PCA降维原理 操作步骤与优缺点
PCA全称是Principal Component Analysis,即主成分分析。它主要是以“提取出特征的主要成分”这一方式来实现降维的。
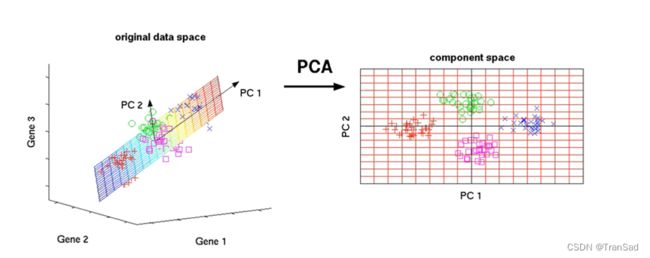
介绍PCA的大体思想,先抛开一些原理公式,如上图所示,原来是三维的数据,通过分析找出两个主成分PC1和PC2,那么直接在这两个主成分的方向上就可以形成一个平面,这样就可以把我们三位的样本点投射到这一个平面上(如右图)。那么此时的PC1和PC2都不单单是我们的其中某一维特征,而是各个特征通过某种线性变化的组合结果。这就是PCA降维宏观上的效果。
那PCA降维是如何实现的呢?在讲其具体实现原理前,先要清楚方差和协方差的概念:方差大概就是一些点在一个维度的偏差,越分散的话方差越大。而协方差是衡量一个维度是否会对另一个维度有所影响,从而查看这两个维度之间是否有关系。
PCA通过线性变换将元数据映射到新的坐标系中,使映射后的第一个坐标上的方差最大,第一个坐标也就是第一个主成分PC1,以此类推。在sklearn的PCA包中,有一个explained_variance_ratio_,它代表降维后的各主成分的方差值占总方差值的比例,这个比例越大,则越是重要的主成分。
那么,怎么样才能实现“找到那样一个坐标,使得数据在这个坐标上的映射方差最大”呢?按照下面的计算过程就可以实现这个效果。
PCA计算过程:
PCA总体计算步骤大概有:
首先对于数据集,有m个样本,设每个样本有n个维度。表示如下:

在上图中,其实只要看中间那幅图就行。左图和右图则是我分别用来突出样本的和特征的关系,比如第一列,就是第一个样本的所有值;而第一行,就是第一个特征的所有值。
对于每一个维度我们就可以得到均值,如下图所示:
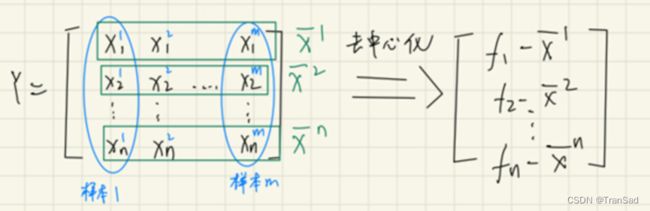
每一个维度减去这个均值,得到一个矩阵(相当于将坐标进行了平移)。
到这里,我们的数据“去中心化”就完成了,这样去中心化的目的就是:让每个特征下的均值都为0,后续计算特征之间协方差的时候就可以简化计算。注意,PCA的降维就是围绕每个特征(即每个坐标轴)进行展开,而不是围绕样本。因为就想开头图上描述的一样,样本点数量是不变化的,但是特征的维度会有改变,导致样本点的形状分布上发生变化。
最终,我们得到的去中心化结果如下:

现在,我们需要对处理后的数据在特征维度(也就是各个坐标轴之间)进行协方差矩阵的运算。
在图中我们一共有n个特征,若特征两两组合,我们会得到一个n^2的协方差矩阵。如下图所示:(其中每个f就是原数据中一行一行的特征)
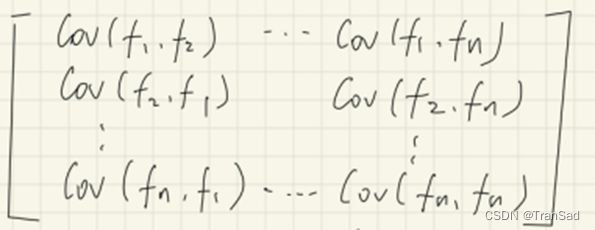
而协方差的定义为:
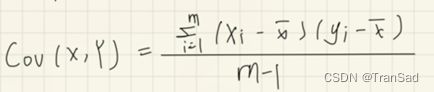
因为我们的去中心化操作,所有特征的均值(对应公式中的x和y的均值)已经变成0了,所以此时协方差可以表示成:
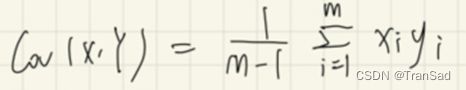
因此,协方差矩阵可以写成:
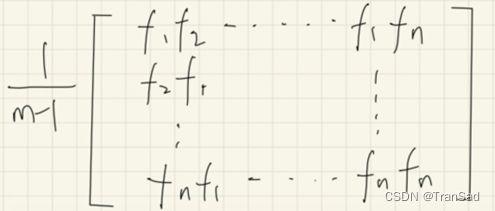
其中,m是样本点的个数,在上面已经提到过了。
(补充一点:其实可以发现,要得到这样的协方差矩阵,只需要原数据乘以自身的转置就能得到,如下图所示:
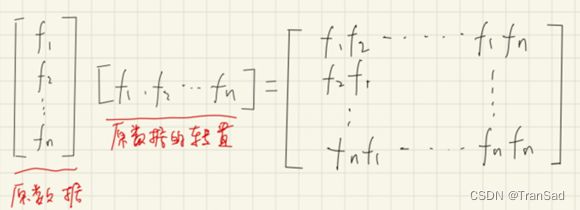
)
接下来,就是对协方差矩阵求特征值和特征向量,并根据特征值从大到小排序,每个特征值对应着一个特征向量。对于求特征值和特征向量的方法,其实就是用特征值分解,或者是svd矩阵分解,在这篇文章里有提到过,原理都类似。
有了特征值和特征向量,我们讲一下它们对应的意义和接下来的操作步骤:
先说结论:(我们知道得到的特征值和特征向量是一一对应的)
对协方差矩阵求出来的特征向量,就是新坐标轴方向、数据的旋转方向或者说是新的主成分方向。
对协方差矩阵求出来的特征值,就是数据在对应新坐标轴上投影的方差大小,或者说是其对应特征向量上包含的信息量。而某一特征值除以全部特征值和的商就为:其对应特征向量的(方差)贡献率。
我们希望数据在新坐标轴上投影的方差尽可能大,因此往往选取前k个最大特征值所对应的特征向量。将得到的特征值从大到小排序,对应的特征向量就是第一个主成分、第二个主成分……以此类推。将这些特征向量组成矩阵P,那么我们降维后的数据就是:

(这个降维方式也可以从矩阵乘法的顺序稍微的理解一下:特征向量的每一行(每一个特征向量)逐一去乘以原数据中的每条数据,逐一地去旋转和映射……)
至此,PCA降维的操作步骤就做完了。
但为什么根据协方差矩阵得出的特征值以及特征向量,就可以拿来对原数据进行降维呢?这里面就涉及数学比如拉格朗日之类的以及线性代数上面的推导和证明。比如从另一个角度来看,每一个新的坐标轴是由原来的坐标维度线性相加的结果。
仔细探究了一下,发现要画的图和说的意思实在太多了,就不钻了。总之,得出的特征向量构成的矩阵是一个完美的用于原数据“旋转”或者原坐标轴“线性相加”的矩阵,使得操作之后的数据在新坐标轴上有着最大的方差,以及最重要的——较少的坐标轴数。
关于n_components
关于主成分个数的确定,在scikit-learn中调用pca = PCA(n_components=n)时,有两种定义方式:
1.一种是把n设置成整数,比如n=3,表示要保留三个主成分,即新坐标轴有三个维度。
2.一种是把n设置成小数,假设所有特征向量加起来的贡献率是1,假定要0.95的主成分贡献率,就令n=0.95,那么就会按特征值从大到小一直加到累计贡献率大于等于0.95的特征向量个数,最终就会降到那个维。
第一种是偏向于指定维度的数量,第二种则偏向于指定主成分的保留程度。
PCA降维的优缺点
优点:
1.通过PCA降维之后的各个主成分之间是正交的,可以消除原始数据之间相互影响的因素。
2.PCA降维的计算过程并不复杂,因为主要就是对一个协方差矩阵做特征值分解,因此实现起来较简单容易。
3.在保留大部分主要信息的前提下,起到了降维效果。
缺点:
1.主成分特征维度的含义具有模糊性,解释性差。(我们最多可以理解成主成分只是由原来的坐标维度线性相加的结果,但加出来之后它到底是啥就不好说了)
2.PCA降维的标准是选取令原数据在新坐标轴上方差最大的主成分。但方差小的特征就不一定不重要,这样的唯一标准有可能会损失一些重要信息。
3.PCA毕竟是只保留特定百分比的主成分,属于“有损压缩”,难免会损失一些信息。