YOLOv5配置问题总结(含大量避坑指南)
目录
前言
问题1-YOLOv5运行环境——pycocotools >= 2.0 安装失败
问题2-自制数据集训练精度非常低
问题3-AttributeError: Cant get attribute SPPF on module models.common
问题4-[WinError 1455] 页面文件太小,无法完成操作
问题5-AssertionError: Image Not Found D:\PycharmProjects\yolov5-hat\VOCdevkit\images\train\000000
问题6-AttributeError: ‘Upsample‘ object has no attribute ‘recompute_scale_factor‘
问题7-可以看到虽然有结果图片,但是并没有框出识别结果
问题8-打开摄像头检测报错
后记
前言
YOLO系列是深度学习目标检测的顶尖之作,尤其是目前的v5版本,对于各类物体的识别都能达到非常高的检测效果。YOLOv5保持开源特性,大家只需要标注好自己的数据集就可以进行训练了,本人使用YOLOv5的5.0版本(对,v5还有各类版本,套娃)GitHub - ultralytics/yolov5 at v5.0训练出一个人脸识别系统。整个流程还是充满崎岖的,现将遇到过的各类bug或者问题做一个大总结,如果你也遇到以下问题不妨按照我的方法一试。
问题1-YOLOv5运行环境——pycocotools >= 2.0 安装失败
一般将YOLOv5版本下载下来都需要安装环境库,直接在终端执行以下代码:
pip install -r requirements.txt但是会发现pycocotools这个包安装失败,出现一堆红色错误提示的情况。
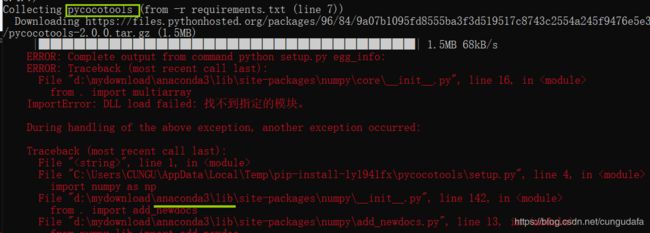
原因
出现这种情况原因很简单,就是windows平台不再维护pycocotools库。
解决方案
网上有很多解决方案,比如换源下载:
pip3 install pycocotools -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn
还有git上的解决方案:
pip3 install git+https://github.com/philferriere/cocoapi.git#egg=pycocotools^&subdirectory=PythonAPI
但我这两种都失败了,还有一些下载vs2015工具和替换pycocotools文件的思路,太麻烦懒得试了,最终在conda终端执行以下代码安装成功:
conda install -c esri pycocotools问题2-自制数据集训练精度非常低
利用labelimg手动标注了几百张图片,训练起来的精度却非常低,如下图:

原因和解决方案
数据集还是太少了,这种情况需要找大数据集,建议找有几万张图片的数据集训练。训练的时候注意看精度有没有在上升,一般都会逐渐上升才有效果。
问题3-AttributeError: Cant get attribute SPPF on module models.common
执行train.py出现的报错,根据提示肯定是在models的common.py中出现的问题。
原因
YOLOv6更新了common.py中的SPPF类而v5版本中没有,这个原因我也很迷惑,为啥跟v6有关系呢?
解决方案
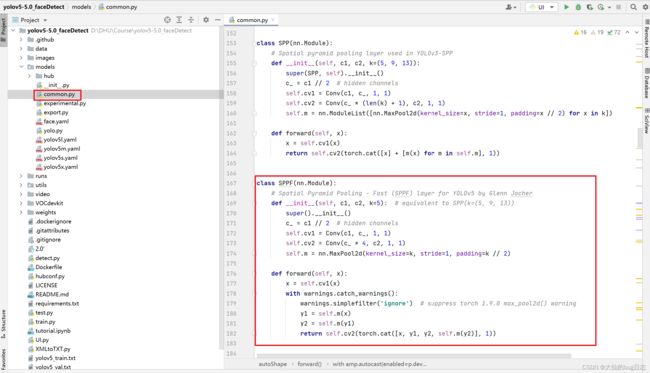
如原因所示,直接从v6版本中找到SPPF类加入到common.py中,你可以直接将以下代码复制到common中:
import warnings
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))如下图所示,我这里warnings这个库放到最上面了:
问题4-[WinError 1455] 页面文件太小,无法完成操作
![]()
原因
虚拟内存不足。
解决方案
在utils文件下的datasets的第81行,将num_workers=nw改为=0即可:

问题5-AssertionError: Image Not Found D:\PycharmProjects\yolov5-hat\VOCdevkit\images\train\000000
原因
如果你是下载别人的数据集进行训练的话,在其他路径配置无误的情况下报这种错说明train.py读取数据集的时候读取之前的缓存文件了。
解决方案
删除数据集文件夹labels下的两个缓存文件,重新训练即可。

问题6-AttributeError: ‘Upsample‘ object has no attribute ‘recompute_scale_factor‘

原因
torch的版本过高导致不兼容。
解决方案
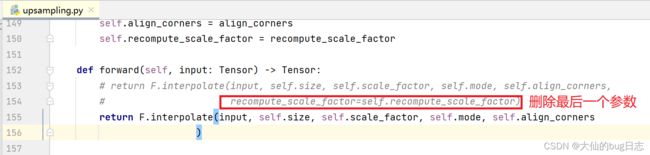
从上面点进~\torch\nn\modules\upsampling.py将forword中的return函数里的最后一个参数删除。
问题7-可以看到虽然有结果图片,但是并没有框出识别结果
训练图片的结果正常放在以下文件中,但是打开发现没有想像中给我们画出识别框。
原因
detect.py检测代码未设置画框。
解决方案
在detect.py的53行左右加上cudnn.benchmark = True,我这里因为自己加了注释到58行了。
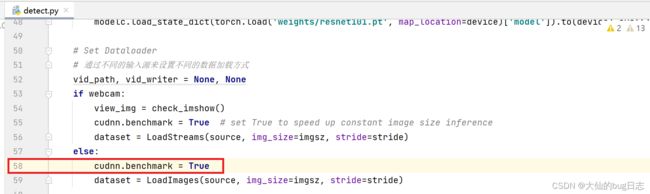
实际逻辑就是webcam代表batchsize>=1的情况,只有一张图detect的话默认不画框,加上后inference效果如下:
问题8-打开摄像头检测报错
YOLOv5非常人性化,正常检测我们都是直接修改detect.py中的source参数:

但是我们改成default='0'执行代码会遇到如下报错:

原因
数值转换错误,可能是源码的bug。
解决方案
打开utils文件的datasets.py,在第279行代码,将url格式转换为str即可。

后记
这次的人脸识别系统虽然是基于一次课程作业,但总算是将一直以来研究的深度学习框架做了一次实践。本系统我也写了一个UI界面,更方便操作,另外在这挖个坑,后面如果有时间会出人脸识别系统的整体配置流程,可以作为大作业甚至毕设。希望能够更加详细,搞懂流程就可以检测任意图片(检测猫狗、行人车辆等等。。。)。希望这篇文章对你有帮助。
参考
(25条消息) 目标检测---教你利用yolov5训练自己的目标检测模型_炮哥带你学的博客-CSDN博客_yolov5训练自己的模型