Tesseract-OCR+Python+pytesseract实现图片转文字
背景
最近朋友在网上做数据爬取的时候遇到一个反爬虫技术,某网站将部分文字转化为表情图片进行展示,我们通过html无法爬取到完整的文字内容,取而代之的是一些特殊的空字符,让人很是郁闷。后面我想到了能不能通过OCR(Optical Character Recognition)技术来破解这个问题。网上查了一些资料发现这个的确是简单可行的,话不多说,我给大家一步一步演示如何使用OCR完成图片转文字
安装Tesseract-OCR
运行以下两条命令在linux(Red Hat)安装Tesseract-OCR,其他操作系统安装命令请参考https://github.com/tesseract-ocr/tesseract/wiki
yum install tesseract
yum install tesseract-langpack-deu
Tesseract安装完成后运行 tesseract -v 将显示版本信息,意味着安装成功
![]()
Tesseract命令实现图片转文字
我们先准备一个用于带有文字的图片,比如就截取这篇文章的标题
![]()
在图片保存的文件目录中,执行如下命令
tesseract ocr_test.png result
cat result

我们这儿看到大部分英文都正确识别到了,但是中文完全没有识别到,这是因为我们没有指定中文数据包,我们可以在这个地址中下载中文数据包chi_sim.traineddata, https://github.com/tesseract-ocr/tesseract/wiki/Data-Files (需要根据你安装的tesseract版本下载对应的数据文件)
然后,将下载的包放在指定目录下,如果你不知道在linux中应该放在哪个目录,你可以在根目录下通过find命令去查找,具体如下图所示:
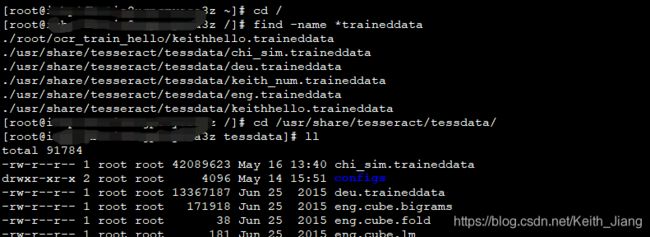
现在,我们可以通过中文数据包去对图片中的中文进行识别了,通过-l 去指定语音,命令如下
tesseract ocr_test.png result -l chi_sim

这儿我们看到部分中文已经能够准确识别了,但是“学”和“T”这两个字还是识别错了,那么我们怎么能够针对这个图片提高它的识别正确率呢?这儿我们可以用jTessBoxEditor对数据进行校正并提供给tesseract进行校正训练,也就是告诉程序长“T”这个样子的是“T”而不是“丁”。
安装jTessBoxEditor并进行数据校正训练
我们可以通过以下网址下载jTessBoxEditor,因为我们要处理中文,我们必须下载jTessBoxEditorFX,https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
1.将图片转化为tif格式
打开jTessBoxEditorFX(Windows下运行train.bat),Tools>Merge TIFF…,选择我们之前的图标并按特定文件名命名规则保存。命名规则为
[lang].[fontname].exp[num].tif
比对我们这儿命名为chi_test.keithfont.exp0.tif
2.生成box文件
使用tesseract命令生产box文件
tesseract chitest.keithfont.exp0.tif chitest.keithfont.exp0 -l chi_sim batch.nochop makebox

在jTessBoxEditor中对识别错误的进行校正编辑,Box Editor>Open,需保证tif文件和box文件在同一目录下。对识别错误的进行修改(包括修改字符以及调整图片中对应的位置,两个字符识别成了一个字符的,需要拆分再修改)
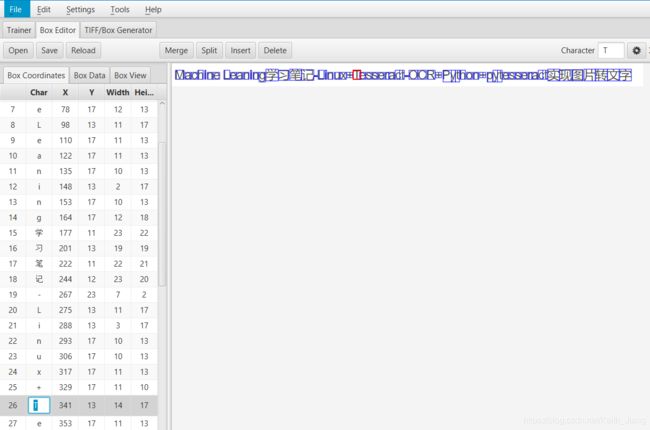
3.校正训练
执行以下命令完成校正训练
tesseract chitest.keithfont.exp0.tif chitest.keithfont.exp0 nobatch box.train
unicharset_extractor chitest.keithfont.exp0.box
echo keithfont 0 0 0 0 0> font_properties
shapeclustering -F font_properties -U unicharset chitest.keithfont.exp0.tr
mftraining -F font_properties -U unicharset -O unicharset chitest.keithfont.exp0.tr
cntraining chitest.keithfont.exp0.tr
mv unicharset keithfont.unicharset
mv inttemp keithfont.inttemp
mv normproto keithfont.normproto
mv pffmtable keithfont.pffmtable
mv shapetable keithfont.shapetable
combine_tessdata keithfont.
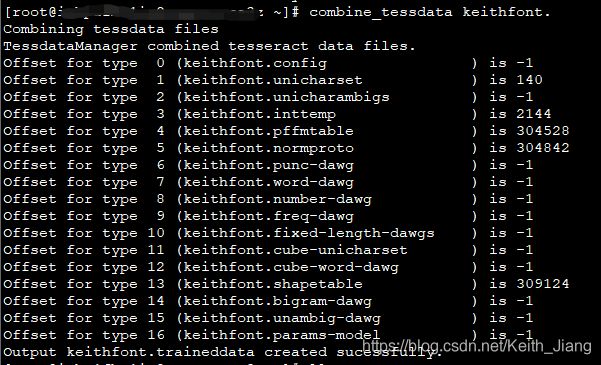
最后成功生成一个keithfont.traineddata,将这个文件放到之前chi_sim.traineddata所放的目录
cp keithfont.traineddata /usr/share/tesseract/tessdata/keithfont.traineddata
现在我们就可以通过训练出来的keithfont数据包来对图片进行再次识别
tesseract ocr_test.png result -l keithfont

这次虽然“学”,“T”这几个字都识别正确了,然而“图”字却识别错了。? 后面我再尝试了基于keithfont再次修正训练,依然无法达到完全识别正确,这儿也就暂时不纠结了~待以后有了新的方法提高识别准确率再与大家分享…
通过命令行可以进行图片转文字,那么使用Python可以实现吗?当然可以
在Python中实现图片转文字
首先,需要使用pip安装Python包pytesseract
pip3 install pytesseract
Python代码中引用pytesseract包实现OCR
#coding = utf -8
from PIL import Image
import pytesseract
im = Image.open("ocr_test.png")
text = pytesseract.image_to_string((im), lang='keithfont')
print (text)
执行Python脚本结果如下:
![]()
这次测试虽然没有将OCR识别准确率调至很高,但是使用tesseract对单个文字的图片进行识别用于破解文章开始提到的反爬虫技术还是绰绰有余的,如果之后我有OCR相关的新发现将继续与大家分享…Good Day ?
参考资料:
https://blog.csdn.net/qq_38844326/article/details/78143180
https://blog.csdn.net/yasi_xi/article/details/8763385