论文:Disentangled Motif-aware Graph Learning for Phrase Grounding
作者

Abstract
在本文中,我们提出了一个新的图形学习框架,用于图像中的phrase grounding。已有的研究从顺序图模型发展到稠密图模型,虽然捕捉到了粗粒度的上下文,但没有区分短语和图像区域之间上下文的多样性。相比之下,我们特别关注场景图上下文中隐含的不同主题,并设计了解构图网络来将主题感知上下文信息集成到表示中。此外,我们在特征和结构层面上采取干预策略来巩固和概括表征。最后,利用跨模态注意网络融合模态内特征,计算每个短语与区域的相似度,选择最佳匹配的短语。我们通过一系列消融研究验证了分离和介入图形网络(DIGN)的效率,我们的模型在Flickr30K实体和ReferIt游戏基准上实现了最先进的性能。
Introduction
在给出一对 image-sentence pair时,Phrase Grounding(或者更一般地说,language Grounding)任务旨在将多个名词短语从给定的句子基础到相应的意象区域,如图2所示。通过将文本模态与视觉模态对齐,Phrase Grounding能够将两种模态的知识联系起来,并改进跨视觉问答、视觉常识推理和机器人导航的多模态任务。
由于图像通常包含的信息多于句子的信息,一般的解决方案是理解视觉对象周围的视觉上下文,特别是注意句子所考虑的上下文,然后将其映射到所指的词。然而,以前的研究没有考虑到这样的细粒度的上下文。一些方法忽略了视觉或文本语境的重要性,也没有独立地(Plummer等人2018年)或顺序地(Dogan等人2019年;Li等人2020年)对单个短语进行分类。当具有完全不同功能或动作的对象在同一图像中具有相似的视觉效果时,这会导致性能不佳。最近,Bajaj等人(2019年)和Liu等人(2020年)利用完全连通的稠密图来捕获视觉对象中的粗粒度上下文,并改进基础结果。

然而,他们的图表有三个致命的问题。首先,稠密图包含有噪声的假连接,并且在复杂场景中出错。第二,平等对待所有关系。在这种框架下,节点(即短语或可视对象)表示是所有可能关系的混合。事实上,在上下文信息中揭示节点之间的各种高阶关系类别或主题(例如,装饰、部分、空间、动作)是不够的。例如,如图1所示,“子对象”需要固定在包含多个相似对象区域的图像中。如上所述,语言图(图1左下方)只是视觉内容的子图。当我们学习稠密图(图1左上角)中“一个孩子”的表示时,很难在嘈杂的环境中对右侧区域进行grounding。在场景图(图1的右上角)中过滤虚假邻域后,也很难做出grounding决策,因为孩子周围有太多的冗余基序,使模型无法抓住关键基序。第三,数据集中存在一些共同出现的视觉对象,而一些不相关的共同出现的概率很高(Wang等人,2020),这会影响图形结构,最终损害模型的鲁棒性和泛化能力。
在这篇文章中,我们提出了一个更易于解释的phrase grounding框架——解耦干涉图网络(DIGN)。首先,我们使用两个场景图来模拟短语和区域之间的上下文,而不是使用完全连通的稠密图。然后,我们使用两个解耦图网络将这些不同的上下文集成到节点(即短语或视觉对象)的解耦维表示中。每个块称为motif感知嵌入,可以表示特定motif的强度(图1的右下角),这大大减少了虚假连接产生的噪声,并为以后的模间融合创建细粒度的模内表示。此外,我们还提出了干预性视觉样本合成训练方案,以缓解同时发生的偏差问题,提高模型的鲁棒性。
- 我们的主要贡献有三个方面:
1.我们设计了一种基于解耦图网络的motif感知图学习方法,该方法区分了不同的上下文,并考虑了细粒度的上下文融合。
2.我们采用特征和结构干预策略来学习图中的鲁棒表示。
3.我们进行了一系列实验,证明我们的DIGN模型比先前sota实现了更具竞争力的性能。
Related Work
有两种文献与我们的工作密切相关:phrase grounding和disentangling representation
Phrase Grounding
为了对图像中短语描述的空间区域进行定位,早期方法(Wang等人2016a、2018;Plummer等人2018;Akbari等人2019;Plummer等人2020)学习共享嵌入子空间并计算每个短语区域对的距离。上述方法独立地为每个短语打下基础,忽略了文本和视觉上下文信息。更进一步,RNN结构(Hu,Xu等,2016;Dogan等,2019)和Transformer模型(Li等,2020)用于捕捉短语和区域之间的上下文。为了制定更复杂和非顺序的依赖关系,图形体系结构(Bajaj et al.2019;Liu et al.2020)变得越来越普遍,并利用节点之间的关系来丰富表示和实现对齐。他们从整体的角度统一处理上下文,这导致了次优的表示和有限的可解释性。忽略了一个基本事实:将短语与区域联系起来会受到图形上下文中不同主题的影响。我们的模型在细粒度层次上分离上下文,并将感知主题的上下文合并到表示中。
Disentangling Representation
学习识别和解开隐藏在观察数据的观察环境中的解释性因素是人工智能的基础。早期尝试(Tishby et al.20002015)仅将信息瓶颈方法应用于捕获和提取相关或有意义的数据摘要。基于信息论概念,β-V AE(Higgins et al.2017)可以以完全无监督的方式学习独立视觉数据生成因素的分离表示。后来的研究(Burgess et al.2018;Chen et al.2018)在更细粒度的水平上进一步改进了分离因子学习。这些现有的工作是为了发现非关系数据上的不同潜在因素。最近,在图结构数据领域探索了分离表示学习(Ma et al.2019;Zheng et al.2020),其中大部分主要是分离推荐系统中常见的二部图中用户行为背后的潜在因素。这项工作的重点不仅是在模态内场景图中解开主题,而且在跨模态公共子空间中保持解开。phrase grounding的解耦图网络与之前的模块化方法MattNet(Yu等人,2018)有关,但它隐含着分配组块表示的意义,并且便于转移到其他任务
Approach
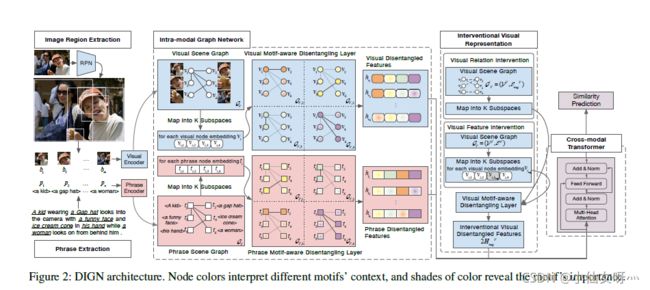
给定多个短语和相应的图像,我们将一组名词短语表示为 P = { p i } i = 1 n \mathcal{P}=\{p_{i}\}^{n}_{i=1} P={pi}i=1n,将其空间区域(或边界框)表示为 B + = { b i + } i = 1 n \mathcal{B^+}=\{b^+_{i}\}^{n}_{i=1} B+={bi+}i=1n,其中 b i = ( x 1 , y 1 , x 2 , y 2 ) b_{i}=(x_{1},y_{1},x_{2},y_{2}) bi=(x1,y1,x2,y2)是左上和右下坐标。主要目标是从区域建议 B = { b i } i = 1 m ( m > > n ) \mathcal{B}=\{b_{i}\}^{m}_{i=1}(m>>n) B={bi}i=1m(m>>n)中选择N个边界框,尽可能与Ground Truth注释 B + \mathcal{B^+} B+重叠,并获得ground结果。图2显示了我们的解耦介入图网络(DIGN)。该框架由四个阶段组成,在细粒度级别实现phrase grounding:1)短语和视觉特征encoding;2) 两个模态内解耦图网络;3) 视觉图形中的介入算子;4) 交叉模态transformer。
3.1 Phrase and Visual Encoders
每个短语由一个单词或一系列单词组成。对于短语特征,我们通过预先训练的BERT(Devlin et al.2019)将短语的每个单词编码为real-valued vector,然后通过取每个 p i p_{i} pi中单词嵌入的总和来计算短语表示。在视觉特征方面,我们使用region proposal network(Ren et al.2015)提取 top-M proposals with diversity and discrimination。在RoI-Align池的最后一个完全连接层之后表示每个项目(He等人,2017年)。要将短语和视觉特征转换为相同的维度,请使用 t i ∈ R d i n t t_{i}∈\R^{d^{t}_{in}} ti∈Rdint和 v i ∈ R d i n v v_{i}∈\R^{d^{v}_{in}} vi∈Rdinv分别通过两个完全连接的层、ReLU激活函数和批处理规范化层获得。
3.2 Intra-Modal Graph Network
为了分离名词短语和region proposal之间的各种上下文,并提供明确的渠道来引导Motif感知信息流,我们在下面介绍两个模态内分离图网络。
Phrase Disentangled Graph
我们不使用嘈杂的密集图来捕捉语言上下文,而是通过现成的场景图解析器(Schuster ET al.2015)从包含短语的图像标题构建短语场景图 G T = ( E T , V T ) \mathcal{G}_{T}=(\mathcal{E}^{T},\mathcal{V}^{T}) GT=(ET,VT)。形式上, V T = { t i } i = 1 n \mathcal{V}^{T}=\{t_{i}\}^{n}_{i=1} VT={ti}i=1n表示配备短语嵌入(i,j)的节点, ( i , j ) ∈ E T {(i,j)}∈\mathcal{E}^{T} (i,j)∈ET表示存在连接ti和tj的边,并且 N i T = { t j : ( i , j ) ∈ E T } \mathcal{N}^{T}_{i}=\{t_{j}:(i,j)∈ \mathcal{E}^{T}\} NiT={tj:(i,j)∈ET}表示 t i t_{i} ti的邻域。
当将短语定位到图像区域时,需要区分相似对象区域的情况是普遍而棘手的。直觉上,一个短语与邻居互动,并利用其上下文来区分区域。然而,不同的情况需要考虑邻里的不同背景。如图2所示,T1与T2、t3、t4和T6链接,其上下文包括“wearing”, “with”, “in”, and “look on from behind”高阶关系模式。语境可分为装饰、部分、空间和动作主题(decorative,part-of,spatial, and action motifs)。显然,孩子和女人都有funny faces,但funny faces是基于孩子独特的装饰图案(例如,他有一顶盖帽)和空间图案(例如,冰淇淋筒在他手上),这不属于woman的context。
因此,与标准图卷积网络(V eliˇckovi’c et al.2017;Xu et al.2019)不同,我们将自我节点的上下文视为一个整体来传递信息和更新,我们的目标是学习不同主题的分离表示,如下所示:

其中 h i T h^{T}_{i} hiT是 t i t_{i} ti的最终输出,K是控制latent motifs数量的超参数。期望 h i , k T ∈ R d o u t T K h^{T}_{i,k}∈\R^{{d^{T}_{out}}\over K} hi,kT∈RKdoutT整合了第k个mitif的上下文信息,独立于其他成分。对于所有节点的第k个分块嵌入,我们定义了一个MotionAware图 G T = ( V T , E T } \mathcal{G}_{T}=(\mathcal{V}^{T},\mathcal{E}^{T}\} GT=(VT,ET}。因此,我们构建了一组子图 G T = { G T , 1 , G T , 2 , … , G T , K } \mathcal{G}_{T}=\{\mathcal{G}_{T,1},\mathcal{G}_{T,2},…,\mathcal{G}_{T,K}\} GT={GT,1,GT,2,…,GT,K},以通过图分解层来细化有motif-aware的语言特征。
为了分离原始的混合嵌入,我们将TI投影到子空间中,如下所示:
 W和b表示通道k的参数,上标0表示原始解耦状态;σ(·)是一个非线性激活函数。我们使用L2规范化来确保数值稳定性,并防止特征过于丰富的邻居扭曲我们的预测。ti的其他分量被计算为 t i , k 0 t^{0}_{i,k} ti,k0,它们被馈送到相应的子图 G T , k \mathcal{G}_{T,k} GT,k。
W和b表示通道k的参数,上标0表示原始解耦状态;σ(·)是一个非线性激活函数。我们使用L2规范化来确保数值稳定性,并防止特征过于丰富的邻居扭曲我们的预测。ti的其他分量被计算为 t i , k 0 t^{0}_{i,k} ti,k0,它们被馈送到相应的子图 G T , k \mathcal{G}_{T,k} GT,k。
在初始化motif感知子图的节点后,我们提取邻域的有用信息来综合捕获潜在因素的上下文。对于每个motif感知子图,我们设计了一个短语图分离层: 其中 a j , k T 1 ( a j , k T 1 ≥ 0 , ∑ k ′ = 1 K a j , k T 1 = 1 ) {a_{j,k}^{T}}^{1}({a_{j,k}^{T}}^{1}≥0,\sum ^{K}_{k'=1} {a_{j,k}^{T}}^{1}=1) aj,kT1(aj,kT1≥0,∑k′=1Kaj,kT1=1)提供了第k个motif t j t_{j} tj与 t i t_{i} ti相关的重要性; N i \mathcal{N}_{i} Ni是 t i t_{i} ti的一级邻居; W e k T 1 {W_{ek}^{T}}^{1} WekT1和 W k T 1 ∈ R d o u t T K × d o u t T K {W_{k}^{T}}^{1}∈\R^{{{d^{T}_{out}}\over K}×{{d^{T}_{out}}\over K}} WkT1∈RKdoutT×KdoutT分别在第k个方面给出自我节点和邻居节点的可学习参数;上标1表示图形分离层与one-hop邻居的输出;σ是ReLU激活函数dropout为0.5的置信度。
其中 a j , k T 1 ( a j , k T 1 ≥ 0 , ∑ k ′ = 1 K a j , k T 1 = 1 ) {a_{j,k}^{T}}^{1}({a_{j,k}^{T}}^{1}≥0,\sum ^{K}_{k'=1} {a_{j,k}^{T}}^{1}=1) aj,kT1(aj,kT1≥0,∑k′=1Kaj,kT1=1)提供了第k个motif t j t_{j} tj与 t i t_{i} ti相关的重要性; N i \mathcal{N}_{i} Ni是 t i t_{i} ti的一级邻居; W e k T 1 {W_{ek}^{T}}^{1} WekT1和 W k T 1 ∈ R d o u t T K × d o u t T K {W_{k}^{T}}^{1}∈\R^{{{d^{T}_{out}}\over K}×{{d^{T}_{out}}\over K}} WkT1∈RKdoutT×KdoutT分别在第k个方面给出自我节点和邻居节点的可学习参数;上标1表示图形分离层与one-hop邻居的输出;σ是ReLU激活函数dropout为0.5的置信度。
方程4是first-order neighbor routing的关键步骤。当与所有neighbor 计算时,我们可以得到Motif K的上下文信息,这与注意机制类似,但并不完全相同。注意机制如图形注意网络(Wang et al.2019)粗略地聚合了onehop邻居,并将自我节点作为一个整体进行更新,导致难以区分不同的上下文和entangling latent motifs。相反,neighbor rooting mechanism 将节点分为k个组件,每个组件可以参与相似的上下文并提供可解释的结果。
使用单跳邻居后,我们可以堆叠更多的图分离层,以从高阶邻居收集有影响的信号。经过几年的研究,我们将不同层面上的MotionAware表示总结为第k个块表示: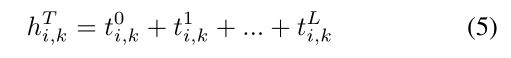 我们认为, h i , k T h ^{T}_{i,k} hi,kT描述了与第k个motif相关的语义语境。最后,如等式1所示,我们将K个块连接起来,在L个层分离后更新$t_{i} $。因此,我们不仅要理清phrase grounding,还要解释它们的每一部分。
我们认为, h i , k T h ^{T}_{i,k} hi,kT描述了与第k个motif相关的语义语境。最后,如等式1所示,我们将K个块连接起来,在L个层分离后更新$t_{i} $。因此,我们不仅要理清phrase grounding,还要解释它们的每一部分。
Visual Disentangled Graph
我们通过场景图生成模型(Zellers et al.2018)建立了视觉场景图 G V = ( V V , E V } \mathcal{G}_{V}=(\mathcal{V}^{V},\mathcal{E}^{V}\} GV=(VV,EV}),该模型利用了区域方案之间的视觉关系。
我们假设,视觉图形语境暗示了与短语图形语境中相同的主题类别。因此,我们还将可视节点嵌入分割成K个分量,每个分块节点嵌入构造独立的子图 G V , k = ( V k V , E V } \mathcal{G}_{V,k}=(\mathcal{V}^{V}_{k},\mathcal{E}^{V}\} GV,k=(VkV,EV})。 G V \mathcal{G}_{V} GV由Kmotif感知图 { G V , 1 , G V , 2 , … , G V , K } \{\mathcal{G}_{V,1},\mathcal{G}_{V,2},…,\mathcal{G}_{V,K}\} {GV,1,GV,2,…,GV,K}组成。与短语图网络类似,我们使用另一个分离的图网络将包含不同主题的视觉上下文集成到表示中。更多细节见附录A的算法1。
我们首先将每个 v i v_{i} vi映射到 K K K个子空间,通过线性变换初始化 K K K个分块嵌入:

其中 W e k V 1 {W_{ek}^{V}}^{1} WekV1, W k V 1 ∈ R d o u t V K × d o u t V K {W_{k}^{V}}^{1}∈\R^{{{d^{V}_{out}}\over K}×{{d^{V}_{out}}\over K}} WkV1∈RKdoutV×KdoutV, a j , k V 1 {a_{j,k}^{V}}^{1} aj,kV1是可视图形网络中neighbor rooting mechanism的产物。在迭代更多层之后,每个块 h i , k V h_{i,k}^{V} hi,kV的最终输出是通过将每层的 v i v_{i} vi隐藏状态相加得到的: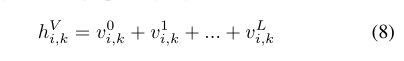 解开的结果 h i V h_{i}^{V} hiV描述为:
解开的结果 h i V h_{i}^{V} hiV描述为: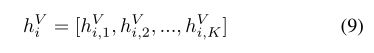
3.3 Interventional Visual Representation
数据集的共现偏差,即不相关的关系,可能导致错误的注意。当使用非解耦图网络对图像中区域的上下文进行建模时,有偏差的数据可能会通过上下文聚合使用不相关的信息来困扰分块表示。值得注意的是,编码器的视觉特征容易受到偏差的影响(Cadene et al.2019)。因此,我们在解耦网络中干预表征学习,以减少偏差和鲁棒表征的影响。
干预的核心思想是改变环境,用更多看不见的数据帮助模型训练,并发现更多可能的原因。在训练过程中,我们利用干预策略来提高motif-aware学习。在图形结构数据的特征层和结构层构造介入样本是有效的。与掩蔽注意区域策略(Liu等人,2019年)相比,我们的策略不依赖于语言注意,更灵活地学习图形中的上下文感知特征。介入过程的伪代码见附录B。
我们 首先介绍了结构干预策略。我们的目标是改变视觉场景图中的原始边。在修改边的节点时,只需修改方向边的目标节点即可。通过这种方式,它可以尽可能消除更改其他连接节点功能的影响。我们中断并随机交换可视图形中所有目标节点的边。这些对比样本将不相关的motif上下文集成到邻居路由机制的表示中,有助于网络掌握节点之间的自然motif。
通过使用错误数据掩盖正确的分块特征,合成特征样本。有两种类型的掩蔽特征介入方法。一种是替换相应维度中相邻节点的特征。Neighbors通常在语义方面类似于ego node,使得模型能够区分相似的情况。另一种是用噪声分布填充分块嵌入的每个维度。生成的特征被视为噪声训练数据。该模型可以学习更多的不可见样本,并具有对噪声数据的恢复能力。因此,干预样本可以促进模型自动发现和理解被替换语块的意义,从而实现phrase grounding。
我们在第3节中定义了特定的损失函数。5充分利用介入标本。此外,干预模块对于主题感知学习至关重要,这在以下消融研究中得到了证明。
3.4 Cross-Modal Transformer
为了在共享空间中对齐两个模态表示,我们引入了一个跨模态转换器,如图2最后一列所示。与两个模态特征的简单串联不同,多头注意机制可以使每个头部块从两个模态分离的表征中捕获相应的motif信息。当视觉信息被注入到语言编码中,并且语言信息被合并到视觉编码中时,转换器可以动态地为目标表示选择明智的线索。
我们表示Transformer为 h T = { h 1 T , h 2 T , … , h n T } h^{T}=\{h^{T}_{1},h^{T}_{2},…,h^{T}_{n}\} hT={h1T,h2T,…,hnT}和 h V = { h 1 V , h 2 V , … , h m V } h^{V}=\{h^{V}_{1},h^{V}_{2},…,h^{V}_{m}\} hV={h1V,h2V,…,hmV}的输入,分别由短语和可视图形网络处理。具体来说,多头注意力被计算为Multihead(Q, K, V),其中Q是查询,K是键,v是值。详情可参考V aswani等人(2017年)。两个模态特征通过以下方式相互作用:
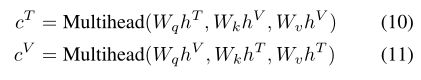 其中 W q W_{q} Wq、 W k W_{k} Wk和 W v W_{v} Wv是可学习的权重, c T c^{T} cT是来自短语的混合特征,而 c V c^{V} cV是来自区域的引导表示。
其中 W q W_{q} Wq、 W k W_{k} Wk和 W v W_{v} Wv是可学习的权重, c T c^{T} cT是来自短语的混合特征,而 c V c^{V} cV是来自区域的引导表示。
通过这种形式Transformer,语言和视觉特征相关联,因此相似性预测被定义为:![]() 我们只使用inner(dot)product来实现最先进的性能。相似性得分被认为是短语Pi是否与图像区域Bi相匹配的概率。
我们只使用inner(dot)product来实现最先进的性能。相似性得分被认为是短语Pi是否与图像区域Bi相匹配的概率。
Training Objectives
我们的损失函数包括三个部分。第一部分是独立损失。为了鼓励节点嵌入的K成分是独立的,我们应用距离相关(Székely et al.2007)来描述任意两个成对向量的独立性。当且仅当这些向量是独立的时,每对向量的系数为零。在短语解耦网络之后,我们将短语组块嵌入的独立损失公式化为: 其中 C o v ( ⋅ ) Cov(·) Cov(⋅)和 D ( ⋅ ) D(·) D(⋅)分别表示向量之间的协方差和方差。同样,作为第二部分的视觉独立损失计算如下:
其中 C o v ( ⋅ ) Cov(·) Cov(⋅)和 D ( ⋅ ) D(·) D(⋅)分别表示向量之间的协方差和方差。同样,作为第二部分的视觉独立损失计算如下:
 第三部分是跨模态grounding损耗。对于短语 p i p_{i} pi, B \mathcal{B} B中的最佳匹配结果 b i b_{i} bi的面积最大,与ground truth b i + b_{i}^+ bi+重叠。我们将 { B − b i } \{\mathcal{B}-b_{i}\} {B−bi}表示为 M−1失败的结果。对于介入模型的输出,我们改变了它们的表示,并将其与Ground Truth处理为不匹配。总共有 2 M − 1 2M-1 2M−1负面样本。本文中我们不是最小化负对数似然的正确相关系数,我们设计了一个对比损失函数,称为InfoNCE(OORD,李,和VIYYARS 2018):
第三部分是跨模态grounding损耗。对于短语 p i p_{i} pi, B \mathcal{B} B中的最佳匹配结果 b i b_{i} bi的面积最大,与ground truth b i + b_{i}^+ bi+重叠。我们将 { B − b i } \{\mathcal{B}-b_{i}\} {B−bi}表示为 M−1失败的结果。对于介入模型的输出,我们改变了它们的表示,并将其与Ground Truth处理为不匹配。总共有 2 M − 1 2M-1 2M−1负面样本。本文中我们不是最小化负对数似然的正确相关系数,我们设计了一个对比损失函数,称为InfoNCE(OORD,李,和VIYYARS 2018):
 其中,sim(·)是相似性预测的输出,sum是一个positive和2M-1个negative region,τ表示temperature参数。在训练过程中,对于任何短语 p i p_{i} pi,模型都被调整为最大化log参数的分子,同时最小化其分母。因此,该模型能够全面了解真实样本与介入样本之间的差异。
其中,sim(·)是相似性预测的输出,sum是一个positive和2M-1个negative region,τ表示temperature参数。在训练过程中,对于任何短语 p i p_{i} pi,模型都被调整为最大化log参数的分子,同时最小化其分母。因此,该模型能够全面了解真实样本与介入样本之间的差异。
最终,所有损失都进行了优化,以更新可学习的参数:
![]()
Experiments and Results
4.1 Datasets and Evaluation
我们在两个常见的phrase grounding数据集上验证了我们的模型。Flickr30K实体(Plummer et al.2015)包含31783幅图像,其中每幅图像对应五个带有注释的名词短语的标题。与这项工作(Dogan等人,2019年)一致,当一个短语用多个Ground Truth边界框注释时,我们合并这些框,并使用并集区域作为其Ground Truth。我们将数据集分成30k个图像进行训练,1k个用于验证,1k个用于测试。ReferIt游戏(Kazemzadeh等人,2014)包含20000张图像和99535个分割图像区域。每个图像都配有多个引用短语和相应的边框。我们使用与Akbari等人(2019)相同的分割,其中包含10k训练和10k测试图像。我们在附录D中添加了关于Ref COCO的补充实验。当且仅当预测框及其Ground Truth至少为0时,数据集中的名词短语是正确的基础。5 IoU(联合体上的交叉点)。根据这些标准,我们的绩效衡量标准是接地准确度,即正确接地的名词短语与测试集中短语总数的比率。
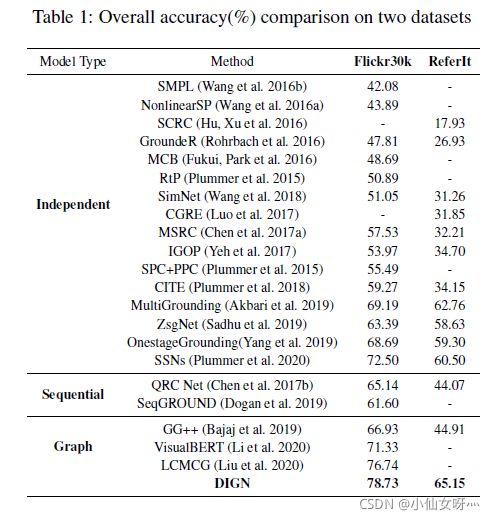

Qualitative results
从图3中,我们可以看到解耦图网络模块和介入模块的贡献。图的上半部分将图形注意网络与解耦图形网络进行了比较,证明解耦模块可以通过分块表示而不是混乱表示来区分相似对象。下半部分提供了一些有趣的数据,因为介入模块可以在结构层面上减少偏差并打破虚假关系(例如,狗通常与人和街道而不是羊同时出现),并在特征层面上识别对象之间的细微差异(例如,狗的特征)将“蓝色衬衫”和“蓝色和白色裙子”替换为其他颜色,以学习内在颜色特征)。
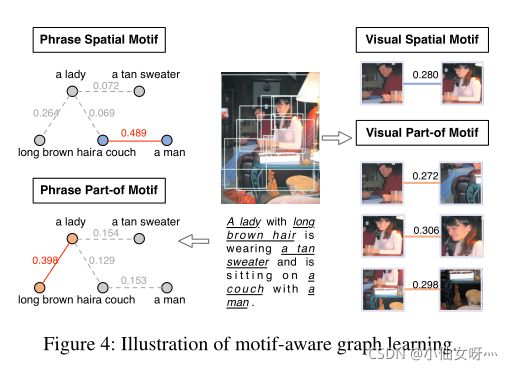
我们通过可视化邻域路由的权重,以实证的方式检验选取了什么样的motif。图4显示了学习到的空间motif和部分motif的post-hoc解释。附录D中有更多细节。左栏显示了短语场景图中上下文的两个潜在主题,右栏显示了与视觉场景图中短语对应的主题。对于短语子图,彩色节点表示它们在当前主题中与其他主题最相关。视觉场景图中的关系太多,很难在图中显示出完整的图形,因此我们只能通过彩色边缘来可视化分块节点之间最突出的主题上下文。从图4中的结果来看,视觉图形中包含的主题感知上下文比短语图形中包含的主题感知上下文要多,即使是分离的。因此,计算相应分块嵌入的相似性以实现grounding是合理的。附录E中提供了我们模型的其他接地结果。
Conclusion
在这篇文章中,我们提出了一个用于phrase Grounding任务的解耦干预性主题感知学习框架。解耦图网络区分不同mitif的重要性,将motif感知上下文集成到模态内场景图的节点表示中,并提供可解释的结果。然后,在特征和结构方面的干预方案提高了对有偏数据的恢复能力和泛化能力。最后,在跨模态Transformer中融合细粒度模态内表示,完成相位grounding。我们的方法(DGIN)在两个公共数据集上进行了演示,其性能大大超过了最新技术。在我们未来的工作中,这些任务,构建更精确的场景图和grounding phrase,应该考虑相互增强。此外,我们还想对跨模态融合进行深入分析。