第七次周报
第7次周报
- cnn经典模型的学习
-
- Lenet-5
- 文献阅读
-
- 摘要
- 结构流程
-
- 数据预处理
- 搭建的网络结构
- CNN 2L超参数
- 研究成果
- 总结
cnn经典模型的学习
上周分析了lenet-5的结构和优缺点,本周进行代码实践,并对出现的问题进行解决。其他模型所需数据量较大,下周配好服务器后将继续进行实验
Lenet-5
使用mnist数据集训练并测试了Lenet_5,代码如下:
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 导入数据集并处理
(train_images,train_labels),(test_images,test_labels) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(60000,28,28,1)
test_images = test_images.reshape(10000,28,28,1)
train_images = train_images / 255
test_images = test_images / 255
train_labels = np.array(pd.get_dummies(train_labels))
test_labels = np.array(pd.get_dummies(test_labels))
models = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=6,kernel_size=(5,5),input_shape=(28,28,1),padding='same',activation='sigmoid'),
tf.keras.layers.AveragePooling2D(pool_size=(2,2)),
tf.keras.layers.Conv2D(filters=16,kernel_size=(5,5),activation='sigmoid'),
tf.keras.layers.AveragePooling2D(pool_size=(2,2)),
tf.keras.layers.Conv2D(filters=120,kernel_size=(5,5),activation='sigmoid'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(84,activation='sigmoid'),
tf.keras.layers.Dense(10,activation='softmax')
])
models.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['acc'])
history = models.fit(train_images,train_labels,batch_size=128,epochs=10,validation_data=(test_images,test_labels))
运行结果如下:
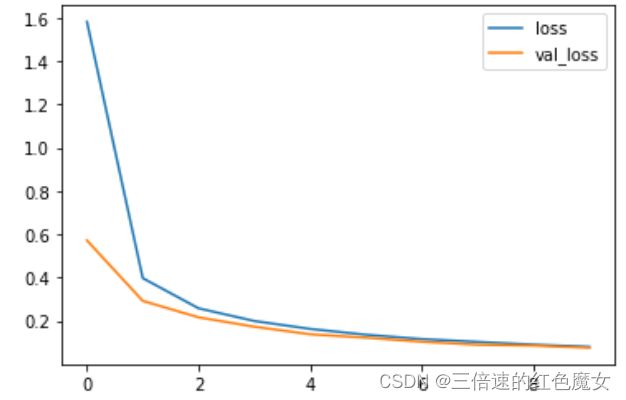

遇到的问题:虽然模型在训练集和测试集上的效果都不错,但把手写的数字喂给模型时,发现其无法识别。
手写的数字
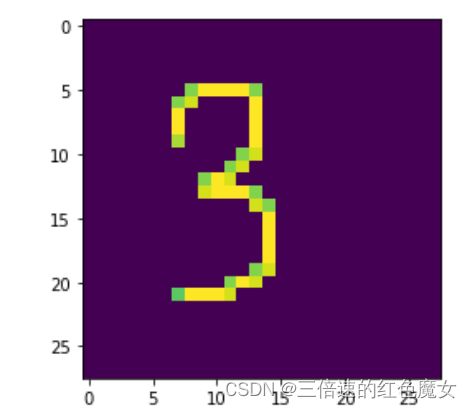
预测结果:

换了好几张手写的图片,模型还是识别率还是很低,找了很久发现在对数据进行了归一化后准确率就降低了,去掉归一化后就能正常识别
# 归一化
train_images = train_images / 255
test_images = test_images / 255
猜测
归一化后精度太高导致计算结果不准确
手写的数字与MNIST中的书写差异非常大,模型出现了过拟合
下图为 数字 7 归一化前后对比

总结:
1.对数据进行不正确的归一化会导致运行结果出问题,在特定情况下,可以把数据处理成二值归一化(0和1)再喂给模型
2.如果想做通用的手写数字识别,要增大更多的数字图像数据训练,一方面更好的提取数字的特征,一方面防止过拟合。
文献阅读
题目《Generic framework for multilingual short text
categorization using convolutional neural network》
摘要
由于在线社交媒体产生的大量数据,所以对文本分类的研究越来越多。有许多挑战需要克服,特别是在短文分类中,短信除了耗时和昂贵的缺点以外,还有拼写错误、讽刺词和缺乏上下文。为了解决这些挑战,作者提出了一种基于卷积神经网络(CNN)的多语言短文分类的GM-ShorT的通用框架。GM-ShorT收集了在线社交媒体数据,这些数据被用作CNN的输入,CNN与单词嵌入机制相结合,对短文本消息进行分类。作者探索了CNN的几种架构,并表明GM-ShorT可以用于多语言短文分类,与其他经典方法相比,其准确率高出13.58%。
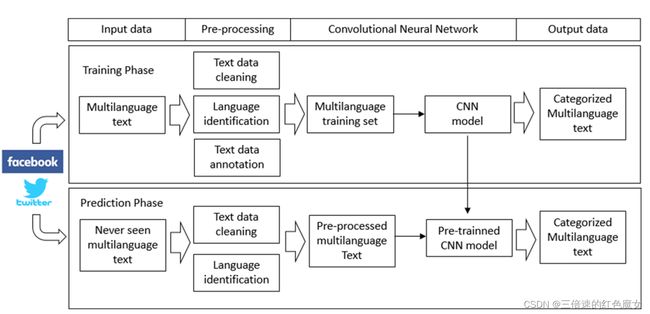
结构流程
下图展示了GM-ShorT的执行流程
数据预处理
在GM-ShorT中,数据来源于在脸书和推特上搜索“埃博拉”得到的帖子。预处理任务分为三个步骤:
(i)文本数据清理:删除表情符号、表情符号、URL和以“@”开头、通常表示用户名的单词来清理文本数据
(ii)语言识别:将用户的帖子分离为英语、日语和葡萄牙语的数据集
(iii)文本数据注释:每个数据集都被手动注释为上图中描述的五个类别。
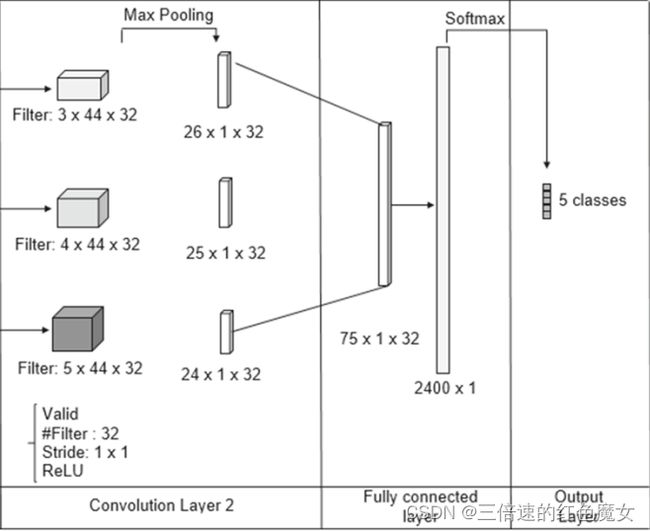
搭建的网络结构
下图显示了GM-ShorT实现的CNN 2L架构
如图所示一共有两层卷积池化层,卷积层使用{3,4,5}的过滤窗口,代表过滤器滑过3,4和5个单词,每个窗口有32个过滤器,没有填充,滑动步长设置为1。在池化层中使用最大池化值,作为每个过滤器对应的最重要特征。然后将池化层向量连接到一个全连接的层中,其中应用softmax函数,最终将每个输入分为表1中描述的五个类之一。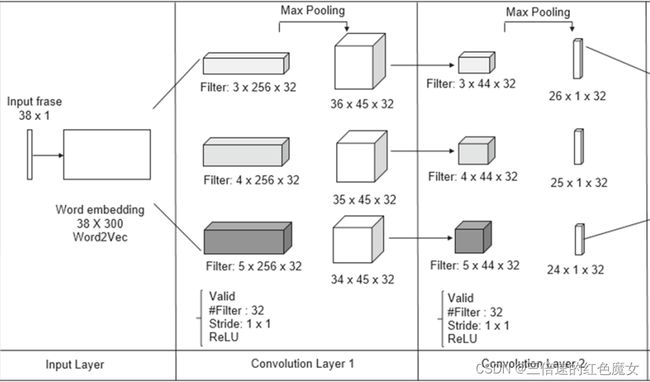
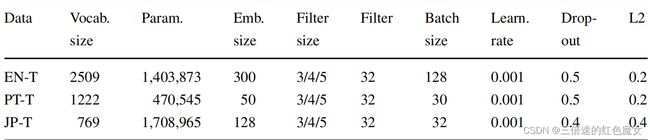
CNN 2L超参数
如图所示,doupout= {0.4、0.5、0.7}、学习率= {0.001、0.005}和L2 lambda = {0.2、0.4},使用Adam优化器,学习率为0.001,三个训练集的训练轮次都为50。
研究成果
作者提出了一个端到端的多语言短文本分类(GM-ShorT)的通用框架,它可用于使用小数据集对社交媒体帖子进行分类,并适用于多语言分类。由于框架底层架构不是一个复杂的深度CNN模型,因此可以很容易地适应新的文本分类案例。此外,该模型不需要一个大的注释数据集,可以用一个小的数据集进行训练,就能取得良好的结果。
总结
下周继续对cnn经典神经网络进行研究和看nlp相关的论文,并且在之后的研究中重视归一化带来的相关问题,以便能掌握正确的归一化和对数据的预处理。