推荐系统评测
文章目录
- 一、推荐系统实验方法
-
- 1.1 离线实验
- 1.2 用户调查
- 1.3 在线实验
- 二、评测指标
- 三、测评维度
在推荐系统的早期研究中,很多人将好的推荐系统定义为能够作出准确预测的推荐系统。比如,一个图书推荐系统预测一个用户将来会购买《 C++ Primer中文版》这本书,而用户后来确实购买了,那么这就被看做一次准确的预测。预测准确度是推荐系统领域的重要指标(没有之一)。这个指标的好处是,它可以比较容易地通过离线方式计算出来,从而方便研究人员快速评价和选择不同的推荐算法。
但是,很多研究表明,准确的预测并不代表好的推荐。 比如说,该用户早
就准备买《 C++ Primer中文版》了,无论是否给他推荐,他都准备购买,那么这个推荐结果显然是不好的,因为它并未使用户购买更多的书,而仅仅是方便用户购买一本他本来就准备买的书。那么,对于用户来说,他会觉得这个推荐结果很不新颖,不能令他惊喜。同时,对于《 C++ Primer中文版》的出版社来说,这个推荐也没能增加这本书的潜在购买人数。所以,这是一个看上去很好,但其实却很失败的推荐。举一个更极端的例子,某推测系统预测明天太阳将从东方升起,虽然预测准确率是100%,却是一种没有意义的预测。
所谓好的推荐系统不仅仅能够准确预测用户的行为,而且能够扩展用户的视野,帮助用户发现那些他们可能会感兴趣,但却不那么容易发现的东西。同时,推荐系统还要能够帮助商家将那些被埋没在长尾中的好商品介绍给可能会对它们感兴趣的用户。
为了全面评测推荐系统对三方利益的影响,本文将从不同角度出发,提出不同的指标。这些指标包括准确度、覆盖度、新颖度、惊喜度、信任度、透明度等。这些指标中,有些可以离线计算,有些只有在线才能计算,有些只能通过用户问卷获得。下面各节将会依次介绍这些指标的出发点、含义,以及一些指标的计算方法。
一、推荐系统实验方法
在介绍推荐系统的指标之前,首先看一下计算和获得这些指标的主要实验方法。在推荐系统中,主要有3种评测推荐效果的实验方法,即离线实验( offline experiment)、用户调查( user study)和在线实验( online experiment)。
1.1 离线实验
离线实验的方法一般由如下几个步骤构成:
- (1) 通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集;
- (2) 将数据集按照一定的规则分成训练集和测试集;
- (3) 在训练集上训练用户兴趣模型,在测试集上进行预测;
- (4) 通过事先定义的离线指标评测算法在测试集上的预测结果。
推荐系统的离线实验都是在数据集上完成的,也就是说它不需要一个实际的系统来供它实验,而只要有一个从实际系统日志中提取的数据集即可。
优点:不需要真实用户参与,可以直接快速地计算出来,从而方便、快速地测试大量不同的算法。
缺点:无法获得很多商业上关注的指标,如点击率、转化率等,而找到和商业指标非常相关的离线指标也是很困难的事情。

1.2 用户调查
离线实验的指标和实际的商业指标存在差距,比如预测准确率和用户满意度之间就存
在很大差别,高预测准确率不等于高用户满意度。因此,如果要准确评测一个算法,需要相对比较真实的环境。最好的方法就是将算法直接上线测试,但在对算法会不会降低用户满意度不太有把握的情况下,上线测试具有较高的风险,所以在上线测试前一般需要做一次称为用户调查的测试。
用户调查是推荐系统评测的一个重要工具,很多离线时没有办法评测的与用户主观感受有关的指标都可以通过用户调查获得。比如,如果我们想知道推荐结果是否很令用户惊喜,那我们最好直接询问用户。
优点:可以获得很多体现用户主观感受的指标,相对在线实验风险很低,出现错误后很容易弥补。
缺点:招募测试用户代价较大,很难组织大规模的测试用户,因此会使测试结果的统计意义不足。此外,在很多时候设计双盲实验非常困难,而且用户在测试环境下的行为和真实环境下的行为可能有所不同,因而在测试环境下收集的测试指标可能在真实环境下无法重现。
1.3 在线实验
在完成离线实验和必要的用户调查后,可以将推荐系统上线做AB测试,将它和旧的算法进行比较。
AB测试*:是一种很常用的在线评测算法的实验方法。它通过一定的规则将用户随机分成几组,并对不同组的用户采用不同的算法,然后通过统计不同组用户的各种不同的评测指标比较不同算法,比如可以统计不同组用户的点击率,通过点击率比较不同算法的性能。
优点:可以公平获得不同算法实际在线时的性能指标,包括商业上关注的指标。
缺点:周期比较长,必须进行长期的实验才能得到可靠的结果。此外,一个大型网站的AB测试系统的设计也是一项复杂的工程。
切分流量是AB测试中的关键,不同的层以及控制这些层的团队需要从一个统一的地
方获得自己AB测试的流量,而不同层之间的流量应该是正交的。
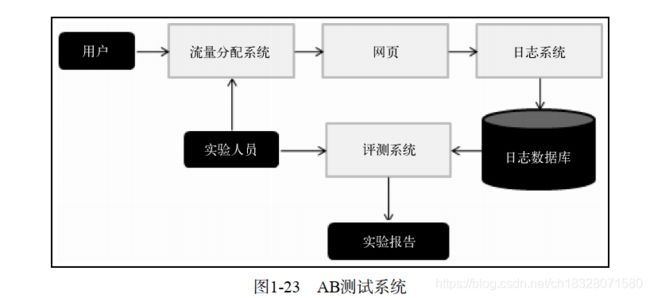
图1-23是一个简单的AB测试系统。用户进入网站后,流量分配系统决定用户是否需要被进行AB测试,如果需要的话,流量分配系统会给用户打上在测试中属于什么分组的标签。然后用户浏览网页,而用户在浏览网页时的行为都会被通过日志系统发回后台的日志数据库。此时,如果用户有测试分组的标签,那么该标签也会被发回后台数据库。在后台,实验人员的工作首先是配置流量分配系统,决定满足什么条件的用户参加什么样的测试。其次,实验人员需要统计日志数据库中的数据,通过评测系统生成不同分组用户的实验报告,并比较和评测实验结果。
一般来说,一个新的推荐算法最终上线,需要完成上面所说的3个实验。
- 首先,需要通过离线实验证明它在很多离线指标上优于现有的算法。
- 然后,需要通过用户调查确定它的用户满意度不低于现有的算法。
- 最后,通过在线的AB测试确定它在我们关心的指标上优于现有的算法。
二、评测指标
本节将介绍各种推荐系统的评测指标。这些评测指标可用于评价推荐系统各方面的性能。这些指标有些可以定量计算,有些只能定性描述,有些可以通过离线实验计算,有些需要通过用户调查获得,还有些只能在线评测。
1. 用户满意度
用户作为推荐系统的重要参与者,其满意度是评测推荐系统的最重要指标。但是,用户满意度没有办法离线计算,只能通过用户调查或者在线实验获得。
用户调查获得用户满意度主要是通过调查问卷的形式。用户对推荐系统的满意度分为不同的层次。
在在线系统中,用户满意度主要通过一些对用户行为的统计得到。比如在电子商务网站中,用户如果购买了推荐的商品,就表示他们在一定程度上满意。因此,我们可以利用购买率度量用户的满意度。此外,有些网站会通过设计一些用户反馈界面收集用户满意度。比如在视频网站Hulu的推荐页面和豆瓣网络电台中,都有对推荐结果满意或者不满意的反馈按钮,通过统计两种按钮的单击情况就可以度量系统的用户满意度。更一般的情况下,我们可以用点击率、用户停留时间和转化率等指标度量用户的满意度。
2. 预测准确度
预测准确度度量一个推荐系统或者推荐算法预测用户行为的能力。这个指标是最重要的推荐系统离线评测指标,从推荐系统诞生的那一天起,几乎99%与推荐相关的论文都在讨论这个指标。这主要是因为该指标可以通过离线实验计算,方便了很多学术界的研究人员研究推荐算法。
在计算该指标时需要有一个离线的数据集,该数据集包含用户的历史行为记录。然后,将该数据集通过时间分成训练集和测试集。最后,通过在训练集上建立用户的行为和兴趣模型预测用户在测试集上的行为,并计算预测行为和测试集上实际行为的重合度作为预测准确度。
由于离线的推荐算法有不同的研究方向,因此下面将针对不同的研究方向介绍它们的预测准确度指标。
(1)评分预测
很多提供推荐服务的网站都有一个让用户给物品打分的功能。那么,如果知道了用户对物品的历史评分,就可以从中习得用户的兴趣模型,并预测该用户在将来看到一个他没有评过分的物品时,会给这个物品评多少分。预测用户对物品评分的行为称为评分预测。
评分预测的预测准确度一般通过均方根误差( RMSE)和平均绝对误差( MAE)计算。对于测试集中的一个用户u和物品i,令 r u i r_{ui} rui是用户 u u u对物品 i i i的实际评分,而 r ^ u i \hat{r}_{ui} r^ui 是推荐算法给出的预测评分,那么RMSE的定义为:
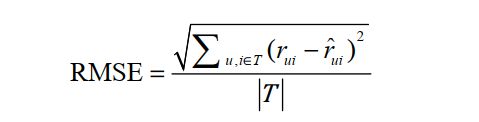
MAE采用绝对值计算预测误差,它的定义为:

关于RMSE和MAE这两个指标的优缺点, Netflix认为RMSE加大了对预测不准的用户物品评分的惩罚(平方项的惩罚),因而对系统的评测更加苛刻。研究表明,如果评分系统是基于整数建立的(即用户给的评分都是整数),那么对预测结果取整会降低MAE的误差。
(2)TopN推荐
网站在提供推荐服务时,一般是给用户一个个性化的推荐列表,这种推荐叫做TopN推荐。TopN推荐的预测准确率一般通过准确率( precision) /召回率( recall)度量.
令R(u)是根据用户在训练集上的行为给用户作出的推荐列表,而T(u)是用户在测试集上的行为列表。那么,推荐结果的召回率定义为:
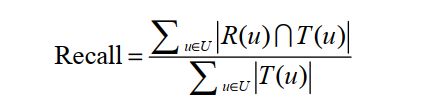
推荐结果的准确率定义为:
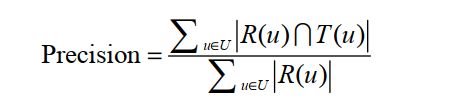
有的时候,为了全面评测TopN推荐的准确率和召回率,一般会选取不同的推荐列表长度N,计算出一组准确率/召回率,然后画出准确率/召回率曲线( precision/recall curve)。
3. 覆盖率
覆盖率( coverage)描述一个推荐系统对物品长尾的发掘能力。覆盖率有不同的定义方法,最简单的定义为推荐系统能够推荐出来的物品占总物品集合的比例。假设系统的用户集合为U,推荐系统给每个用户推荐一个长度为N的物品列表R(u)。那么推荐系统的覆盖率可以通过下面的公式计算:
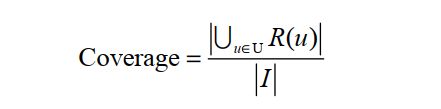
上面的定义过于粗略。覆盖率为100%的系统可以有无数的物品流行度分布。为了更细
致地描述推荐系统发掘长尾的能力,需要统计推荐列表中不同物品出现次数的分布。如果所有的物品都出现在推荐列表中,且出现的次数差不多,那么推荐系统发掘长尾的能力就很好。因此,可以通过研究物品在推荐列表中出现次数的分布描述推荐系统挖掘长尾的能力。如果这个分布比较平,那么说明推荐系统的覆盖率较高,而如果这个分布较陡峭,说明推荐系统的覆盖率较低。
在信息论和经济学中有两个著名的指标可以用来定义覆盖率。
第一个是信息熵:

这里p(i)是物品i的流行度除以所有物品流行度之和。
第二个指标是基尼系数( Gini Index):
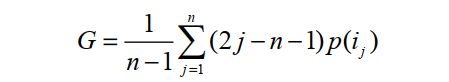
这里, i j i_j ij是按照物品流行度 p ( ) p() p()从小到大排序的物品列表中第j个物品。

推荐系统是否有马太效应呢?
推荐系统的初衷是希望消除马太效应,使得各种物品都能被展示给对它们感兴趣的某一类人群。但是,很多研究表明现在主流的推荐算法(比如协同过滤算法)是具有马太效应的。评测推荐系统是否具有马太效应的简单办法就是使用基尼系数。如果G1是从初始用户行为中计算出的物品流行度的基尼系数, G2是从推荐列表中计算出的物品流行度的基尼系数,那么如果G2 > G1,就说明推荐算法具有马太效应。
4. 多样性
多样性描述了推荐列表中物品两两之间的不相似性。因此,多样性和相似性是对应的。假设 s ( i , j ) ∈ [ 0 , 1 ] s( i ,j ) \in[0,1] s(i,j)∈[0,1] 定义了物品i和j之间的相似度,那么用户u的推荐列表R(u)的多样性定义如下:
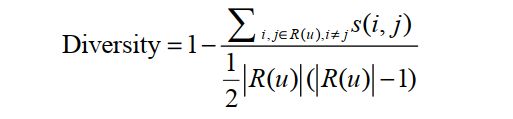
而推荐系统的整体多样性可以定义为所有用户推荐列表多样性的平均值:
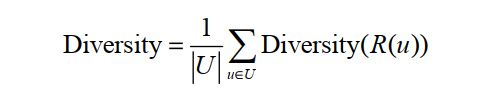
从上面的定义可以看到,不同的物品相似度度量函数 s ( i , j ) s(i, j) s(i,j)可以定义不同的多样性。如果用内容相似度描述物品间的相似度,我们就可以得到内容多样性函数,如果用协同过滤的相似度函数描述物品间的相似度,就可以得到协同过滤的多样性函数。
5. 新颖性
新颖的推荐是指给用户推荐那些他们以前没有听说过的物品。在一个网站中实现新颖性的最简单办法是,把那些用户之前在网站中对其有过行为的物品从推荐列表中过滤掉。比如在一个视频网站中,新颖的推荐不应该给用户推荐那些他们已经看过、打过分或者浏览过的视频。但是,有些视频可能是用户在别的网站看过,或者是在电视上看过,因此仅仅过滤掉本网站中用户有过行为的物品还不能完全实现新颖性。
6. 惊喜度
惊喜度( serendipity)是最近这几年推荐系统领域最热门的话题。但什么是惊喜度,惊喜度与新颖性有什么区别是首先需要弄清楚的问题。注意,这里讨论的是惊喜度和新颖度作为推荐指标在意义上的区别,而不是这两个词在中文里的含义区别(因为这两个词是英文词翻译过来的,所以它们在中文里的含义区别和英文词的含义区别并不相同), 惊喜度指如果推荐结果和用户的历史兴趣不相似,但却让用户觉得满意,那么就可以说推荐结果的惊喜度很高,而推荐的新颖性仅仅取决于用户是否听说过这个推荐结果。
惊喜度的问题最近几年获得了学术界的一定关注,但目前并没有什么公认的惊喜度指标定义方式,这方面的工作还不是很成熟。
7. 信任度
对于基于机器学习的自动推荐系统,如果用户信任推荐系统,那就会增加用户和推荐系统的交互。特别是在电子商务推荐系统中,让用户对推荐结果产生信任是非常重要的。同样的推荐结果,以让用户信任的方式推荐给用户就更能让用户产生购买欲,
而以类似广告形式的方法推荐给用户就可能很难让用户产生购买的意愿。
量推荐系统的信任度只能通过问卷调查的方式,询问用户是否信任推荐系统的推荐结果。
提高推荐系统的信任度主要有两种方法。首先需要增加推荐系统的透明度( transparency),而增加推荐系统透明度的主要办法是提供推荐解释。只有让用户了解推荐系统的运行机制,让用户认同推荐系统的运行机制,才会提高用户对推荐系统的信任度。其次是考虑用户的社交网络信息,利用用户的好友信息给用户做推荐,并且用好友进行推荐解释。这是因为用户对他们的好友一般都比较信任,因此如果推荐的商品是好友购买过的,那么他们对推荐结果就会相对比较信任。
8. 实时性
在很多网站中,因为物品(新闻、微博等)具有很强的时效性,所以需要在物品还具有时效性时就将它们推荐给用户。
推荐系统的实时性包括两个方面。首先,推荐系统需要实时地更新推荐列表来满足用户新的行为变化。如果推荐列表在用户有行为后变化不大,或者没有变化,说明推荐系统的实时性不高。实时性的第二个方面是推荐系统需要能够将新加入系统的物品推荐给用户。这主要考验了推荐系统处理物品冷启动的能力。
9. 健壮性
任何一个能带来利益的算法系统都会被人攻击,这方面最典型的例子就是搜索引擎。搜索引擎的作弊和反作弊斗争异常激烈,这是因为如果能让自己的商品成为热门搜索词的第一个搜索果,会带来极大的商业利益。推荐系统目前也遇到了同样的作弊问题,而健壮性(即robust,鲁棒性)指标衡量了一个推荐系统抗击作弊的能力。
算法健壮性的评测主要利用模拟攻击。首先,给定一个数据集和一个算法,可以用这个算法给这个数据集中的用户生成推荐列表。然后,用常用的攻击方法向数据集中注入噪声数据,然后利用算法在注入噪声后的数据集上再次给用户生成推荐列表。最后,通过比较攻击前后推荐列表的相似度评测算法的健壮性。如果攻击后的推荐列表相对于攻击前没有发生大的变化,就说明算法比较健壮。
在实际系统中,提高系统的健壮性,除了选择健壮性高的算法,还有以下方法。
- 设计推荐系统时尽量使用代价比较高的用户行为。比如,如果有用户购买行为和用户浏览行为,那么主要应该使用用户购买行为,因为购买需要付费,所以攻击购买行为的代价远远大于攻击浏览行为。
- 在使用数据前,进行攻击检测,从而对数据进行清理。
10. 商业目标
很多时候,网站评测推荐系统更加注重网站的商业目标是否达成,而商业目标和网站的盈利模式是息息相关的。一般来说,最本质的商业目标就是平均一个用户给公司带来的盈利。不过这种指标不是很难计算,只是计算一次需要比较大的代价。因此,很多公司会根据自己的盈利模式设计不同的商业目标。
11. 总结
本节提到了很多指标,其中有些指标可以离线计算,有些只能在线获得。但是,离线指标很多,在线指标也很多,那么如何优化离线指标来提高在线指标是推荐系统研究的重要问题。关于这个问题,目前仍然没有什么定论,只是不同系统的研究人员有不同的感性认识。
表1-3对前面提到的指标进行了总结。

对于可以离线优化的指标,我个人的看法是应该在给定覆盖率、多样性、新颖性等限制条件下,尽量优化预测准确度。用一个数学公式表达,离线实验的优化目标是:

其中, A、 B、 C的取值应该视不同的应用而定。
三、测评维度
在评测系统中还需要考虑评测维度,比如一个推荐算法,虽然整体性能不好,但可能在某种情况下性能比较好,而增加评测维度的目的就是知道一个算法在什么情况下性能最好。这样可以为融合不同推荐算法取得最好的整体性能带来参考。
一般来说,评测维度分为如下3种。
- 用户维度 主要包括用户的人口统计学信息、活跃度以及是不是新用户等。
- 物品维度 包括物品的属性信息、流行度、平均分以及是不是新加入的物品等。
- 时间维度 包括季节,是工作日还是周末,是白天还是晚上等。
如果能够在推荐系统评测报告中包含不同维度下的系统评测指标,就能帮我们全面地了解推荐系统性能,找到一个看上去比较弱的算法的优势,发现一个看上去比较强的算法的缺点。