python实现KNN算法(公式推导+源代码)
今天这篇文章要介绍的是KNN(k近邻算法),这是一种简单的分类算法,它的思想是通过测量不同特征值之间的距离进行分类的。
这样说你可能不太懂,那下面我们就通过一个简单的例子来形象的概述下。
以下面这张图为例,我们在这张图上可以看到有三种不同类别的形状(正方形、圆形、三角形),其中他们的分布也是比较不集中的。

假设我们在内圆里面要判断某个东西是属于哪一类别的话,我们该怎么做呢 ?
方法很简单,就是在内圆里面选择K个数据离我(图中 ?表示)最近的几个点,然后根据少数服从多数的原则,将多数的类别作为我预测的类别。
比如我们取k=4,那么三角形有2个,正方形1个,圆1个,他们的占比分别为 1/2、1/4、1/4
所以我们将三角形作为我们这个输入数据(相当于 ?)的预测类别。
至此,我相信你大概明白了KNN的意思。
我们在KNN中,使用最多的就是欧式距离来计算各个点之间的距离,如下所示:

好了,了解上面的基本知识之后,接下来就是我们来阐述下KNN算法:
1.计算测试数据与训练数据之间的距离
2.按照距离的从小到大的关系进行排序
3.选取距离最小的k个点
4.统计前k个点所在类别的出现频率
5.返回前k个点中 出现频率最高的类别作为测试数据的预测分类。
下面我们通过网上一个实战案例:优化约会网站的配对效果,为例通过自己的理解以及代码的部分改动来深入了解KNN算法。
1.准备数据集
点击这里下载:数据集

大致的格式如上所示,有三个特征值以及一种标签类。
其中第一列代表的是:每年获得的飞行常客里程数
第二列代表的是:玩视频游戏所耗时间百分比
第三列代表的是:每周消费的冰淇淋公升数
第四列代表的是:1-不喜欢、2-有点喜欢、3-非常喜欢
通过输入前三个特征来预测约会的对象是否符合自己的口味。
2.首先读取文件数据
def loadData(filename):
"""
:param filename: 文件路径名
:return: dataMat:数据集 lableMat:标签集
"""
# 读取文件
fr = open(filename)
# 读取文件内容
getFile = fr.readlines()
# 获取文件行数
lines = len(getFile)
# 定义存放标签的列表
lableMat = []
# 定义一个空矩阵,存放特征值的列表
emptyMat = np.zeros((lines,3))
# 初始化索引
index = 0
# 通过迭代读取数据
for line in getFile:
# 将每一行的数据的空格或者换行符去掉
lineArr = line.strip().split()
# 逐行读取前三列数据
# dataMat.append(lineArr[:3]) # 这里不使用这个方法的目的是生成的是列表,后续我们需要使用的是矩阵,所以用下面那个方法,避免后续不必要的麻烦
emptyMat[index,:] = lineArr[:3]
# 读取每一行的标签值(lineArr[-1]代表的是每一行最后一个元素)
lableMat.append(int(lineArr[-1])) # 为什么要转为int,因为我们的linArr[-1]是str类型,这里不类型转换后续操作
# 索引值自增
index += 1
return emptyMat,lableMat3.我们图形化显示每年获得的飞行常客里程数与玩视频游戏所消耗时间占比
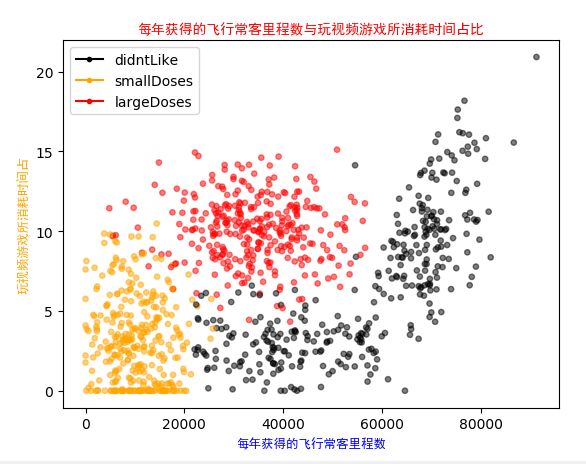
这是运行结果,代码如下所示:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from matplotlib.font_manager import FontProperties
def loadData(filename):
"""
:param filename: 文件路径名
:return: dataMat:数据集 lableMat:标签集
"""
# 读取文件
fr = open(filename)
# 读取文件内容
getFile = fr.readlines()
# 获取文件行数
lines = len(getFile)
# 定义存放标签的列表
lableMat = []
# 定义一个空矩阵,存放特征值的列表
emptyMat = np.zeros((lines,3))
# 初始化索引
index = 0
# 通过迭代读取数据
for line in getFile:
# 将每一行的数据的空格或者换行符去掉
lineArr = line.strip().split()
# 逐行读取前三列数据
#dataMat.append(lineArr[:3])
emptyMat[index,:] = lineArr[:3]
# 读取每一行的标签值(lineArr[-1]代表的是每一行最后一个元素)
lableMat.append(int(lineArr[-1])) # 为什么要转会出问题为int,因为我们的linArr[-1]是str类型,这里不类型转换后续操作
# 索引值自增
index += 1
return emptyMat,lableMat
def show(dataMat,lableMat):
"""
:param dataMat:
:param lableMat:
"""
# 设置汉字格式
font = FontProperties(fname=r"D:\python-workspace\SimHei.ttf", size=9)
# 设置颜色列表
LabelColros = []
# 给不同的标签添加上不同的颜色
for i in lableMat:
if i == 1:
LabelColros.append('black')
if i == 2:
LabelColros.append('orange')
if i == 3:
LabelColros.append('red')
# 画出散点图,以datas矩阵的第一(飞行常客例程)、第二列(玩游戏)数据画散点数据,散点大小为15,透明度为0.5
plt.scatter(dataMat[:,0].tolist(),dataMat[:,1].tolist(), color=LabelColros,s=15, alpha=.5)
# 设置标题
plt.title('每年获得的飞行常客里程数与玩视频游戏所消耗时间占比', FontProperties=font,color='r',size=10)
# 设置x轴
plt.xlabel('每年获得的飞行常客里程数', FontProperties=font,color='blue')
# 设置y轴
plt.ylabel('玩视频游戏所消耗时间占', FontProperties=font,color='orange')
# 设置图例
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
# 添加图例
plt.legend(handles=[didntLike, smallDoses, largeDoses])
# 显示
plt.show()
if __name__ == '__main__':
filepath = "data.txt"
data,label = loadData(filepath)
show(data,label)
4.接下来我们需要对我们的数据进行归一化处理(数据归一化和两种常用的归一化方法)
这里我谈下我个人的观点为什么要对数据进行归一化,因为我们可以看到我们的数据集第一列和其他2列数值之间的差值是挺大的,这就会导致我们在计算距离的时候会有很大的误差,这种误差就导致我们的分类效果不佳,所以我们为了统一数据进行归一化,让数据处在区间(0,1)中。
这里我们采用的是最值归一化,通过这种方法可以使数据取值在(0,1)之间,公式为:
其中x表示的是原始数据,min表示的是每一列最小值,max表示的是每一列最大值。
def dataNorm(dataSet):
"""
:param dataSet:
:return: diffs:最大最小之间的差值 normData:归一化的数据集
"""
# 获取数据集中每一列的最大值
maxValue = dataSet.max(0)
# print(maxValue)
# 获取数据集中每一列的最小值
minValue = dataSet.min(0)
# print(minValue)
# 最大值与最小值之间的差值
diffs = maxValue - minValue
# 获取dataSet行数
num = dataSet.shape[0] # num = 1000
# 定义一个和DataSet一样大小的矩阵
normData = np.zeros(dataSet.shape)
# 数据归一化(使数据属于(0,1)之间)
for i in range(num):
# 采用的是最值归一化:x = (x - min) / (max - min)
normData[i,: ] = (dataSet[i,:] - minValue) / diffs
return diffs,normData,minValue5.分别测试下数据归一化和没有归一化的误差
5.1 未对数据归一化
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from matplotlib.font_manager import FontProperties
def loadData(filename):
"""
:param filename: 文件路径名
:return: dataMat:数据集 lableMat:标签集
"""
# 读取文件
fr = open(filename)
# 读取文件内容
getFile = fr.readlines()
# 获取文件行数
lines = len(getFile)
# 定义存放标签的列表
lableMat = []
# 定义一个空矩阵,存放特征值的列表
emptyMat = np.zeros((lines,3))
# 初始化索引
index = 0
# 通过迭代读取数据
for line in getFile:
# 将每一行的数据的空格或者换行符去掉
lineArr = line.strip().split()
# 逐行读取前三列数据
#dataMat.append(lineArr[:3])
emptyMat[index,:] = lineArr[:3]
# 读取每一行的标签值(lineArr[-1]代表的是每一行最后一个元素)
lableMat.append(int(lineArr[-1])) # 为什么要转会出问题为int,因为我们的linArr[-1]是str类型,这里不类型转换后续操作
# 索引值自增
index += 1
return emptyMat,lableMat
def dataNorm(dataSet):
"""
:param dataSet:
:return: diffs:最大最小之间的差值 normData:归一化的数据集
"""
# 获取数据集中每一列的最大值
maxValue = dataSet.max(0)
# print(maxValue)
# 获取数据集中每一列的最小值
minValue = dataSet.min(0)
# print(minValue)
# 最大值与最小值之间的差值
diffs = maxValue - minValue
# 获取dataSet行数
num = dataSet.shape[0] # num = 1000
# 定义一个和DataSet一样大小的矩阵
normData = np.zeros(dataSet.shape)
# 数据归一化(使数据属于(0,1)之间)
for i in range(num):
# 采用的是最值归一化:x = (x - min) / (max - min)
normData[i,: ] = (dataSet[i,:] - minValue) / diffs
return diffs,normData,minValue
def classify(input,data,label,k):
"""
:param input: 输入数据
:param data: 原数据集
:param label: 标签集
:param k: 选取的点的个数
:return: classes:标签类别
"""
# 获取data行数
size = data.shape[0]
# 作差 (其中np.tile(input,(size,1))作用是将input重复一次形成size大小的矩阵)
diff = np.tile(input,(size,1)) - data
# 求平方
sqdiff = diff ** 2
# 求和
squreDiff = np.sum(sqdiff,axis=1)
# 开根号
dist = squreDiff ** 0.5
# 排序 (argsort()根据元素的值从小到大对元素进行排序,返回下标)
# 比如a = [1,5,9,2,3]对应的下标为[0,1,2,3,4] 排序之后[1,2,3,5,9] 返回的结果是[0,3,4,1,2]
sortDist = np.argsort(dist)
# 对前k个最小距离点进行统计
classCount = {}
for i in range(k):
voteLabel = label[sortDist[i]]
# 对选取的前k个最小点的类别进行统计
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
# 统计所选类别出现最多的
maxCount = 0
for key,value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes
def dataTest(filepath):
"""
函数说明:分类器测试函数
Parameters:filepath
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
"""
# 将返回的特征矩阵和分类向量分别存储到datingDataMat和datingLabels中
datingDataMat, datingLabels = loadData(filepath)
# 取所有数据的百分之十
hoRatio = 0.10
# 数据归一化,返回归一化后的矩阵,数据范围,数据最小值
#ranges,normMat, minVals = dataNorm(datingDataMat)
# 获得normMat的行数
rows = datingDataMat.shape[0]
# 百分之十的测试数据的个数
nums = int(hoRatio * rows)
# 分类错误概率
errorRate = 0
for i in range(nums):
# 前nums个数据作为测试集,后rows - nums个数据作为训练集
classifyResult = classify(datingDataMat[i,:],datingDataMat[nums:rows,:],datingLabels[nums:rows],3)
print("分类结果:%d\t真实类别:%d" % (classifyResult, datingLabels[i]))
if classifyResult != datingLabels[i]:
errorRate += 1
print("错误率:%f%%" % (errorRate / float(nums) * 100))
if __name__ == '__main__':
filepath = "data.txt"
data,label = loadData(filepath)
dataTest(filepath)
运行结果: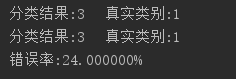
5.2 对数据进行归一化
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from matplotlib.font_manager import FontProperties
def loadData(filename):
"""
:param filename: 文件路径名
:return: dataMat:数据集 lableMat:标签集
"""
# 读取文件
fr = open(filename)
# 读取文件内容
getFile = fr.readlines()
# 获取文件行数
lines = len(getFile)
# 定义存放标签的列表
lableMat = []
# 定义一个空矩阵,存放特征值的列表
emptyMat = np.zeros((lines,3))
# 初始化索引
index = 0
# 通过迭代读取数据
for line in getFile:
# 将每一行的数据的空格或者换行符去掉
lineArr = line.strip().split()
# 逐行读取前三列数据
#dataMat.append(lineArr[:3])
emptyMat[index,:] = lineArr[:3]
# 读取每一行的标签值(lineArr[-1]代表的是每一行最后一个元素)
lableMat.append(int(lineArr[-1])) # 为什么要转会出问题为int,因为我们的linArr[-1]是str类型,这里不类型转换后续操作
# 索引值自增
index += 1
return emptyMat,lableMat
def dataNorm(dataSet):
"""
:param dataSet:
:return: diffs:最大最小之间的差值 normData:归一化的数据集
"""
# 获取数据集中每一列的最大值
maxValue = dataSet.max(0)
# print(maxValue)
# 获取数据集中每一列的最小值
minValue = dataSet.min(0)
# print(minValue)
# 最大值与最小值之间的差值
diffs = maxValue - minValue
# 获取dataSet行数
num = dataSet.shape[0] # num = 1000
# 定义一个和DataSet一样大小的矩阵
normData = np.zeros(dataSet.shape)
# 数据归一化(使数据属于(0,1)之间)
for i in range(num):
# 采用的是最值归一化:x = (x - min) / (max - min)
normData[i,: ] = (dataSet[i,:] - minValue) / diffs
return diffs,normData,minValue
def classify(input,data,label,k):
"""
:param input: 输入数据
:param data: 原数据集
:param label: 标签集
:param k: 选取的点的个数
:return: classes:标签类别
"""
# 获取data行数
size = data.shape[0]
# 作差 (其中np.tile(input,(size,1))作用是将input重复一次形成size大小的矩阵)
diff = np.tile(input,(size,1)) - data
# 求平方
sqdiff = diff ** 2
# 求和
squreDiff = np.sum(sqdiff,axis=1)
# 开根号
dist = squreDiff ** 0.5
# 排序 (argsort()根据元素的值从小到大对元素进行排序,返回下标)
# 比如a = [1,5,9,2,3]对应的下标为[0,1,2,3,4] 排序之后[1,2,3,5,9] 返回的结果是[0,3,4,1,2]
sortDist = np.argsort(dist)
# 对前k个最小距离点进行统计
classCount = {}
for i in range(k):
voteLabel = label[sortDist[i]]
# 对选取的前k个最小点的类别进行统计
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
# 统计所选类别出现最多的
maxCount = 0
for key,value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes
def dataTest(filepath):
"""
函数说明:分类器测试函数
Parameters:filepath
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
"""
# 将返回的特征矩阵和分类向量分别存储到datingDataMat和datingLabels中
datingDataMat, datingLabels = loadData(filepath)
# 取所有数据的百分之十
hoRatio = 0.10
# 数据归一化,返回归一化后的矩阵,数据范围,数据最小值
ranges,normMat, minVals = dataNorm(datingDataMat)
# 获得normMat的行数
rows = normMat.shape[0]
# 百分之十的测试数据的个数
nums = int(hoRatio * rows)
# 分类错误概率
errorRate = 0
for i in range(nums):
# 前nums个数据作为测试集,后rows - nums个数据作为训练集
classifyResult = classify(normMat[i,:],normMat[nums:rows,:],datingLabels[nums:rows],3)
print("分类结果:%d\t真实类别:%d" % (classifyResult, datingLabels[i]))
if classifyResult != datingLabels[i]:
errorRate += 1
print("错误率:%f%%" % (errorRate / float(nums) * 100))
if __name__ == '__main__':
filepath = "data.txt"
data,label = loadData(filepath)
dataTest(filepath)
运行结果:
6.完整代码
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from matplotlib.font_manager import FontProperties
def loadData(filename):
"""
:param filename: 文件路径名
:return: dataMat:数据集 lableMat:标签集
"""
# 读取文件
fr = open(filename)
# 读取文件内容
getFile = fr.readlines()
# 获取文件行数
lines = len(getFile)
# 定义存放标签的列表
lableMat = []
# 定义一个空矩阵,存放特征值的列表
emptyMat = np.zeros((lines,3))
# 初始化索引
index = 0
# 通过迭代读取数据
for line in getFile:
# 将每一行的数据的空格或者换行符去掉
lineArr = line.strip().split()
# 逐行读取前三列数据
#dataMat.append(lineArr[:3])
emptyMat[index,:] = lineArr[:3]
# 读取每一行的标签值(lineArr[-1]代表的是每一行最后一个元素)
lableMat.append(int(lineArr[-1])) # 为什么要转会出问题为int,因为我们的linArr[-1]是str类型,这里不类型转换后续操作
# 索引值自增
index += 1
return emptyMat,lableMat
def show(dataMat,lableMat):
"""
:param dataMat:
:param lableMat:
"""
# 设置汉字格式
font = FontProperties(fname=r"D:\python-workspace\SimHei.ttf", size=9)
# 设置颜色列表
LabelColros = []
# 给不同的标签添加上不同的颜色
for i in lableMat:
if i == 1:
LabelColros.append('black')
if i == 2:
LabelColros.append('orange')
if i == 3:
LabelColros.append('red')
# 画出散点图,以datas矩阵的第一(飞行常客例程)、第二列(玩游戏)数据画散点数据,散点大小为15,透明度为0.5
plt.scatter(dataMat[:,0].tolist(),dataMat[:,1].tolist(), color=LabelColros,s=15, alpha=.5)
# 设置标题
plt.title('每年获得的飞行常客里程数与玩视频游戏所消耗时间占比', FontProperties=font,color='r',size=10)
# 设置x轴
plt.xlabel('每年获得的飞行常客里程数', FontProperties=font,color='blue')
# 设置y轴
plt.ylabel('玩视频游戏所消耗时间占', FontProperties=font,color='orange')
# 设置图例
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
# 添加图例
plt.legend(handles=[didntLike, smallDoses, largeDoses])
# 显示
plt.show()
def dataNorm(dataSet):
"""
:param dataSet:
:return: diffs:最大最小之间的差值 normData:归一化的数据集
"""
# 获取数据集中每一列的最大值
maxValue = dataSet.max(0)
# print(maxValue)
# 获取数据集中每一列的最小值
minValue = dataSet.min(0)
# print(minValue)
# 最大值与最小值之间的差值
diffs = maxValue - minValue
# 获取dataSet行数
num = dataSet.shape[0] # num = 1000
# 定义一个和DataSet一样大小的矩阵
normData = np.zeros(dataSet.shape)
# 数据归一化(使数据属于(0,1)之间)
for i in range(num):
# 采用的是最值归一化:x = (x - min) / (max - min)
normData[i,: ] = (dataSet[i,:] - minValue) / diffs
return diffs,normData,minValue
def classify(input,data,label,k):
"""
:param input: 输入数据
:param data: 原数据集
:param label: 标签集
:param k: 选取的点的个数
:return: classes:标签类别
"""
# 获取data行数
size = data.shape[0]
# 作差 (其中np.tile(input,(size,1))作用是将input重复一次形成size大小的矩阵)
diff = np.tile(input,(size,1)) - data
# 求平方
sqdiff = diff ** 2
# 求和
squreDiff = np.sum(sqdiff,axis=1)
# 开根号
dist = squreDiff ** 0.5
# 排序 (argsort()根据元素的值从小到大对元素进行排序,返回下标)
# 比如a = [1,5,9,2,3]对应的下标为[0,1,2,3,4] 排序之后[1,2,3,5,9] 返回的结果是[0,3,4,1,2]
sortDist = np.argsort(dist)
# 对前k个最小距离点进行统计
classCount = {}
for i in range(k):
voteLabel = label[sortDist[i]]
# 对选取的前k个最小点的类别进行统计
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
# 统计所选类别出现最多的
maxCount = 0
for key,value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes
def classifyTest(filepath):
"""
:param filepath:
"""
# 设置分类结果
classResult = ['不喜欢','有些喜欢','非常喜欢']
# 用户输入三维特征
miles = float(input("每年获得的飞行常客里程数:"))
precentTats = float(input("玩视频游戏所耗时间百分比:"))
iceCream = float(input("每周消费的冰激淋公升数:"))
# 将输入的特征存入到数组中
inputs = np.array([miles,precentTats,iceCream])
# 处理数据
dataMat,labelMat = loadData(filepath)
# 训练集归一化
diffs,normData,minValue = dataNorm(dataMat)
# 测试集归一化
normInput = (inputs - minValue) / diffs
# 返回分类结果
classify_result = classify(normInput,normData,labelMat,3)
# 输出预测结果
print("你可能%s这个人" % (classResult[classify_result - 1]))
def dataTest(filepath):
"""
函数说明:分类器测试函数
Parameters:filepath
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
"""
# 将返回的特征矩阵和分类向量分别存储到datingDataMat和datingLabels中
datingDataMat, datingLabels = loadData(filepath)
# 取所有数据的百分之十
hoRatio = 0.10
# 数据归一化,返回归一化后的矩阵,数据范围,数据最小值
ranges,normMat, minVals = dataNorm(datingDataMat)
# 获得normMat的行数
rows = normMat.shape[0]
# 百分之十的测试数据的个数
nums = int(hoRatio * rows)
# 分类错误概率
errorRate = 0
for i in range(nums):
# 前nums个数据作为测试集,后rows - nums个数据作为训练集
classifyResult = classify(normMat[i,:],normMat[nums:rows,:],datingLabels[nums:rows],3)
print("分类结果:%d\t真实类别:%d" % (classifyResult, datingLabels[i]))
if classifyResult != datingLabels[i]:
errorRate += 1
print("错误率:%f%%" % (errorRate / float(nums) * 100))
if __name__ == '__main__':
filepath = "data.txt"
data,label = loadData(filepath)
#datas = np.mat(data)
#show(data,label)
# 这里需要将类型转换为float
# 问题:https://blog.csdn.net/u012535605/article/details/76675683
#dataNorm(datas.astype(float))
#dataTest(filepath)
classifyTest(filepath)
运行结果:
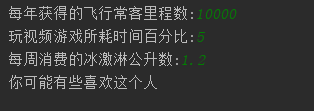
以上就是本人对KNN算法的一点见解,对于KNN的什么优缺点目前还没有理解到这个深度,后续学习会慢慢加上去。
未完待续....