对Pytorch及其衍生/相关框架常用数据处理API的个人向总结
写在前面
在长达一年的Pytorch学习、应用与实践中,对基础API的反复遗忘和查找已经成了我时间利用效率的瓶颈,特开此文用作纯个人向记录,按照规划:
1)本文将会同时按照两套大纲行文,一套根据API本身的特性,另一套根据编程的实际需求
2)本文将会长期更新,随本人阅历增长而逐步完善
3)遵循实用主义至上原则,不复制大段文档来充数,只讲在具体需求语境下怎样的代码能够完成特定功能,因此本文也将变得零散、杂乱而个人向,希望未来某天如果有人再怀着“这功能明明这么简单,怎么到处搜都搜不到”的心情点开这篇文章时,本文的内容能帮助到他。
目录
API特性说明
Pytorch
new_ones:
Tensor.new_ones(size, dtype=None, device=None, requires_grad=False) → Tensor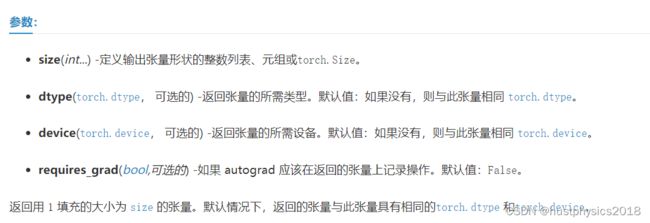
(图来自Python torch.Tensor.new_ones实例讲解 - 码农教程 (manongjc.com))
where:
按照限定条件进行判断,把一个tensor中不合适的用另一个tensor的值替换
torch.where()函数解读 - zae - 博客园 (cnblogs.com)
isnan:
输入一个Tensor,isnan可以判断Tensor的每个元素是不是nan,返回一个与输入同样size的Tensor,只包含True和False
import torch
res=torch.isnan(torch.tensor([1, float('inf'), 2, float('-inf'), float('nan')]))
print(res)
'''
输出:
tensor([False, False, False, False, True])
'''DataFrame
isnull:
该方法用于判断dataframe是否存在缺失值,返回一个由True和False构成的dataframe,若原数据为NaN,返回True,否则返回False。
any:
DataFrame.any(self, axis=0, bool_only=None, skipna=True, level=None, **kwargs)作用是:对dataframe中的每一行或者每一列,如果该行/列中存在一个True则返回True,skipna如果设置为False则nan也会被当做True看待。
axis:轴方向,默认为0,bool_only:是否只利用序列中的Boolean值进行判断,skipna:是否跳过NA/null值,return一个series或DataFrame,用例(来自pandas.DataFrame.any()与all()_斯特兰奇的博客-CSDN博客,后文也有引用):
>>>pd.Series([False, False]).any()
False
>>>pd.Series([True, False]).any()
True
>>>pd.Series([]).any()
False
>>>pd.Series([np.nan]).any()
False
>>>pd.Series([np.nan]).any(skipna=False)
Trueall:
和any差不多,区别就是如果所有的都是True才会返回True
sum:
DataFrame.sum(axis=None, skipna=None, level=None, numeric_only=None, min_count=0, **kwargs)sum用来统计dataframe中每一行或者一列的总和(bool型似乎会被当做0/1,如果和数字等混合存在会发生什么我也不知道),返回值是一个series类型。axis:行(0)/列(1),skipna :在计算结果时排除NA/null值,level : 如果坐标axis是一个多行的(分层的),则沿着一个特定的层计数,折叠成一个series,numeric_only :只包括float、int、boolean列,如果没有,将尝试使用所有数据(上面两个参数的作用我没太看懂),min_count :执行该操作所需的有效值的数量,如果行/列存在少于min_count个非NA值,结果将是NA。
value_counts:
该函数的输入值必须是Series类型,返回值也是Series类型,请注意不要直接应用于DataFrame,它会给出Series中每个值出现了多少次,用例(来自value_counts()计数的用法_缘 源 园的博客-CSDN博客_value_counts)
value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
'''
normalize : boolean, default False 默认false,如为true,则以百分比的形式显示
sort : boolean, default True 默认为true,会对结果进行排序
ascending : boolean, default False 默认降序排序
bins : integer, 格式(bins=1),意义不是执行计算,而是把它们分成半开放的数据集合,只适用于数字数据
dropna : boolean, default True 默认删除na值
'''fillna:
pandas中使用fillna函数填充NaN值 - 知乎 (zhihu.com)
drop:
DataFrame.drop(labels=None,axis=0,index=None,columns=None,level=None,inplace=False,errors='raise')
(上图来自pandas 操作 dataframe 使用 drop() 函数删除一行或一列 - 链滴 (ld246.com))
也就是说要么用index或者columns直接指定删除行列的名称,要么用labels搭配axis指定。
实际应用
在dataframe中统计多少个列有nan,多少个列没有?
如下:一共有28个列存在nan值
train_data.isnull().any().value_counts()
#out:
'''
True 28
False 3
dtype: int64
'''从dataframe中取出连续/不连续的多行/列/行列?
这一篇基本解决大多数场景下的需求:需要注意取出不连续的行和列时要用列表括起来,连续的行和列则可以写成切片形式,不需要加中括号。python_DataFrame的loc和iloc取数据 基本方法总结_侯小啾的博客-CSDN博客_dataframe loc
view和shape改变Tensor维度是一样的么?
由于Pytorch内部机制的问题,Tensor在内存/显存中并不一定都是连续存储的。reshape()在内部数据存储不连续时会先进行contiguous()产生一个连续存储的副本Tensor,然后再调用view()改变这个Tensor的shape,如果内部数据是连续的,则会直接调用view(),换句话说,reshape已经包括了view的功能,建议无脑使用reshape就好了。
PyTorch 82. view() 与 reshape() 区别详解 - 知乎 (zhihu.com)
将一个tensor中所有的nan值替换掉?
tmptarg = torch.where(torch.isnan(tmptarg), inp, tmptarg)如何给Tensor增加一个维度?(长期更新问题)
使用expand_dims()函数可以轻松的在Tensor的各个维度添加一维,当然最常用的还是在最前面或者最后面加一个维度,让HxW格式的图片变成CxHxW或者HxWxC格式了。
images[i] = np.expand_dims(images[i], 0)如何为numpy类型的数组更换数据类型?(长期更新问题)
使用astype()函数可以更换数据类型,甚至支持string向int的转换。
【函数学习】numpy.astype() - 简书 (jianshu.com)