手写算法-python代码实现自定义的KNN
手写算法-python代码实现自定义的KNN
- 普通KNN存在的问题
- 自定义权重
- python代码实现
- sklearn的KNN库对比
- sklearn里面的KNN自定义权重
普通KNN存在的问题
上篇文章,我们梳理了一下KNN,其中谈到一个问题:
链接: 手写算法-python代码实现KNN
做分类任务时,K个近邻数据,到样本的距离都不一样,但是我们都一视同仁,统计最大样本数对应的y标签,作为预测标签,这样明显不太合理,例如:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.metrics import classification_report
x0 = np.array([[1,2],
[2,3],
[3,4],
[3,3],
[2,4]])
y0 = np.array([0,0,0,0,0])
x1 = np.array([[10,14],
[10,12]])
y1 = np.array([1,1])
plt.scatter(x0[:,0],x0[:,1],c='r')
plt.scatter(x1[:,0],x1[:,1],c='b')
plt.scatter(9,13,marker='*',s =200,c='k')
plt.legend(labels=['label0','label1'],loc='best')
plt.show()

如图所示的样本集,五角星作为一个待预测的样本点,当k=5时,该样本点的预测标签就是0,明显的,此时把该样本点预测为1更加合理。
自定义权重
造成上面的原因是:我们不加区别的对待这k个近邻数据,只统计这些数据属于哪个标签,但是实际上,我们应该增加权重的概念,距离待预测样本点更近的数据,应该获得更大的权重,更远的数据应该获得更小的权重,这样就合理一些。
方案一:weight = 1 / distance ,权重等于距离的倒数,符合我们自定义权重的要求,但是,这个方案存在的问题是,
权重的取值区间在(0,+∞),距离待预测样本点最近的一个数据,权重过大,极端情况下,比如距离非常近的时候,该样本点对应的标签,就是预测标签,这样对噪声数据很敏感,容易造成过拟合;
方案二:weight = 1 / (distance+const),把方案一的图像,往左平移const个单位,这样的话,权重的取值区间在(0,1/const),较为平缓,既达到了增加权重的目的,也不会很容易过拟合,const的值可以根据实际业务来确定;

(还有其他方法,比如引入高斯函数,sigmoid函数,具体的还要看实际场景)
我们暂定使用方案二。
python代码实现
根据上面所分析的,我们优化python代码如下:
#自定义权重
class Knn_weight():
#默认k=5,设置和sklearn中的一样,weight = False
def __init__(self,k=5,weight = False):
self.k = k
self.weight = weight
def fit(self,x,y):
self.x = x
self.y = y
def predict(self,x_test):
labels = []
#这里可以看出,KNN的计算复杂度很高,一个样本就是O(m * n)
for i in range(len(x_test)):
#初始化一个y标签的统计字典
dict_y = {}
#计算第i个测试数据到所有训练样本的欧氏距离
diff = self.x - x_test[i]
distances = np.sqrt(np.square(diff).sum(axis=1))
#对距离排名,取最小的k个样本对应的y标签
rank = np.argsort(distances)
rank_k = rank[:self.k]
y_labels = self.y[rank_k]
#增加权重时
if self.weight:
distances_k = distances[rank_k]
#自定义权重表达式
weight = 1 / (distances_k + 0.5)
#累加权重,作为最终标签的值
for j in y_labels:
if j not in dict_y:
dict_y.setdefault(j,weight[j])
else:
dict_y[j] += weight[j]
else:
#生成类别字典,key为类别,value为样本个数
for j in y_labels:
if j not in dict_y:
dict_y.setdefault(j,1)
else:
dict_y[j] += 1
#取得y_labels里面,value值最大对应的类别标签即为测试样本的预测标签
#label = sorted(dict_y.items(),key = lambda x:x[1],reverse=True)[0][0]
#下面这种实现方式更加优雅
label = max(dict_y,key = dict_y.get)
labels.append(label)
return labels
针对上一篇文章的数据集,我们来对比一下,增加权重之后的分类效果如何。
print('距离没有权重时,分类报告和分类效果图如下:\n')
#预测
knn = Knn_weight(weight=False)
knn.fit(x,y)
labels = knn.predict(x)
#查看分类报告
print(classification_report(y,labels))
#画等高线图
x_min,x_max = x[:,0].min() - 1,x[:,0].max() + 1
y_min,y_max = x[:,1].min() - 1,x[:,1].max() + 1
xx = np.arange(x_min,x_max,0.02)
yy = np.arange(y_min,y_max,0.02)
xx,yy = np.meshgrid(xx,yy)
x_1 = np.c_[xx.ravel(),yy.ravel()]
y_1 = knn.predict(x_1)
#list没有reshape方法,转为np.array的格式
plt.contourf(xx,yy,np.array(y_1).reshape(xx.shape),cmap='GnBu')
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
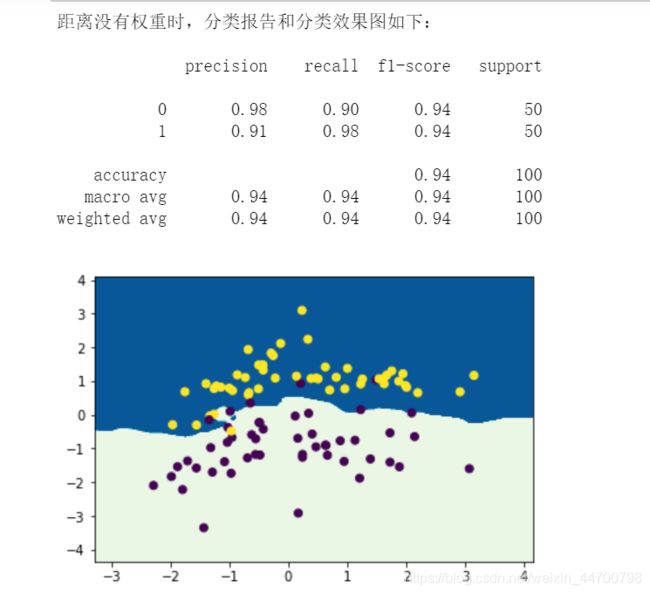
给距离增加权重时:
print('给距离增加权重时,分类报告和分类效果图如下:\n')
#预测
knn = Knn_weight(weight=True)
knn.fit(x,y)
labels = knn.predict(x)
#查看分类报告
print(classification_report(y,labels))
y_1_weight = knn.predict(x_1)
#list没有reshape方法,转为np.array的格式
plt.contourf(xx,yy,np.array(y_1_weight).reshape(xx.shape),cmap='GnBu')
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()

精准率、召回率、F1的值均有提升,从图像里面看,有2个点,之前预测错了,但是现在预测对了,还是有一定的效果。
sklearn的KNN库对比
from sklearn.neighbors import KNeighborsClassifier
#默认是weights='uniform',weights='distance'表示增加权重
clf = KNeighborsClassifier(weights='distance')
clf.fit(x,y)
y_pred = clf.predict(x)
#查看分类报告
print(classification_report(y,y_pred))
y_1_sklearn = clf.predict(x_1)
plt.contourf(xx,yy,y_1_sklearn.reshape(xx.shape),cmap='GnBu')
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
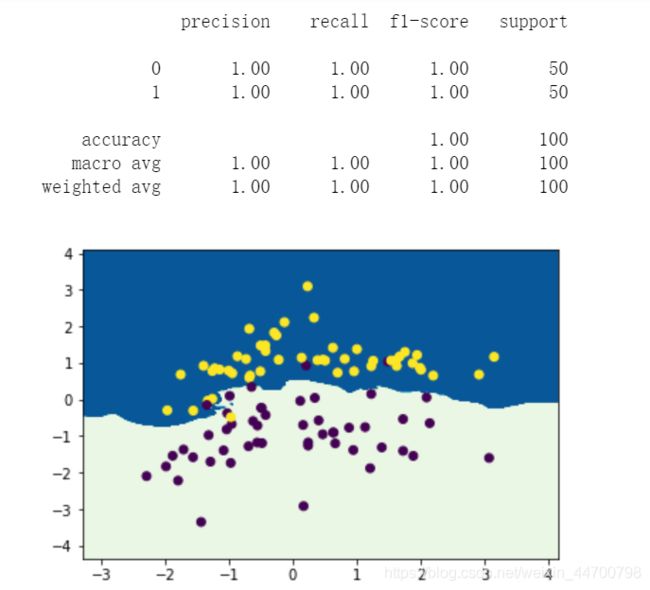
百分之百的准确率!!
sklearn里面的KNN自定义权重
官网是这么介绍的:

weight = 'distance’为官方给的一个权重,权重=距离的倒数,
我们自己自定义函数的话,函数接受一个距离的array,返回一个自定义权重的array。
下面展示一下,官方KNN里面,如何自定义权重函数:
#自定义函数1,模拟weights = 'distance'
def udf1(x):
return 1/(x+0.001)
clf = KNeighborsClassifier(n_neighbors=5,weights=udf1)
clf.fit(x,y)
y_pred = clf.predict(x)
#查看分类报告
print(classification_report(y,y_pred))
y_1_sklearn = clf.predict(x_1)
plt.contourf(xx,yy,y_1_sklearn.reshape(xx.shape),cmap='GnBu')
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
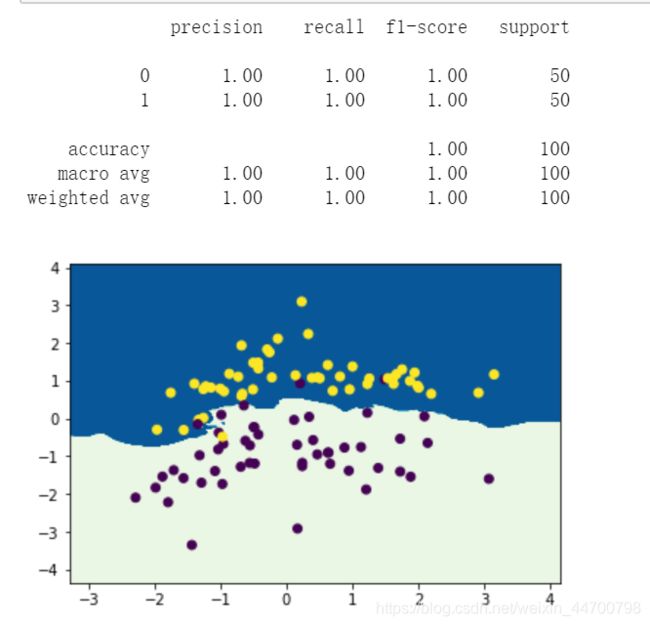
也是百分之百准确率。
#自定义函数2
def udf2(x):
return 1/(x+0.5)
clf = KNeighborsClassifier(n_neighbors=5,weights=udf2)
clf.fit(x,y)
y_pred = clf.predict(x)
#查看分类报告
print(classification_report(y,y_pred))
y_1_sklearn = clf.predict(x_1)
plt.contourf(xx,yy,y_1_sklearn.reshape(xx.shape),cmap='GnBu')
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()

KNN的自定义权重函数相对于xgboost、lightgbm而言,比较简单,udf函数的表现形式,要根据实际业务来编写,先要弄清楚输入是什么,输出是什么。