
C.df.loc[1,2]
D.df.rloc[1,2]
3 单选(1分)
CSV文件是_______,可以使用_______查看。
A.word文件,word查看
B.纯文本文件,文本编辑器
C.ppt文件,powerpoint查看
D.图像文件,画图工具查看
4 单选(1分)
关于DataFrame和Series对象,下列叙述正确的是_______。
A.DataFrame对象只能用于处理两维数据
B.Series对象主要用于处理一维数据
C.DataFrame对象不能转化为Series对象
D.Series对象可以用来处理多维数据
5 单选(1分)
创建height对象,_______语句能选出高度为190的数据。
height=Series({‘13’:187,‘14’:190,‘7’:185,‘2’:178,‘9’:185})
A.height[0]
B.Height[‘7’]
C.height[height.values > 190]
D.height[1]
6 单选(1分)
创建students对象,下面语句筛选出_______大于67公斤同学的_______。
students数据如下:
age height weight
1 19 170 668
2 20 165 65
3 18 175 65
students.loc[students[‘weight’]>67, ‘height’]
A.体重、年龄
B.身高、体重
C.体重、身高
D.年龄、身高
7 单选(1分)
关于数据文件读写,_______是错误的描述。
A.文件中第一行必须给出列的索引名(columns),否则pandas无法读取各列内容
B.pandas读取的数据文件中可以包含中文字符组成的数据
C.读取excel文件时,可以为 sheetname 参数赋值,以读取指定表单的数据
D.csv数据文件用换行符来区分数据行
8 多选(1分)
创建students对象,_______语句可以选出第二个同学的身高。
students数据如下:
age height weight
1 19 170 668
2 20 165 65
3 18 175 65
A.students[‘height’][3]
B.students.loc[2,‘height’]
C.students.iloc[1, 1]
D.students[1,‘height’]
9 多选(1分)
关于DataFrame数据对象的添加和删除操作,_______是正确的描述。
A.DataFrame对象不能直接添加新的列数据
B.DataFrame对象不能直接添加新的行数据
C.可以设置axis的值删除DataFrame指定行或列的数据
D.DataFrame中数据元素的值不能修改
10 判断(1分)
在数据统计中,均值和中位数是相同的概念。
A.√
B.x
第三次单元测验 数据汇总与统计(二) 答案
1 单选(1分)
有3张同学信息表,存储为DataFrame对象stu1,stu2,stu3,具有相同的列索引,合并的方法是________。
A.pd.concat( [stu1,sut2,sut3] )
B.stu1.concat([sut2,sut3])
C.[stu1,stu2,stu3].concat(axis =0)
D.pd.concat(stu1,sut2,sut3)
2 单选(1分)
统计量“方差”描述________。
A.样本个体距离均值的离散程度
B.样本(一组数据)的平均值
C.样本中出现次数最多的值
D.样本中不同的值占样本容量的比例
3 单选(1分)
统计DataFrame对象stu中各‘省份’同学人数的方法是________。
A.stu[].value_counts(‘省份’)
B.stu[‘省份’].count()
C.stu[‘省份’].value_counts()
D.pd.value_counts(stu[‘省份’])
4 单选(1分)
假定DataFrame对象 temp中共有12列, 语句________删除空值(NaN)个数大于3的行。
A.temp.dropna(threshold = 8)
B.temp.dropna(threshold = 9)
C.temp.dropna(threshold = 7)
D.temp.dropna(threshold = 10)
5 单选(1分)
调用DataFrame对象temp的 fillna方法填充空值时,设置________参数可以控制是否直接更新temp对象。
A.now
B.method
C.threshold
D.inplace
6 单选(1分)
使用merge方法对DataFrame对象temp1和temp2进行列上的合并时,设置参数________,实现按照两个对象键值的交集进行合并。
A.how=inner
B.how=left
C.how=right
D.how=outer
7 单选(1分)
可以使用DataFrame对象的corr()方法求两列数据的相关系数,关于相关系数的描述中________是正确的。
A.相关系数是一个大于0小于1的值
B.不能通过相关系数判断两列数据的相关性
C.相关系数为零时两列数据相关性最小
D.相关系数越大,两列数据的相关性越弱
不太明白为啥a选项是错的
8 判断(1分)
dataFrame对象使用sort_values方法按照某列进行排序后,只有该列数据按顺序调整位置,其他列保此原顺序不变。
A.×
B.√
9 填空(1分)
数据记录了我国4个直辖市第一(种植业、林业、牧业和渔业)、第二(采掘业,制造业,电力、煤气、水的生产和供应业、建筑业)、第三产业(其他)2017年产值的增加量(单位:亿元)。创建了如下数据表:
from pandas import DataFrame
data = [[98.99,9251.40,20783.47],[ 120.45,5310.63,22569.27],[218.28,7590.36,10786.74],[1339.62,8596.61,9564.04]]
value=DataFrame(data,index=[‘上海’,‘北京’,‘天津’,‘重庆’], columns =[‘第一’,‘第二’,‘第三’])
现在需要在value中新增一列‘总增量’,记录每个城市的三类产业产值增量总和,使用语句:
value[‘________’] =value.sum(axis = 1)
总增量
10 填空(1分)
清洗数据有滤除和填充两种方法,当数据集比较小时,应尽量选择数据________的方式来清洗数据。
填充
第四次单元测验 数据可视化 答案
1 单选(1分)
下面关于使用pyplot和pandas提供的绘图函数的说法中,错误的是_________。
A.Series、DataFrame对象都提供plot()函数
B.pandas提供的绘图函数使用更快捷
C.相比较pandas绘图,pyplot提供更多图元绘制函数,能提供更精细的绘图方式
D.在同一figure对象中,pyplot和pandas的绘图函数不可以混合使用
2 单选(1分)
比较3个班级学生高数成绩的分位数分布并观察异常值,可选择_________。
A.密度图
B.箱须图
C.直方图
D.柱状图
3 单选(1分)
绘制多个子图的正确方法是_________。
A.导入matplotlib.pyplot库,创建figure对象,调用figure.add_subplot函数
B.导入pandas.pyplot库,创建figure对象,调用figure.subplot函数
C.导入matplotlib.pyplot库,创建figure对象,调用figure.subplot函数
D.导入pandas.pyplot库,创建figure对象,调用figure.add_subplot函数
4 单选(1分)
下面关于直方图的说法中,错误的是_________。
A.每个区间上长方形的高度表示该区间样本的频率
B.分箱的数量与数据集的分布无关
C.直方图的横坐标按区间个数等分
D.直方图可用来描述总体的频数分布情况
5 单选(1分)
关于饼图的描述,错误的是_________。
A.描述总体的样本值的构成比
B.描述总体各样本区间的样本数量
C.反映样本部分与整体之间的数量关系
D.每个扇形表示一类样本占总体的百分比
6 多选(1分)
_________可用于展示离散数据。
A.柱状图
B.折线图
C.曲面图
D.饼图
7 填空(1分)
观察男、女同学对“数据科学”课程的兴趣程度与课程成绩之间的关系,应使用分组_________。
散点图
8 填空(1分)
DataFrame对象temp记录了8个城市4个季度的第三产业产值,利用DataFrame.plot绘制柱状图时,可以设置参数_________控制画堆叠或复式柱状图。
stacked
9 填空(1分)
利用Series.plot绘制概率密度图时,将kind参数设置为_________。
kde
不明白为啥答案里不需要加引号
10 填空(1分)
观察样本多个属性值两两之间的相关性,可采用pandas提供了散点图矩阵pd.plotting._________函数。
scatter_matrix