机器学习与数据挖掘实验三:基于 CNN (VGG,GoogLeNet)的海面舰船图像分类【详细原理+python代码】
系列文章目录
机器学习与数据挖掘实验一:牛顿法,梯度下降实现对数几率回归【详细原理+python代码】
机器学习与数据挖掘实验二:以信息增益为划分准则构造决策树【例题求解】
机器学习与数据挖掘实验三:基于 CNN (VGG,GoogLeNet)的海面舰船图像分类【详细原理+python代码】
机器学习与数据挖掘实验四:基于特征工程的支持向量机分类实验【详细原理+python代码】
文章目录
- 系列文章目录
- 一、 问题重述
- 二、 实验环境与依赖库
-
- 2.1 实验环境
- 2.2 依赖库
- 三、 神经网络架构说明
-
- 3.1 GoogLeNet网络架构分析
-
- 3.1.1 Inception结构参数说明
- 3.1.2 辅助分类器参数说明
- 3.1.3 GoogLeNet网络架构流程说明
- 3.2 VGG网络架构分析
-
- 3.2.1 VGG13特征提取结构流程说明
- 3.2.2 VGG13分类网络结构
- 四、 网络参数设计
-
- 4.1 GoogLeNet网络参数
- 4.2 VGG13网络参数.
- 五、 网络训练结果分析
-
- 5.1 GoogLeNet结果分析
-
- 5.1.1 GoogLeNet损失函数与验证集准确率分析
- 5.1.2 GoogLeNet海面舰船数据二分类性能分析
- 5.2 VGG13结果分析.
-
- 5.2.1 VGG13损失函数与验证集准确率分析
- 5.2.2 VGG13海面舰船数据二分类性能分析
- 5.3 GoogLeNet和VGG13网络结果对比.
-
- 5.3.1 损失函数与验证集准确率对比
- 5.3.2 海面舰船数据二分类性能对比
- 六、 模型可解释性分析
-
- 6.1 grad-cam原理
- 6.2 VGG13和GoogLeNet网络可解释性分析
一、 问题重述
通过VGG13和GoogLeNet实现对海面舰船数据的二分类任务(船类和非船类)。数据集包括 3000 张海面图片和 1000 张舰船图片。针对以上问题,将其分为四个部分进行分析:
- 构建VGG13和GoogLeNet神经网络模型,分析模型网络架构。
- 对VGG13和GoogLeNet神经网络设置不同参数并通过Pytorch进行训练。
- 对比VGG13和GooLeNet网络在不同参数下的分类性能,绘制损失函数和验证集准确率随epoch的变化曲线。
- 通过gram-cam对VGG13和GoogLeNet网络进行可解释性分析。
数据集+代码下载
二、 实验环境与依赖库
2.1 实验环境
为了便于模型的训练,在本地编写代码,然后将其移植到Kaggle Kernel进行运行。其硬件环境配置如图所示。
2.2 依赖库
实验采用Pytorch框架,依赖库名称、版本与功能如表所示。
| 依赖库名称 | 依赖库版本 | 依赖库功能 |
|---|---|---|
| torch | 1.6.0 | 在图形处理单元上计算张量 |
| torchvision | 0.7.0 | 包含流行的数据集,模型结构和常用的图片转换工具 |
| tqdm | 4.63.0 | 用于显示进度,创建、关闭进度条 |
| Pillow | 8.4.0 | 包含图像的基本处理函数 |
三、 神经网络架构说明
在3.1小节中,对于GoogLeNet网络的架构进行分析,并给出其使用的卷积层,池化层,全连接层等基础结构的数目。在3.2小节中,对于VGG13网络的架构进行分析,并给出其使用的卷积层,池化层,全连接层等基础结构的数目。
3.1 GoogLeNet网络架构分析
GoogLeNet在 2014 年由Google团队提出,其网络结构相比于其他网络主要特点在于以下两点:
- 引入了Inception结构,并使用1x1的卷积核进行降维以及映射处理。
- 添加两个辅助分类器帮助训练。
GoogLeNet网络架构共有 27 层,其中卷积层共有 21 层,全连接层共有 1 层,池化层共有 14 层(包含Inception分支中的池化层)。
3.1.1 Inception结构参数说明
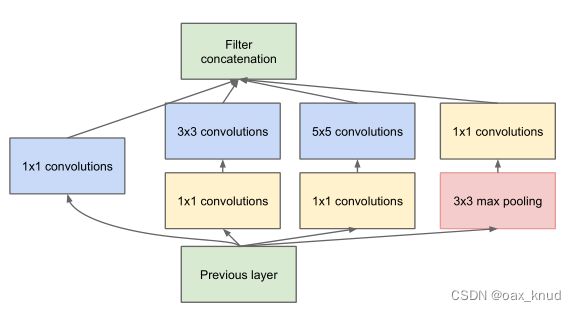
Inception结构可以融合不同尺度的特征信息,其结构如图所示。Inception结构共有 4 个分支,输入的特征矩阵并行的通过这四个分支得到四个输出,然后在深度维度(channel维度)将这四个输出在进行拼接,得到最终输出。为保证四个分支的输出能够在深度方向进行拼接,因此四个分支输出的特征矩阵高度和宽度都相同。
因此,可以总结出Inception结构与传统多通道卷积不同之处共有两点:
-
使用了多个不同尺寸的卷积核,添加池化操作,将卷积和池化结果进行串联。Inception的核心思想是找出最优的局部稀疏结构并将其覆盖为近似的稠密组件,因此,将不同的局部结构通过在channel维度拼接实现组合。
-
卷积之前有 1 × 1 的卷积操作,池化之后有 1 × 1 的卷积操作。 1 × 1 的卷积操作将传统的线性模型变成非线性模型,将高相关性节点组合到了一起,具有更强的表达能力,同时减少了卷积参数个数。
由此,可以得到每个分支的卷积核大小,stride和padding。通过卷积核计算公式可以得到每个分支的具体参数如表所示。
| 卷积名称 | kernel | size | stride | padding |
|---|---|---|---|---|
| 1 ×1 | convolutions | 1 × 1 | 1 | 1 |
| 3 ×3 | convolutions | 3 × 3 | 1 | 1 |
| 5 ×5 | convolutions | 5 × 5 | 1 | 2 |
| 3 ×3 | max pooling | 3 × 3 | 1 | 1 |
3.1.2 辅助分类器参数说明
根据实验数据,研究员发现神经网络的中间层具有很强的识别能力,为了利用中间层抽象的特征,在某些中间层中添加含有多层的分类器,如图所示。

由此,可以得到平均池化层,卷积层的参数如表所示
| kernel | size | stride | padding |
|---|---|---|---|
| convolutions | 5×5 | 3 | 0 |
| convolutions | 1×1 | 1 | 0 |
全连接层的参数如下表所示。
| 层次名称 | 输入 特征数目 | 输出特征数目 |
|---|---|---|
| FC1 | 2048 | 1024 |
| FC2 | 1024 | 1000 |
3.1.3 GoogLeNet网络架构流程说明
由于GoogLeNet的网络较深,因此,将其网络结构按照模块进行划分进行分析。其结构由基础卷积结构,Inception结构,辅助分类器三个子结构构成。
其中基础卷积结构由一个卷积层和一个ReLU激活函数组成。Inception结构由 4 个分支组成,包括 4 个1*1基础卷积结构, 1 个3*3基础卷积结构, 1 个5*5基础卷积结构和 1 个最大池化层。辅助分类器包括 1 个平均池化下采样层, 1 个1*1基础卷积结构,2 个全连接层。
1 、低层特征提取
低层的特征提取需要分别经过 3 个基础卷积结构, 2 个最大池化层, 2 个LPN结构。其中LPN为局部响应归一化操作,增强了模型的泛化能力,在这里不做分析。低层结构
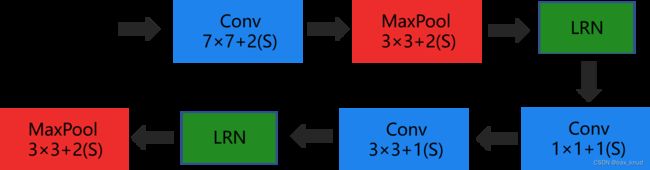
假设输入图片在经过初始化操作后得到的尺寸为3224224(channel*height*weight)。经过上图的层次结构,图片的大小变化如下。
- conv1:输入3*224*224的图片,经过64个7*7的基础卷积结构以stride=2,padding=3进行卷积计算,得到输出图片大小为64*112*112。
- maxpool1:输入图片大小为64*112*112,经3*3的池化单元,以stride=2进行池化运算得到输出图片大小为64*56*56。
- conv2:输入64*56*56的图片,经过 64 个1*1的基础卷积结构以stride=1,进行卷积计算,得到输出图片大小为64*56*56。
- conv3:输入64*56*56的图片,经过 192 个3*3的基础卷积结构以stride=1,padding=1进行卷积计算,得到输出图片大小为1925656。
- maxpool2:输入图片大小为192*56*56,经3*3的池化单元,以stride=2进行池化运算得到输出图片大小为192*28*28。
2 、Inception特征提取
在Inception特征提取中,包括 9 个Inception结构,两个最大池化结构。对于Inception结构,其卷积核的大小,stride,padding参数是固定的,如表 2 所示。因此,在分析网络结构时,根据卷积计算公式以及参数可以计算输入图片通道,高,宽的变化情况。首先,对于每一种基础卷积结构的卷积核数目变量名进行说明,如图所示。
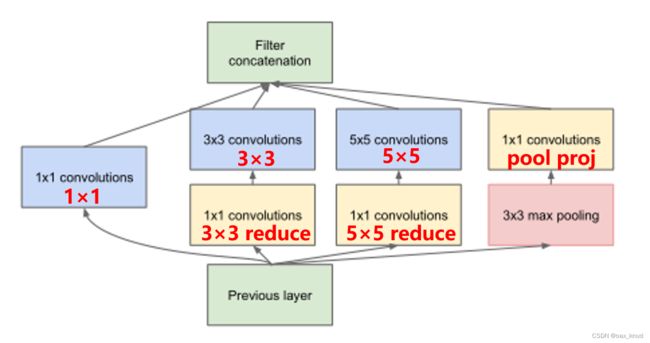
根据论文Going Deeper with Convolutions中GoogLeNet的Inception结构基础卷积结构参数表可以得知 9 个Inception结构的具体卷积核数目如表:
| 层次名称 | 1×1 | 3×3 | reduce 3×3 | 5×5 | reduce 5×5 | pool proj |
|---|---|---|---|---|---|---|
| Inception3a | 64 | 96 | 128 | 16 | 32 | 32 |
| Inception3b | 128 | 128 | 192 | 32 | 96 | 64 |
| Inception4a | 192 | 96 | 208 | 16 | 48 | 64 |
| Inception4b | 160 | 112 | 224 | 24 | 64 | 64 |
| Inception4c | 128 | 128 | 256 | 24 | 64 | 64 |
| Inception4d | 112 | 144 | 288 | 32 | 64 | 64 |
| Inception4e | 256 | 160 | 320 | 32 | 128 | 128 |
| Inception5a | 256 | 160 | 320 | 32 | 128 | 128 |
| Inception5b | 384 | 192 | 384 | 48 | 128 | 128 |
- Inception3:输入192*28*28的图片,经过Inception3a卷积计算后得到256*28*28的图片,然后经过Inception3b卷积计算后得到输出图片大小为480*28*28。
- maxpool3:输入图片大小为480*28*28,经3*3的池化单元,以stride=2进行池化运算得到输出图片大小为480*14*14。
- Inception4:输入图片大小为480*14*14,分别经过Inception4a,4b,4c,4d,4e后得到输出图片大小为832*14*14。
具体图片变换数据如图所示。

- maxpool4:输入图片大小为832*14*14,经3*3的池化单元,以stride=2进行池化运算得到输出图片大小为832*7*7。
- Inception5:输入832*7*7的图片,经过Inception5a卷积计算后得到832*7*7的图片,然后经过Inception5b卷积计算后得到输出图片大小为1024*7*7。
3 、分类器
GoogLeNet网络的分类器共有三个: 2 个辅助分类器和 1 个最终分类器。其中,辅助分类器的具体参数和结构3.1.2中的参数表所示。最终分类器由一个平均池化下采样层和一个全连接层组成。具体网络架构描述如下:
- avgpool1:输入图片大小为1024*7*7,经7*7的池化单元,以stride=1进行池化运算得到输出图片大小为1024*1*1。然后将图片的特征向量进行展平操作,经过 dropout结构使40%的神经元失活。
- fc1:输入图片大小为1024*1*1,经过一层全连接结构然后将结果通过softmax结构输出指定要求的预测结果数目。
3.2 VGG网络架构分析
VGG网络在 2014 年由牛津大学著名研究组VGG (Visual Geometry Group)提出,其特点主要在于通过堆叠多个 3 × 3 的卷积核来替代大尺度卷积核使其拥有相同的感受野但大大减少了网络参数。接下来以VGG13网络为例进行VGG网络架构的分析。
VGG13网络架构共有 18 层,其中有卷积层 10 层,全连接层 3 层,池化层 5 层,ReLU激活函数 12 个。接下来将VGG13网络分为特征提取结构和分类网络结构进行详细分析。
3.2.1 VGG13特征提取结构流程说明
在VGG13的特征提取结构中,主要由3*3大小的卷积层以及2*2大小的最大池化层组成。对于每一个卷积层和池化层,其stride,padding固定,如表所示:
| name | kernel | size | stride | padding |
|---|---|---|---|---|
| 2 ×2 | maxpooling | 2 × 2 | 2 | 0 |
| 3 ×3 | convolutions | 3 × 3 | 1 | 1 |
根据卷积计算公式,我们可以得到每一层网络输入输出图片大小如图 所示:其中,convX-Y表示卷积核大小为X,卷积核个数为Y。

3.2.2 VGG13分类网络结构
VGG13的分类网络结构包括 3 个全连接层, 2 个ReLU激活函数以及 2 个dropout层。具体网络架构流程如下:
- fc1:输入图片大小为512*7*7,首先经过dropout结构使50%的神经元失活,然后经过一层全连接层,得到输出向量大小为4096*1*1,最后经过ReLU激活函数。
- fc2:输入向量大小为4096*1*1,首先经过dropout结构使50%的神经元失活,然后经过一层全连接层,得到输出向量大小为4096*1*1,最后经过ReLU激活函数。
- fc3:输入向量大小为4096*1*1,经过一层全连接结构然后将结果通过softmax结 构输出指定要求的预测结果数目。
四、 网络参数设计
对于VGG13网络和GoogLeNet网络,首先设定其通用参数如表所示。
| 总样本数 | 训练集:验证集 | Batch size | Iteration |
|---|---|---|---|
| 4000 | (sea:ship=3:1 ) | 8:2 | 32 |
在固定通用参数的前提下,我对于VGG13和GoogLeNet网络的参数进行调整。在4.1小节对VGG13网络的优化器,epoch,学习率进行说明;在4.2小节对GoogLeNet网络的优化器,epoch,学习率进行说明。
4.1 GoogLeNet网络参数
为对比不同参数下的GoogLeNet神经网络分类性能,对训练epoch,学习率和优化器的参数进行调整,其参数如表所示。
| 模型序号 | 学习率 | 优化器 | Epoch |
|---|---|---|---|
| GoogLeNet_v1 | 0.0001 | Adma | 70 |
| GoogLeNet_v2 | 0.001 | Adma | 70 |
| GoogLeNet_v3 | 0.0001 | RMSprop | 80 |
这里未选择SGD优化器是因为经过尝试,验证集准确率持续维持在75%,无法提高。
4.2 VGG13网络参数.
为对比不同参数下的VGG13神经网络分类性能,对训练epoch,学习率和优化器的参数进行调整,其参数如下表所示。
| 模型序号 | 学习率 | 优化器 | Epoch |
|---|---|---|---|
| vgg13_v1 | 0.0001 | Adma | 50 |
| vgg13_v2 | 0.001 | Adma | 50 |
| vgg13_v3 | 0.0001 | SGD | 80 |
五、 网络训练结果分析
5.1 GoogLeNet结果分析
5.1.1 GoogLeNet损失函数与验证集准确率分析
通过调整GoogLeNet网络的优化器,学习率和epoch,可以得到三个在海面舰船数据上的分类模型。绘制损失函数与验证集准确率随epoch的变化曲线如图所示。
可以看出,Googlenet_v1在第 40 个epoch时实现收敛,Googlenet_v2网络在第 70 个epoch时已经收敛,而Googlenet_v3则在第 80 个epoch时才实现收敛。
对比三个不同参数版本的GoogLeNet网络可以得到以下结论:
- 从优化器来看,RMSprop优化器相比于adam优化器需要更长的时间才能使模型收敛。但在同等学习率的条件下,RMSprop优化器具有更高的验证集准确率。
- 从学习率来看,对于adam优化器来说,学习率对于验证集准确率影响较小,但对于损失函数曲线,小学习率的GoogLeNet_v1网络在收敛时损失函数呈现一个平稳趋势,而大学习率的GoogLeNet_v2网络在收敛是损失函数曲线波动性较大。
通过对比三个参数版本的GoogLeNet网络,可以得到使用RMSprop优化器在学习率为0.0001条件下训练的GoogLeNet_v3网络的泛化能力最强,准确率最高。
5.1.2 GoogLeNet海面舰船数据二分类性能分析
对于三个不同参数版本的GoogLeNet网络,分别计算其验证集上的网络分类性能指标accuracy,precision,recall,F1;同时记录在GPU条件下将验证集 800 张图片输入网络得到分类结果所消耗的时间,如表所示。
| 序号 | Accuracy | Precision | Recall | F1 | 验证集上消耗时间(s) |
|---|---|---|---|---|---|
| GoogLeNet_v1 | 0.9762 | 0.9252 | 0.9900 | 0.9565 | 4.497234 |
| GoogLeNet_v2 | 0.9850 | 0.9522 | 0.9950 | 0.9731 | 4.142345 |
| GoogLeNet_v3 | 0.9912 | 0.9709 | 1.0000 | 0.9852 | 4.609834 |
通过表 10 可以得到如下结论:
- 从网络性能角度来看,GoogLeNet网络在以学习率0.0001的RMSprop优化器条件下可以训练得到最优的性能,准确率高达99.12%;其他优化器(adam)或者升高学习率都会使得网络分类性能下降。
- 从验证集上消耗时间来看,三个不同参数的网络消耗的时间均处于4.0-4.7秒之间,耗时差异较小。
5.2 VGG13结果分析.
5.2.1 VGG13损失函数与验证集准确率分析
通过调整VGG13网络的优化器,学习率和epoch,可以得到三个在海面舰船数据上的分类模型。绘制损失函数与验证集准确率随epoch的变化曲线如图所示。
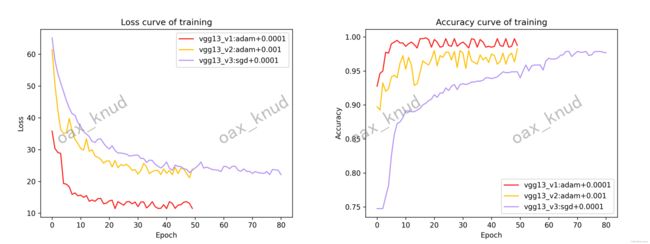
可以看出,VGG13_v1和VGG13_v2网络在第 50 个epoch时已经收敛,而VGG13_v3则在第 80 个epoch时才实现收敛。
对比三个不同参数版本的VGG13网络可以得到以下结论:
- 从优化器来看,SGD优化器相比于adam优化器需要更长的时间才能使模型收敛,除此之外,在同等学习率的情况下,SGD优化器的模型最终在验证集上的准确率低于adam优化器。
- 从学习率来看,更小的学习率在数据集上呈现了更好的效果。在相同优化器的情况下,VGG13_v2网络相比于VGG13_v1网络最终的损失较高,其验证集的准确率较低。
- 从收敛情况看,adam优化器在最后收敛情况下的曲线波动大于sgd优化器。SGD优化器一旦收敛,其损失函数和验证集准确率的稳定性较高。
通过对比三个不同参数版本的VGG13网络,可以得到使用adma优化器在学习率为0.0001条件下训练的VGG13_v1网络的泛化能力最强,准确率最高。
5.2.2 VGG13海面舰船数据二分类性能分析
对于三个版本参数的VGG13网络,分别计算其验证集上的网络分类性能指标accuracy,precision,recall,F1;同时记录在GPU条件下将验证集 800 张图片输入网络得到分类结果所消耗的时间。如表所示:
| 序号 | Accuracy | Precision | Recall | F1 | 验证集上消耗时间(s) |
|---|---|---|---|---|---|
| Vgg13_v1 | 0.9975 | 0.9950 | 1.0000 | 0.9975 | 8.991666 |
| Vgg13_v2 | 0.9810 | 0.9523 | 0.9930 | 0.9710 | 8.703859 |
| Vgg13_v3 | 0.9765 | 0.9481 | 0.9750 | 0.9610 | 8.703859 |
由此可以得到以下结论:
- 从网络性能角度来看,VGG13网络在以学习率0.0001的adam优化器条件下可以训练得到最优的性能,准确率高达99.75%;而是用其他优化器(SGD)或者降低学习率都会使得网络分类性能下降。
- 从验证集上消耗时间来看,三个参数的网络消耗的时间均处于8.7-9.0秒之间,耗时差异较小。
5.3 GoogLeNet和VGG13网络结果对比.
通过5.1.2和5.2.2,可以得到GoogLeNet和VGG13网络的最佳参数,在这里,选择VGG13_v1和GoogLeNet_v3进行对比。
5.3.1 损失函数与验证集准确率对比
绘制VGG13_v1和GoogLeNet_v3损失函数和验证集准确率随epoch的变化曲线如图:

通过对比,可以得到如下结论:
- 从收敛时间来看,VGG13_v1网络比GoogLeNet_v3网络收敛时间更快,VGG13_v在大约第 20 个epoch后曲线趋于平稳;GoogLeNet_v3在大约第 50 个epoch后曲线趋于平稳。
- 从学习率来看,在相同学习率的情况下收敛时,VGG13_v1网络比GoogLeNet_v网络曲线波动更小。
- 从准确率和损失函数数值来看,VGG13_v1在训练集上的损要明显低于GoogLeNet_v3,在准确率上略高于GoogLeNet_v3。
5.3.2 海面舰船数据二分类性能对比
对于VGG13_v1和GoogLeNet_v3网络,分别计算其验证集上的网络分类性能指标accuracy,precision,recall,F1;同时记录在GPU条件下将验证集 800 张图片输入网络得到分类结果所消耗的时间。如表所示。
| 序号 | Accuracy | Precision | Recall | F1 | 验证集上消耗时间(s) |
|---|---|---|---|---|---|
| VGG13_v1 | 0.9975 | 0.9950 | 1.0000 | 0.9975 | 8.991666 |
| GoogLeNet_v3 | 0.9912 | 0.9709 | 1.0000 | 0.9852 | 4.609834 |
由此可以得到以下结论:
- 可以看出VGG13_v1在验证集上消耗的时间较长,分析原因是因为VGG13_v1的参数相比于GoogLeNet_v3更多,因此分类的时间较长。
- 对比VGG13_v1和GoogLeNet_v3的分类性能,可以看出GoogLeNet_v3的准确率,精确度和F1略小于VGG13_v1,因此VGG13_v1的分类性能相比GoogLeNet_v更好。
六、 模型可解释性分析
6.1 grad-cam原理
为了更好的了解每个网络对于每个类别关注的重心在哪个位置,采用grad-cam对每个网络进行可解释性的分析。
参考了17年ICCV论文Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization对gradcam的原理进行一个简单的阐述。
首先,网络进行正向传播,得到特征层 A A A(一般是最后一个卷积层的输出)和网络预测值 y y y(sotfmax激活之前的预测值)。假设我们想要查看网络针对某一个类别感兴趣的区域是哪里,如果网络对于这个类别的预测值为 y c y^{c} yc。接着对 y c y^{c} yc进行反向传播,得到反传回特征层 A A A的梯度信息 A ′ A^{'} A′。通过计算得到特征层 A A A每个通道的重要程度,然后进行加权求和并通过relu函数的到最后grad-cam的结果。其计算公式如下:
L G r a d − C A M c = ReLU ( ∑ k α k c A k ) L_{\mathrm{Grad}-\mathrm{CAM}}^{c}=\operatorname{ReLU}\left(\sum_{k} \alpha_{k}^{c} A^{k}\right) LGrad−CAMc=ReLU(k∑αkcAk)
其中, A A A表示某个特征层, k k k表示特征层 A A A中第 k k k个通道, c c c表示关注的类别, A k A^{k} Ak表示特征层 A A A中第 k k k个通道的数据, α k c \alpha_{k}^{c} αkc表示对于类别 c c c,特征层 A A A第 k k k个通道的权重。
α k c = 1 Z ∑ i ∑ j ∂ y c ∂ A i j k \alpha_{k}^{c}=\frac{1}{Z} \sum_{i} \sum_{j} \frac{\partial y^{c}}{\partial A_{i j}^{k}} αkc=Z1i∑j∑∂Aijk∂yc
其中 y c y^{c} yc代表网络针对类别 c c c预测的分数,$ A_{i j}^{k} 表 示 特 征 层 表示特征层 表示特征层A 的 通 道 的通道 的通道k 中 , 坐 标 为 中,坐标为 中,坐标为ij 处 的 数 据 。 处的数据。 处的数据。Z$表示特征层宽度乘高度。
6.2 VGG13和GoogLeNet网络可解释性分析
我挑选了sea__20161103_195523_0c27__-
122.34831764039477_37.76678713050675.png和
sea__20170106_180851_0e30__-122.35408833815782_37.784718918384876.png两张图片进行分析,在这两张图片中均包含了海面和部分船舰。
在这里挑选VGG13网络的最后一个特征层maxpooling5以及GoogLeNet网络的inception5层输出结果进行grad-cam计算并分别绘制船舰类和非船舰类别的热力图如图所示。
通过图片可以看出,VGG13网络和GoogLeNet网络对于非船类别的侧重点在于海面部分,而对于船舰类别的侧重点在于船本身。因此们可以认为VGG13和GoogLeNet网络在学习图像非船类和船舰类时学习的特征是正确的。