Ontology-enhanced Prompt-tuning for Few-shot Learning
Ontology-enhanced Prompt-tuning for Few-shot Learning
本文仅供参考、交流、学习
论文地址:https://arxiv.org/abs/2201.11332
代码和数据集地址:暂无

1. 摘要
小样本学习(FSL)的目标是基于有限数量的样本进行预测。结构化数据(如知识图谱和本体库)已经被用来协助各种任务中的小样本情况。然而,现有方法所采用的先验存在知识缺失、知识噪声和知识异质性等问题,影响了小样本学习的性能。在本研究中,我们探讨基于预训练语言模型的FSL知识注入,并提出本体增强提示调优(OntoPrompt)。具体来说,我们开发了基于外部知识图的本体转换来解决知识缺失问题,实现了结构知识向文本的转换。在此基础上,引入了基于可见矩阵的跨敏感知识注入方法来选择信息丰富的知识,以解决知识噪声问题。为了弥合知识与文本之间的鸿沟,我们提出了一种集体训练算法来共同优化表示。我们用8个数据集,在关系抽取、事件抽取和知识图补全三个任务中评估了我们提出的OntoPrompt。实验结果表明,该方法可以获得比基线更好的小样本性能。

2. 小样本存在的问题
- 知识缺失: 由于外部知识库的不完备,知识注入可能无法检索到与任务相关的事实,从而无法为下游任务提供有用甚至无关的信息。如何丰富与任务相关的知识是一个重要的问题;
- 知识噪声: 以往的研究表明,并不是所有的知识都对下游任务有益,不加选择的知识注入可能导致负性知识注入,不利于下游任务的执行;
- 知识异质性: 下游任务的语言语料库与注入知识的语料库有很大的不同,导致两个独立的向量表示。如何设计一种融合知识信息的特殊联合训练目标是另一个挑战。
3. 解决方法
3.1 本体转换
本文提出了本体转换方法,将结构知识丰富并转化为文本形式。具体来说,我们利用预定义的模板作为提示将知识转换为文本。我们利用预定义的模板作为提示将知识转换为文本。提示调优可以减少训练前模型任务和下游任务之间的差距。例如,给定一个句子,“Turing entered King’s College, Cambridge in 1931, and then went to Princeton University to study for a doctorate,”我们可以根据本体将它们归纳为一个知识丰富的提示:“Turing [MASK] King’s College, Cambridge.”,语言模型应该在掩码位置预测标签字符,以确定输入的标签。需要注意的是,作为提示的本体将实体知识放置到输入文本中,该文本与模型无关,可以插入任何类型的预训练语言模型中。
3.2 基于广度敏感的知识注入
提出了基于广度敏感的知识i注入方法,以选择信息知识并降低注入噪声。由于并非所有的外部知识都能对下游任务有利,一些无关的、嘈杂的知识可能会导致原句的含义发生变化,我们利用一个基于广度的可见矩阵及其对应的外部知识对知识注入进行引导。这样,并不是输入句子中的所有标记都受到外部知识的影响。
3.3 集体训练算法
本文提出了一种集体训练算法来共同优化表示。注意,注入的外部知识应该与周围的环境相关联;我们添加了一些随机初始化的可学习标记,并对这些标记和注入的本体标记进行了优化。在之前的研究的启发下,低数据状态下的提示调优是不稳定的,可能会获得较差的性能,我们进一步优化所有参数,以集体训练本体文本和输入表示。
4. 具体方案
OntoPrompt是一个通用框架,可以应用于广泛的应用程序,如图2所示。我们在三个流行
任务中评估了我们的方法,即关系抽取(RE),事件抽取(EE)和知识图完成(KGC)。在注入本体知识的过程中,引入本体转换,将结构知识转化为原始文本(本体文本)。我们将这些原始文本视为辅助提示,并将它们附加到输入序列和提示模板中。请注意,那些本体文本,包括文本描述,可以提供关于上述实体/跨度的本体的语义信息。在微调过程中,我们将这些知识整合到广度敏感知识注入中,以避免外部干扰。我们进一步引入集体训练,共同优化提示和语言模型。
图2

4.1 带有提示调优的通用框架
设 X i n = { x 1 , x 2 , . . . , x L } X_{in}=\{x_1,x_2,...,x_L\} Xin={x1,x2,...,xL}是一个句子, x i x_i xi是输入句子中的第 i i i个字符, L L L是字符数。具体来说, X i n X_{in} Xin被转换为固定的字符序列 X ˉ i n \bar{X}_{in} Xˉin,然后映射到隐向量序列{ h k ∈ R d h_k\in R^d hk∈Rd}。给定输入序列 X ~ i n = [ C L S ] X i n [ S E P ] \tilde{X}_{in}=[CLS]X_{in}[SEP] X~in=[CLS]Xin[SEP],普通的微调方法在 [ C L S ] [CLS] [CLS]嵌入上利用一个通用的头层来预测输出类(例如,一个MLP层)。在本文中,我们遵循先前的提示调优研究Making Pre-trained Language Models Better Few-shot Learners,并使用特定于任务的模式字符串([Template] T)诱导模型产生与给定类(label token M(Y))相对应的文本输出。具体来说, X p r o m p t X_{prompt} Xprompt包含一个[MASK]字符,直接与语言模型输入任务如下:
X p r o m p t = [ C L S ] X i n [ S E P ] T [ S E P ] ( 1 ) X_{prompt}=[CLS]X_{in}[SEP]T[SEP] \qquad (1) Xprompt=[CLS]Xin[SEP]T[SEP](1)
当提示输入到语言模型时,模型可以得到候选类 y ∈ Y y\in Y y∈Y的概率分布 p ( [ M A S K ] ∣ X p r o m p t ) p([MASK]|X_{prompt}) p([MASK]∣Xprompt)为:
p ( y ∣ X p r o m p t ) = ∑ w ∈ V y p ( [ M A S K ] = w ∣ X p r o m p t ) ( 2 ) p(y|X_{prompt})=\sum_{w\in V_y}p([MASK]=w|X_{prompt}) \qquad (2) p(y∣Xprompt)=w∈Vy∑p([MASK]=w∣Xprompt)(2)
其中w表示类y的第w个标签字符。
本文将本体文本(从外部知识图中获取)作为注入知识的辅助提示,并将其附加到如图2所示的输入序列模板中。利用本体转换构造辅助提示,可以注入丰富的任务和实例相关知识。这些辅助提示在一定程度上类似于Making Pre-trained Language Models Better Few-shot Learners中的演示;然而,辅助提示并不是集中训练的实例,而是来自于外部知识。
4.2 本体转换
本文中,本体表示的表示为 O = { C , E , D } O=\{C,E,D\} O={C,E,D},C是一组概念,E是本体之间的连接边,D是每个本体的文本描述(本体模式包含一个段落的文本描述,而且它们具有词法有意义的信息的概念,它也可以通过使用属性的三元组表示,例如rdfs:comment。)这里的概念集是指特定于领域的概念。例如,在关系抽取和事件抽取中,我们利用与上述实体相关的类型本体。我们利用领域(即头部实体类型)和范围(即尾部实体类型)约束来完成知识图。
针对下游任务的差异,我们为每个任务利用不同的本体来源进行本体转换。我们首先从外部知识图中提取每个实例的本体,然后将这些本体(rdfs:comment)转换为原始文本作为辅助提示。
4.2.1 应用于关系抽取
我们利用MUC(Message Understanding Conference),它定义了命名实体的概念。注意,命名实体可以提供重要的类型信息,这有利于关系抽取。我们利用这些定义作为本体模式中的文本描述。具体来说,使用[CLS]
我们进一步在[MASK]的两侧添加可学习的标记作为虚拟标记,以便模型能够自动学习最适合提示符的单词。具体来说,我们使用几个未使用的字符[u1]-[u4](例如,词表中未使用的或特殊的字符)作为虚拟字符。
4.2.2 应用于事件抽取
我们遵循Zero-Shot Transfer Learning for Event Extraction的工作来构建事件抽取的本体。我们首先利用ACE事件模式作为基本事件本体。ACE2005语料库包含丰富的事件注释,目前可用于33种类型。然而,在现实场景中,可能有数千种类型的事件。为了便于在训练样本有限的情况下进行推理,我们将33个ACE事件类型和论元角色与FrameNet中的1161个帧整合在一起,构建了一个更大的事件本体用于事件提取。我们手动将选定的框架映射到事件本体。同样的,我们用[CLS]
与关系抽取类似,我们还利用可学习的虚拟令牌来增强提示表示。
4.2.3 应用于知识图谱补全
我们使用从外部Wikidata查询中获得的相应条目作为本体的来源,提取文本描述。继KG-BERT之后,我们将知识图谱补全视为一个三重分类任务,并将实体和关系连接为一个输入序列。
与上述任务类似,我们用[CLS]
我们还使用可学习的虚拟令牌来增强提示表示。在推理过程中,我们根据语言模型预测的句子的最大概率对输出分数进行排序,并计算黄金标准实体的命中次数,以评估该方法的性能。
4.3 文段感知的知识注入
图3
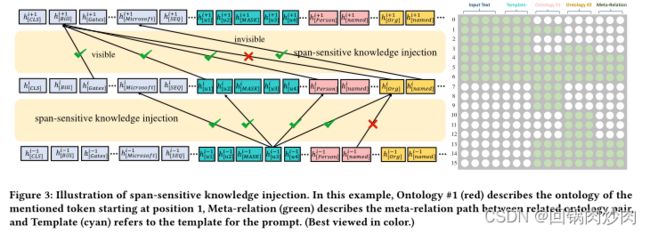
正如K-BERT: Enabling Language Representation with Knowledge Graph所观察到的,过多的知识注入可能会在原始文本中引入一些噪声,并导致性能下降。为了解决这个问题,我们提出了文段感知知识注入,如图3所示。给定有L个字符的输入序列 X i n = [ x 1 , x 2 , . . . , x L ] X_{in}=[x_1,x_2,...,x_L] Xin=[x1,x2,...,xL],我们使用可见矩阵来限制知识注入对输入文本的影响。在语言模型体系结构中,在softmax层之前添加带有自我注意权值的注意掩码矩阵。因此,我们对注意掩码矩阵M进行如下修改:

其中 x i x_i xi和 x j x_j xj分别是来自 x i n x_{in} xin和本体文本的字符, − ∞ -\infty −∞在注意掩码矩阵中阻止字符 i 注意到字符 j,0允许字符 i 注意到字符 j。在以下情况 x i x_i xi可以关注 x i x_i xi:两个字符都属于 x i n p u t x_input xinput,或者两个字符都属于同一本体的文本描述 x o x_o xo,或者是 x i x_i xi是实体在 x i n p u t x_{input} xinput中文段的位置的字符, x j x_j xj来自其本体表述文本 x o x^o xo。 p k p_k pk表示所提到的范围(例如,关系抽取中的实体和知识图谱补全、触发器或事件抽取中的参数)在输入文本中的位置。
4.4 集中训练
注意,那些从本体转换中注入的字符应该与输入序列相关联。因此,我们引入集体训练来优化本体字符和输入序列。首先,我们对本体字符进行实词嵌入初始化,并在固定语言模型的情况下对本体字符进行优化。然后对模型的所有参数进行优化,包括语言模型和本体字符。注意,我们的模型并不依赖于特定的模型体系结构;因此,它可以插入任何一种预先训练的语言模型,如BERT、BART。
5. 实验结果
关系抽取

事件抽取

知识图谱补全
