图神经网络(ICML2022)
NAFS: A Simple yet Tough-to-beat Baseline for Graph Representation Learning(图嵌入)
最近,图神经网络(gnn)通过利用图结构和节点特征的知识,在图表示学习中表现出突出的性能。然而,它们中的大多数都有两个主要的限制。首先,gnn可以通过堆叠更多的层来学习更高阶的结构信息,但由于过度平滑问题,无法处理大深度。其次,由于计算开销和内存占用较大,这些方法不适用于大型图。本文提出节点自适应特征平滑(NAFS),一种简单的非参数方法,无需参数学习即可构建节点表示。该算法首先通过特征平滑提取每个节点及其不同跳数的邻居节点的特征,然后自适应地将平滑后的特征进行组合。此外,通过不同的平滑策略提取的平滑特征进行集成,可以进一步增强构建的节点表示。在4个基准数据集上对节点聚类和链接预测2种不同的应用场景进行了实验。值得注意的是,具有特征集成的NAFS在这些任务上优于最先进的GNN,并缓解了大多数基于学习的GNN对应方法的上述两个限制。
方法:
只需平滑节点特征,然后以节点自适应的方式组合平滑特征。将这种方法命名为节点自适应特征平滑(NAFS),其目标是构建更好的节点嵌入,融合图结构信息和节点特征的信息。
GraphFM: Improving Large-Scale GNN Training via Feature Momentum
训练用于大规模节点分类的图神经网络(GNNs)具有挑战性。一个关键的难点在于获取准确的隐藏节点表示,同时避免邻域爆炸问题。本文提出一种名为特征动量(FM)的新技术,在更新特征表示时使用动量步骤来纳入历史嵌入。本文开发了两种特定的算法,即GraphFM-IB和GraphFM-OB,分别考虑批内和批外数据。GraphFM-IB将FM应用于批内采样数据,而GraphFM-OB将FM应用于批外数据,即批内数据的一跳邻域。本文给出了GraphFM-IB的收敛性分析和GraphFM-OB的一些理论见解。实验观察到GraphFM-IB可以有效缓解现有方法的邻域爆炸问题。此外,GraphFM-OB在多个大规模图数据集上取得了良好的性能。
方法:
基于FM,本文提出了两种基于子采样节点估计和伪全邻域估计的算法。第一个算法称为GraphFM-IB,它在批量节点采样后应用FM。GraphFMIB递归地对目标节点的1跳邻居进行采样,然后使用动量步长从其采样的邻居中聚合嵌入来更新它们的历史嵌入。第二种算法称为GraphFM-OB,使用基于簇的采样来绘制批处理节点,并使用FM用批处理节点传递的消息更新批处理节点的1跳的历史嵌入
Topology-Aware Network Pruning using Multi-stage Graph Embedding and Reinforcement Learning
模型压缩是在功耗和内存受限的资源上部署深度神经网络(dnn)的一项关键技术。然而,现有的模型压缩方法往往依赖人工经验,关注参数的局部重要性,忽略了深度神经网络中丰富的拓扑信息。本文提出一种新的基于图神经网络(GNNs)的多阶段图嵌入技术,以识别DNN拓扑结构,并使用强化学习(RL)来找到合适的压缩策略。执行了资源受限(FLOPs)的通道修剪,并将所提出方法与最先进的模型压缩方法进行了比较。在各种模型上评估了所提出方法,从典型的到移动友好的网络,如ResNet系列、VGG-16、MobileNet-v1/v2和ShuffleNet。结果表明,所提出方法可以以最小的微调成本实现更高的压缩比,并产生出色的和有竞争力的性能。
问题:
1)然而,它们要么使用手动定义的规则/嵌入,忽略丰富的拓扑信息,要么在模型压缩时不考虑拓扑变化。
2)基于强化学习的方法以来,通常使用剪枝后的模型精度作为RL智能体的奖励函数,压缩率和奖励之间出现负相关。

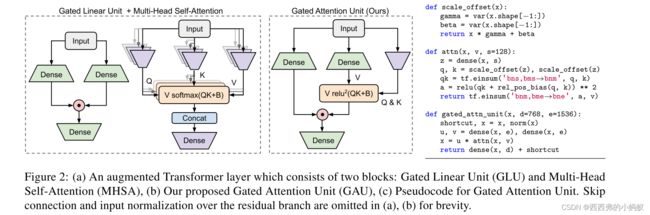
Transformer Quality in Linear Time
本文重新审视了transformer的设计选择,并提出了解决其在处理长序列方面的弱点的方法。提出一种名为门控注意力单元的简单层,允许使用更弱的单头注意力,以最小的质量损失。本文提出一种线性逼近方法,与这个新层互补,对加速器友好,在质量上具有竞争力。由此产生的模型名为FLASH3,与改进的transformer在短(512)和长(8K)上下文长度上的困惑度相匹配,在自回归语言建模方面,在Wiki-40B上实现了高达4.9倍的训练加速,在PG-19上实现了12.1倍的训练加速,在掩码语言建模方面在C4上实现了4.8倍的训练加速。
Rethinking Graph Neural Networks for Anomaly Detection
图神经网络(GNNs)被广泛应用于图异常检测。由于GNN设计的关键组件之一是选择一个定制的谱滤波器,因此通过图谱的透镜来分析异常迈出了第一步。我们的关键观察是,异常的存在将导致“右移”现象,即频谱能量分布更少地集中在低频而更多地集中在高频。这一事实促使我们提出Beta小波图神经网络(BWGNN)。事实上,BWGNN具有光谱和空间局部化带通滤波器,以更好地处理异常中的“右移”现象。在四个大规模异常检测数据集上证明了BWGNN的有效性。
问题:
普通gnn并不适合异常检测,并存在过度平滑问题。当GNN从节点邻域聚合信息时,它还将异常表示平均化,使其难以区分。因此,通过有意连接大量的良性邻域,异常节点可能会降低其可疑度,这导致普通gnn的性能较差

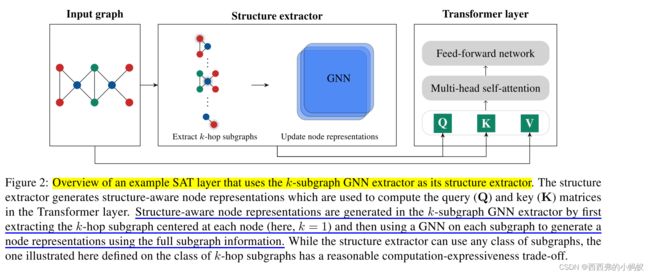
Structure-Aware Transformer for Graph Representation Learning
Transformer架构最近在图表示学习中获得了越来越多的关注,因为它通过避免严格的结构归纳偏差,而仅通过位置编码对图结构进行编码,自然地克服了图神经网络(gnn)的几个限制。本文表明,由具有位置编码的Transformer生成的节点表示不一定捕获它们之间的结构相似性。为解决这个问题,本文提出结构感知的Transformer,一类基于新的自注意力机制的简单而灵活的图Transformer。这种新的自注意力在计算注意力之前,通过提取以每个节点为根的子图表示,将结构信息融入到原始的自注意力中。本文提出了几种自动生成子图表示的方法,并从理论上表明,所得到的表示至少与子图表示一样具有表现力。根据经验,所提出方法在五个图预测基准上取得了最先进的性能。所提出的结构感知框架可以利用任何现有的GNN来提取子图表示,相对于基本GNN模型,它系统地提高了性能,成功地结合了GNN和transformer的优势。
Feature Learning and Signal Propagation in Deep Neural Networks
Baratin等人最近的工作(2021)揭示了深度神经网络训练过程中发生的一个有趣的模式:与其他层相比,一些层与数据对齐得更多(其中对齐定义为切线特征矩阵和数据标签矩阵的欧氏乘积)。作为层索引函数的对齐曲线(通常)表现出一种上升下降模式,在某些隐藏层达到最大值。本文为这种现象提供了第一个解释。本文提出平衡假设,将这种对齐模式与深度神经网络中的信号传播联系起来。实验表明,与理论预测有很好的匹配。
Generalization Guarantee of Training Graph Convolutional Networks with Graph Topology Sampling
图卷积网络(GCNs)最近在学习图结构数据方面取得了巨大的经验成功。为了解决邻近特征递归嵌入导致的可扩展性问题,图拓扑采样被提出用于减少训练GCNs的内存和计算成本,在许多实证研究中取得了与不使用拓扑采样的GCNs相当的测试性能。本文为训练(最高)三层GCNs中的图拓扑采样提供了第一个理论依据,用于半监督节点分类。本文正式描述了图拓扑采样的一些充分条件,使GCN训练导致泛化误差减少。此外,该方法解决了各层权重的非凸相互作用,这在现有的GCNs理论分析中未得到充分探索。文中明确刻画了图结构和拓扑采样对泛化性能和采样复杂度的影响,并通过数值实验验证了理论发现的正确性。
方法:
本文首次对使用图拓扑采样训练GCNs进行了泛化分析。本文关注半监督节点分类问题,在所有节点特征和部分节点标签的情况下,目标是预测未知节点标签。我们从以下几个方面总结了我们的贡献:
首先,提出了一种同时实现随机梯度下降(SGD)和图拓扑采样的训练框架,并保证学习到的具有整流线性单元(ReLU)激活的GCN模型逼近一大类目标函数的最佳泛化性能。此外,随着标记节点数量和神经元数量的增加,目标函数的类别也随之扩大,表明泛化能力有所提高

Learning to Solve PDE-constrained Inverse Problems with Graph Networks
学习图神经网络(gnn)最近被建立为原理求解器在模拟物理系统动力学中的快速和准确的替代方案。然而,在科学和工程的许多应用领域中,我们不仅对正向模拟感兴趣,还对解决由偏微分方程(PDE)定义的约束逆问题感兴趣。本文探索gnn来解决这种pconstrained逆问题。结合自解码器风格先验的gnn非常适合这些任务,当应用于波动方程或Navier-Stokes方程时,比其他学习方法实现了更准确的初始条件或物理参数估计。与原则性求解器相比,gnn的计算速度提高了90倍。
有趣的工作 偏微分方程和图神经网络结合起来实现偏微分方程中的参数预测
Conditional GANs with Auxiliary Discriminative Classifier
条件生成模型旨在学习数据和标签的潜在联合分布,以实现条件数据的生成。其中,辅助分类器生成对抗网络(AC-GAN)得到了广泛应用,但存在生成样本的类内多样性低的问题。本文指出的根本原因是AC-GAN的分类器与生成器无关,因此无法为生成器提供信息指导以接近联合分布,导致条件熵最小化,从而降低了类内多样性。受这种理解的启发,本文提出一种带有辅助判别分类器的条件生成对抗网络(ADC-GAN)来解决上述问题。具体来说,通过区分真实数据和生成数据的类别标签,所提辅助判别分类器具有生成器感知能力。
理论分析表明,即使没有原始鉴别器,生成器也可以忠实地学习联合分布,使得所提出的ADC-GAN对系数超参数的值和GAN损失的选择具有鲁棒性,并且在训练过程中是稳定的。在合成和真实数据集上的广泛实验结果表明,与最先进的基于分类器和基于投影的条件gan相比,ADC-GAN在条件生成建模方面具有优越性。
背景:1)AC-GAN的低类内多样性问题是分类器对生成的数据分布是不可知的,因此不能为生成器学习目标分布提供信息性指导
2)分类器的判别能力使其能够像判别器一样提供真实数据分布与生成数据分布之间的差异,分类能力使其能够捕捉数据与标签之间的依赖关系。
Off-Policy Reinforcement Learning with Delayed Rewards
本文研究具有延迟奖励的深度强化学习(RL)算法。在许多现实世界的任务中,即时奖励通常不是很容易获得的,甚至在智能体执行行动后立即定义。本文正式定义了具有延迟奖励的环境,并讨论了由于这种环境的非马尔可夫性质而提出的挑战。引入了一个通用的非策略强化学习框架,该框架具有一个新的q函数公式,可以处理具有理论收敛保证的延迟奖励。对于具有高维状态空间的实际任务,进一步在框架中引入q函数的hc -分解规则,自然会产生一种近似方案,有助于提高训练效率和稳定性。最后进行了广泛的实验,证明了所提出算法比现有工作及其变体的优越性能

Class-Imbalanced Semi-Supervised Learning with Adaptive Thresholding
半监督学习(SSL)已被证明通过利用未标记的数据成功地克服了标记困难。以前的SSL算法通常假设类分布均衡。然而,现实世界的数据集通常是类别不平衡的,导致现有SSL算法性能严重下降。一个根本原因是,未标记数据的伪标签是根据固定的置信阈值选择的,导致在少数类上的性能低下。提出了一个简单而有效的SSL算法框架,该框架只涉及对不同类别的SSL算法进行自适应阈值化,并在20多种不平衡比率上取得了显著的性能提升。显式优化SSL目标中每个类的伪标签数量,从而同时获得自适应阈值和最小化经验风险。此外,自适应阈值的确定可以通过闭式求解得到。大量的实验结果验证了所提算法的有效性。

The State of Sparse Training in Deep Reinforcement Learning
近年来,稀疏神经网络的使用迅速增长,特别是在计算机视觉领域。它们的吸引力主要来自于训练和存储所需的参数数量的减少,以及学习效率的提高。有点令人惊讶的是,很少有努力探索它们在深度强化学习(DRL)中的使用。本文对在各种深度强化学习智能体和环境上应用一些现有的稀疏训练技术进行了系统的研究。结果证实了计算机视觉领域中稀疏训练的发现——在深度强化学习领域,在相同的参数数量下,稀疏网络比密集网络表现更好。详细分析了稀疏网络的使用如何影响深度强化学习中的各个组成部分,并提出了提高稀疏训练方法有效性的有希望的途径,以及推进它们在DRL1中的使用。
Efficient Representation Learning via Adaptive Context Pooling
自注意力机制通过使用所有输入标记之间的成对注意力来建模长程上下文。在此过程中,它们假设由单个标记(例如,文本字符或图像像素)定义的固定注意力粒度,这可能不是在更高层次上对复杂依赖关系进行建模的最佳选择。本文提出ContextPool,通过调整每个token的注意力粒度来解决这个问题。受卷积网络与池化相结合以捕获长程依赖关系的成功启发,在计算给定注意力层中的注意力之前,学习将每个token的相邻特征池化。池化权重和支持度大小是自适应确定的,允许池化特征以不同的规模编码有意义的上下文。
ContextPool使注意力模型更具表现力,通常用更少的层实现强大的性能,从而显著降低了成本。实验验证了所提出的ContextPool模块,当插入transformer模型时,在几个语言和图像基准上使用较少的计算,匹配或超过了最先进的性能,在学习到的上下文大小或稀疏注意力模式方面优于最近的工作,并且也适用于ConvNets的高效特征学习。
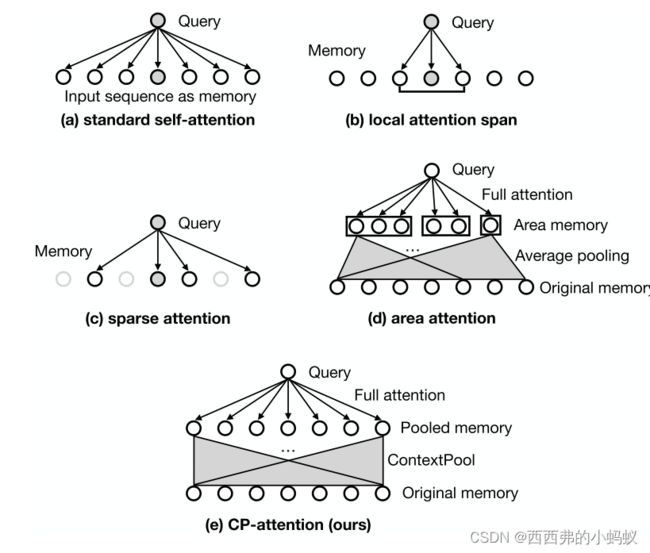

方法:
本文提出ContextPool,一种用于transformer和卷积网络(ConvNets)的插入和低成本模块,以增强其对动态尺度的长程上下文建模的能力,从而促进高效的表示学习。ContextPool背后的想法通常受到ConvNets的启发,这些网络具有局部感受野和池化操作。在transformer中计算完全注意力之前,我们类似地学习在每个注意力层中对每个token的相邻特征进行池化。重要的是,池化权重和支持度大小是输入自适应的。这允许池化特征以动态尺度编码有意义的上下文。因此,池化特征之间的自注意力可以显式地捕获上下文之间的高层依赖关系。
