2022.10.30 第6次周报
目录
- 摘要
- 卷积神经网络学习
-
- 卷积
- 池化
- 完全连接层
- 小节
- 阅读文献
-
- 主要内容
- NLP神经结构
- Unified Attention 模型
- RNNsearch 的体系结构
- 注意力模型分类
- Self-Attention模型
- 存在的问题
- 总结
- 总结
摘要
在这周,我阅读了一篇Attention in Natural Language Processing论文,这篇论文发布于2021年,他提出了在自然语言处理中的注意力问题,比较输入数据和基于相似性或重要性度量的查询元素以及自动学习哪些数据被认为是相关的。同时继续学习卷积神经网络的数学原理,分析了卷积神经网络每一层的具体步骤与做法。
卷积神经网络学习
什么是卷积神经网络,为什么它重要?
卷积神经网络(也称作 ConvNets 或 CNN)是神经网络的一种,它在图像识别和分类等领域已被证明非常有效,目前在机器人和无人驾驶领域起到了很重要的作用,帮助车辆识别人、物体、交通标志等。 最近,卷积神经网络在一些自然语言处理任务(如语句分类)中也发挥了很大作用。下图为一个简单的卷积神经网络:
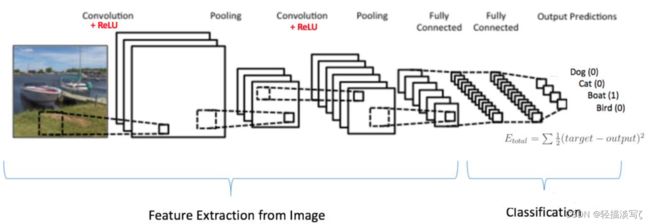
卷积
卷积的主要目的是从输入的图像中提取特征,那么一个图像,人很容易分辨出上面有什么,比如一只猫、一只狗等,而机器是如何识别的呢?
图片是一个由像素值组成的矩阵
实际上,每张图片都可以表示为一个 由像素组成的矩阵,如下图:
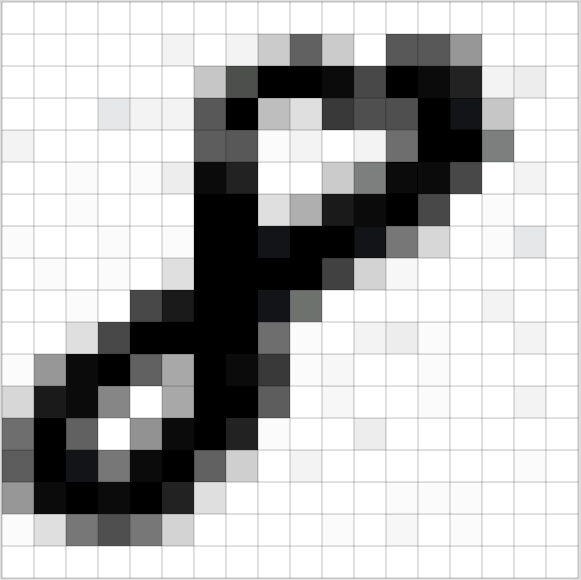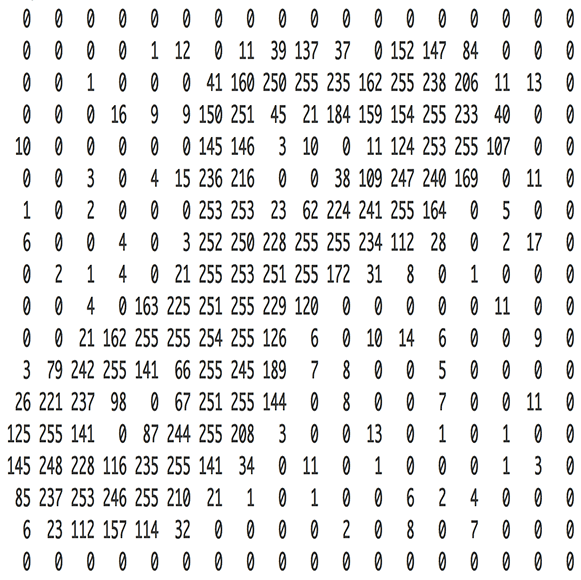

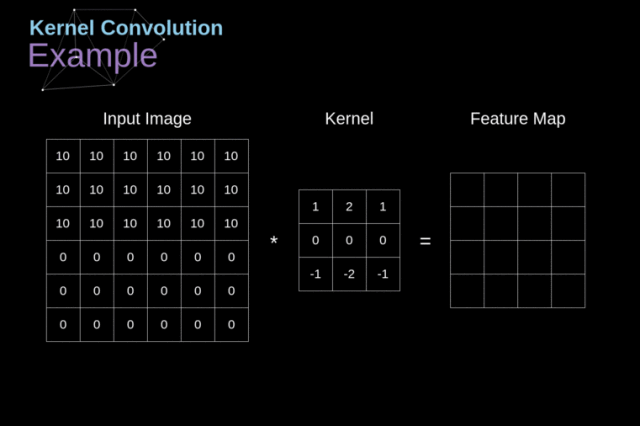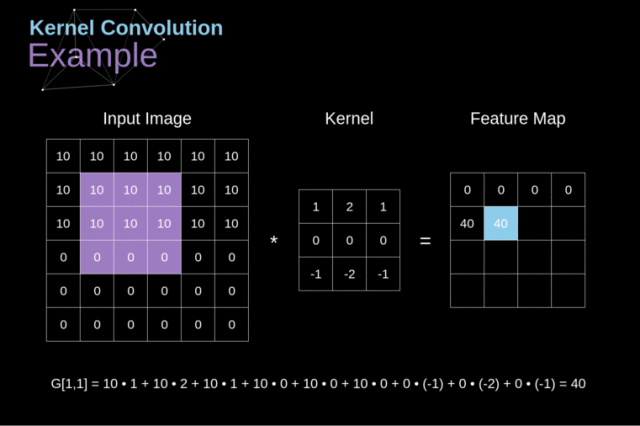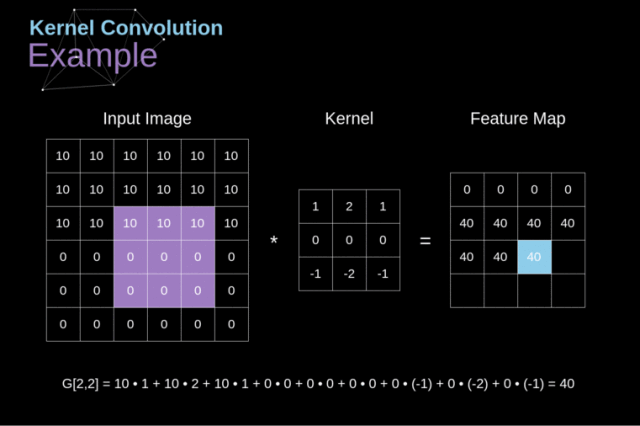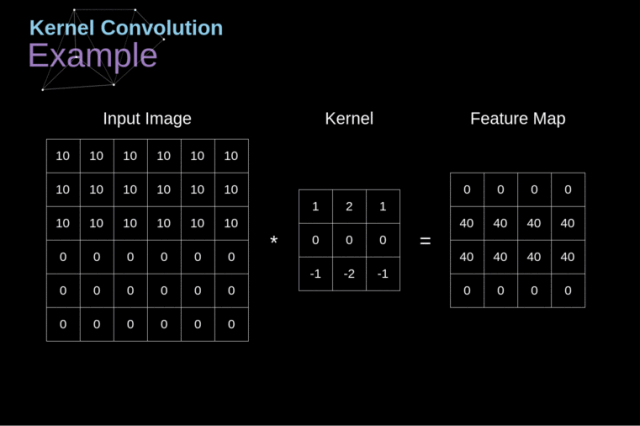

为什么需要非线性激活函数?为什么ReLU函数效果更好?

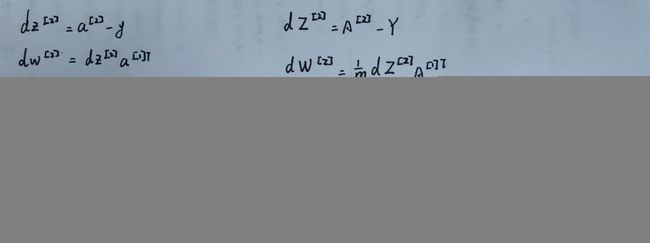

池化
空间池化(也称为子采样或下采样)可降低每个特征映射的维度,并保留最重要的信息。空间池化有几种不同的方式:最大值,平均值,求和等。
在最大池化的情况下,我们定义一个空间邻域(例如,一个2 × 2窗口),并取修正特征映射在该窗口内最大的元素。当然我们也可以取该窗口内所有元素的平均值(平均池化)或所有元素的总和。在实际运用中,最大池化的表现更好。
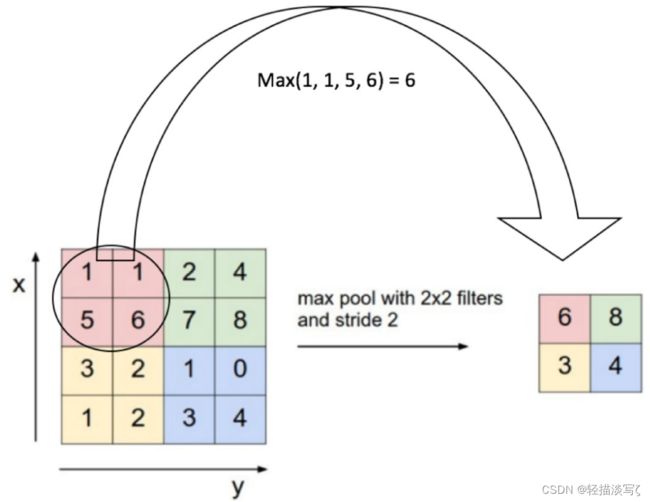
- 使输入(特征维度)更小,更易于管理
- 减少网络中的参数和运算次数,因此可以控制过拟合
- 使网络对输入图像微小的变换、失真和平移更加稳健(输入图片小幅度的失真不会改池化的输出结果 —— 因为我们取了邻域的最大值/平均值)
- 可以得到尺度几乎不变的图像(确切的术语是“等变”),这是非常有用的,这样无论图片中的物体位于何处,我们都可以检测到
完全连接层
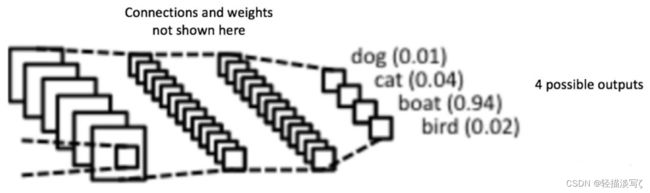
完全连接层是一个传统的多层感知器,它在输出层使用 softmax 激活函数(也可以使用其他分类器,比如 SVM等),“完全连接”这个术语意味着前一层中的每个神经元都连接到下一层的每个神经元,其目的是利用这些基于训练数据集得到的特征,将输入图像分为不同的类。如下图,我们要执行的图像分类任务有四个可能的输出:
小节
卷积网络的整体训练过程概括如下:
- 步骤1:用随机值初始化所有过滤器和参数/权重
- 步骤2:神经网络将训练图像作为输入,经过前向传播步骤(卷积,ReLU 和池化操作以在完全连接层中的前向传播),得到每个类的输出概率。
- 假设上面船只图像(第一张图)的输出概率是 [0.2,0.4,0.1,0.3]
- 由于权重是随机分配给第一个训练样本,因此输出概率也是随机的。
- 步骤3:计算输出层的总误差(对所有4个类进行求和)
- 总误差=∑ ½(目标概率 – 输出概率)²
- 步骤4:使用反向传播计算网络中所有权重的误差梯度,并使用梯度下降更新所有过滤器值/权重和参数值,以最小化输出误差。
- 根据权重对总误差的贡献对其进行调整。
- 当再次输入相同的图像时,输出概率可能就变成了 [0.1,0.1,0.7,0.1],这更接近目标向量 [0,0,1,0]。
这意味着网络已经学会了如何通过调整其权重/过滤器并减少输出误差的方式对特定图像进行正确分类。 - 过滤器数量、大小,网络结构等参数在步骤1之前都已经固定,并且在训练过程中不会改变 —— 只会更新滤器矩阵和连接权值。
- 步骤5:对训练集中的所有图像重复步骤2-4。
阅读文献
论文:Attention in Natural Language Processing
地址:https://ieeexplore.ieee.org/abstract/document/9194070
主要内容
本文定义了一个自然语言处理中注意力结构的统一模型,重点讨论了那些设计用于处理文本数据的向量表示的模型。根据四个维度提出了注意模型的分类: 输入的表征、相容函数、分布函数以及输入和/或输出的多样性。文章提出了如何在注意力模型中利用先验信息的例子,并讨论了正在进行的研究工作和该领域的公开挑战,提供了这个领域中的大量文献的第一个广泛的分类。
NLP神经结构
注意力已经成为 NLP 神经结构中越来越普遍的组成部分。下表为一个神经结构的非穷尽列表,其中引入注意机制已经带来了显著的收益。作品按照它们所处理的 NLP 任务进行分组。涉及的任务范围非常广泛。除了 NLP 和计算机视觉 ,注意力模型已经成功地应用于许多其他不同的领域,如speech recognition,recommendation,time-series analysis,games以及 mathematical problems。

Unified Attention 模型
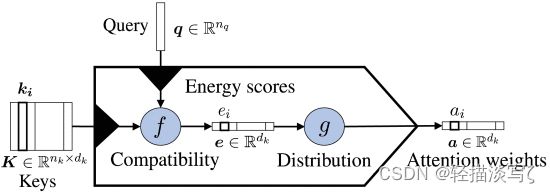
上图显示了核心注意力模型,它是下图一般模型的一部分。注意力机制的核心是将dk向量ki的序列K,即键,映射到dk权重ai的分布a。K编码数据特征,并在此基础上计算出注意力。例如,K可能是一个文件的单词或字符嵌入,或者是一个循环架构的内部状态,就像RNNsearch中的注释hi那样。在某些情况下,K可以包括同一对象的多个特征或表征(例如,一个词的单次编码和嵌入),甚至–如果任务需要–整个文档的表征。
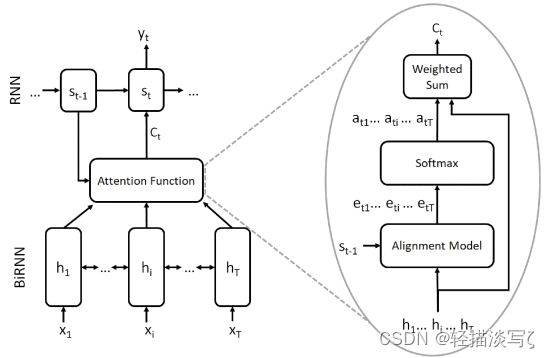
RNNsearch 的体系结构
RNNsearch 利用注意力进行机器翻译。这是一个输入序列的翻译X,目的是计算一个输出序列 y,该结构由一个编码器和一个解码器组成,如图所示。
注意力模型分类
注意力模型可以基于以下正交维度来描述: 输入的性质、兼容性函数、分布函数以及不同输入/输出的数量,称之为“多样性”。此外,注意力模块本身可以用在更大的注意力模型中,以获得复杂的结构,如分层输入模型或一些多输入共注模型。
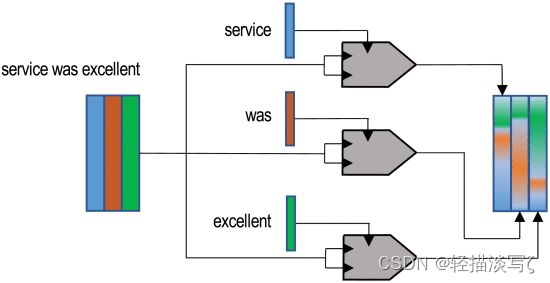
Self-Attention模型
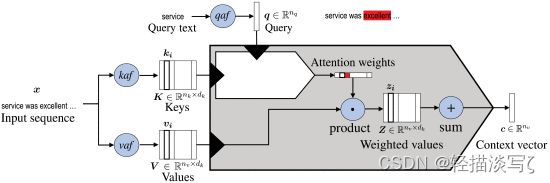
由K和V代表的输入序列和由q代表的查询。然而,有些架构只根据输入序列来计算注意力。这些架构被称为自我注意或内部注意模型。然而,这些术语被用来表示许多不同的方法。最常见的方法是对一个向量K应用多个步骤的注意力,在每个步骤中使用同一向量的元素kt作为查询。在每个步骤中,权重 ati 代表 ki 与 kt 的相关性,产生 dK 个单独的语境嵌入,ct,每个键。因此,Attention可以作为一个序列到序列的模型,作为CNN或RNN的替代品,如下图:
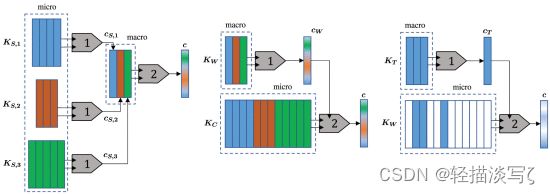
在一些任务中,输入数据的部分可以有意义地组合成更高层次的结构,在这些结构中,分层输入的注意力模型可以被利用,随后在不同层次的组成中应用多个注意力模块,如图下所示。
由于注意力可以创建元素的上下文表示,所以也可以用来构建序列到序列的注释器,而不需要依赖于 RNN 或卷积神经网络(CNN) ,如 Vaswani 等所建议的,他们依赖于注意力机制来获得整个编码器/解码器架构。
存在的问题
注意力是否可以被认为是解释神经网络的一种手段,目前还是一个公开的争论。最近的一些研究表明,注意力不能被认为是解释甚至解释神经网络的可靠手段。具体而言,Jain 和 Wallace 证明了注意力与其他可解释性指标不一致,并且很容易创建局部对抗性分布(与受训模型相似但产生不同结果的分布)。Wiegreffe 和 Pinter进一步推动了讨论,提供的实验表明,创建一个有效的全球对抗性注意力模型比创建一个局部模型困难得多,并且注意力权重可能包含关于特征重要性的信息。他们的结论是,注意力可能确实提供了一个模型的解释,如果通过解释,我们指的是一个合理的,但不一定忠实的决策过程的重建,如 Rudin 和 Riedl所建议的。
总结
注意力模型在自然语言处理应用中已经普遍存在。注意力可以应用于不同的输入部分,不同的表示相同的数据,或不同的特点,以获得一个紧凑的表示数据,以及突出有关的信息。选择是通过分布函数执行的,分布函数可以考虑不同维度中的局部性,例如空间、时间,甚至语义。注意力可以用来比较输入数据和基于相似性或重要性度量的查询元素。它还可以通过创建一个重要数据应该类似的表示编码,自动学习哪些数据被认为是相关的。在神经结构中集成注意力可能因此产生显著的性能增益。此外,注意力还可以作为研究网络行为的工具。
总结
本周学习了卷积神经网络的一些数学原理,了解了卷积神经网络每一层的具体做法,在学习过程中,我发现对很多概念还是比较模糊,希望通过继续学习让自己有一个提升。