基于Skeleton的手势识别:SAM-SLR
Skeleton Aware Multi-modal Sign Language Recognition解读
- 摘要
- 1. 简介
- 2. Related Work
-
- 2.1 Sign Language Recognition (SLR)
- 2.2 Skeleton Based Action Recognition
- 2.3 Multi-modal Approach
- 3. 方法
-
- 3.1 SL-GCN
-
- 3.1.1 Graph的Construction and Reduction
- 3.1.2 图卷积(Graph Convolution)
- 3.1.3 SL-GCN Block
- 3.1.4 Multi-stream Approach
- 3.2 SSTCN
- 3.3 3D CNNs
- 3.4 Multi-modal Ensemble
- 4. 实验
-
- 4.1 AUTSL Dataset
- 4.2 Baseline Methods
- 4.3 Multi-modal Data Preparation
- 4.4 SL-GCN的性能
- 4.5 SSTCN实验结果
- 4.6 Other Modalities and Ensembles
论文链接:https://openaccess.thecvf.com/content/CVPR2021W/ChaLearn/papers/Jiang_Skeleton_Aware_Multi-Modal_Sign_Language_Recognition_CVPRW_2021_paper.pdf
论文代码:https://github.com/jackyjsy/CVPR21Chal-SLR
摘要
- 手语通常被聋哑人或语言障碍人士用来交流,但需要付出很大的努力才能掌握。
- 手语识别(Sign Language Recognition,SLR)的目的是通过识别特定视频中的手势,弥合手语使用者与他人之间的差距。
- 这是一项重要而富有挑战性的任务,因为手语是通过快速而复杂的手势、身体姿势甚至面部表情来完成的。
- 近年来,基于骨骼的动作识别由于主体与背景变化之间的独立性而受到越来越多的关注。已经有人尝试使用带有姿态估计器的手部检测器来提取手部关键点,并通过神经网络学习识别手语,但没有一种方法比基于rgb的方法更好。
- 为此,我们提出了一种新的骨架感知多模态手语识别框架(Skeleton Aware Multi-modal SLR,SAMSLR),以利用多模态信息实现更高的识别率。
- 我们提出了一个标志手语图卷积网络(Sign Language Graph Convolution Network, SL-GCN)用于嵌入式动态建模,一种新型的可分离时空卷积网络(Separable SpatialTemporal Convolution Network,SSTCN)用于挖掘骨架特征。
- RGB和深度模式也被纳入到我们的框架中,以提供与基于骨骼的方法SL-GCN和SSTCN相补充的全局信息。
- 结果在2021 Looking at People Large Scale Signer Independent Isolated SLR Challenge上获得了最高的性能:RGB(98.42%)和RGBD(98.53%)。
1. 简介
-
与传统的动作识别相比,手语识别(SLR)是一个更具挑战性的问题。(1)首先,手语需要整体的身体动作和精致的手臂/手部动作,才能清晰准确地表达其含义。面部表情也可以用来表达情绪。根据重复的次数,相似的手势甚至可以赋予不同的含义。(2)其次,不同的手语者可能会用不同的方式(例如,速度、地方特征、左手、右手、体型)来表达手语,这使得手语识别更具挑战性。
-
传统的手语识别方法主要采用手工设计的特征,如HOG和SIFT,与传统的分类器如kNN和SVM相连。
-
基于深度学习的手语识别方法包括:视频和时间序列表示的学习方法(RNN, LSTM),动作识别框架(3D CNN)。
-
近年来,基于骨骼的方法在动作识别任务中越来越受欢迎,并因其对动态环境和复杂背景的强适应性而受到越来越多的关注。由于基于骨架的方法为RGB模态提供了补充信息,它们的集成结果进一步提高了整体性能。
-
缺点:这些基于骨骼的动作识别方法依赖于运动捕捉系统提供的groundtruth骨架注释,将自己限制在受控环境中捕获的少量可用数据集上。此外,大多数运动捕捉系统只考虑主体坐标,而不提供手部的groundtruth注释。这些骨架数据包含的信息不足以识别手语,手语包含与身体其他部位相互作用的手势动态运动。
-
在本文中,受全身姿态估计最新进展的启发,我们提出了一种新的基于骨骼的SLR方法,利用预先训练的全身姿态估计器提供的全身关键点和特征。

-
设计了一种新的SLR时空骨架图,并提出了一种手语图卷积网络(SL-GCN)的动态模型嵌入。
-
为了充分利用全身骨骼关键点的信息,提出了一种新的可分离时空卷积网络(SSTCN)。
-
为了进一步提高识别率,我们提出了一个骨架感知多模态手语识别框架(SAM-SLR),将所提出的基于骨架的方法与RGB和RGB- d场景中的其他模式集成在一起。
-
我们的主要贡献可以概括如下:
(1)我们利用整体关键点和图约简,构造了一种新型的SLR骨架图。我们的方法利用预先训练的全身姿态估计器,不需要额外的注释工作。
(2)我们提出SL-GCN从全身骨骼图中提取信息。据我们所知,这是第一次成功尝试利用全身骨骼图来解决SLR任务。
(3)我们提出了一种新的SSTCN来进一步挖掘全身骨骼特征,与传统的三维卷积相比,它可以显著提高全身关键点的精度。
(4)我们提出了一个SAM-SLR框架的RGB和基于RGB-D的SLR,它从六种模式学习,并在AUTSL 数据集上获得了SOAT性能。我们的方法在RGB and RGB-D tracks in the CVPR-21 Challenge on Isolated SLR上获得第一名。
2. Related Work
2.1 Sign Language Recognition (SLR)
- SLR的其中一个挑战是同时捕捉全局身体运动信息和局部手臂/手/面部表情。当前的方法还不足以有效地捕获完整的运动信息。
2.2 Skeleton Based Action Recognition
- 基于骨骼的动作识别主要从人体关节的位置和运动中探索独特的动作模式。
- 一方面,骨架数据可以单独利用,以执行有效的动作识别。另一方面,它也可以与其他模式协作,实现多模态学习,以获得更高的识别性能。
- 最近,首次尝试设计一种名为ST-GCN的基于图的方法,通过图卷积网络(Graph Convolutional Network, GCN)对骨架数据中的动态模式进行建模。
- 然而,基于骨架的SLR仍有待开发。直接将ST-GCN扩展到SLR的尝试并不成功,仅在20个分类上实现了约60%的识别率,这明显低于手工制作的特征。
2.3 Multi-modal Approach
- 多模态方法旨在探索从不同资源/设备捕获的动作数据,以提高最终性能。
- 它的基础是假设不同的模式包含独特的运动信息,这些信息可能相互补充,最终获得全面和独特的动作表示。
- 我们的目标是联合探索更多视觉、深度、手势和手部模式,从各个方面捕捉信息,并通过一个通用框架将它们融合在一起,以实现更高的性能。
3. 方法
3.1 SL-GCN
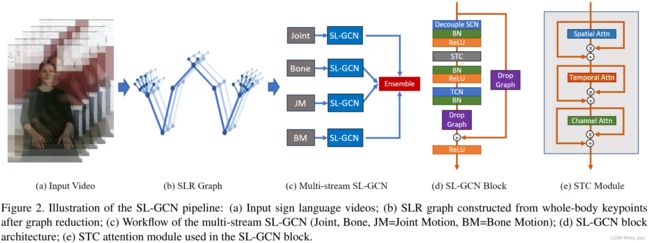
- 我们构建了一个时空图(spatio-temporal graph)为手语识别建模人体骨骼的动力学,并提出了一种具有注意机制的SL-GCN模型来从graph中提取运动动力学。我们还采用了多流方法来进一步提高性能。
3.1.1 Graph的Construction and Reduction
- 对于动作识别,研究人员倾向于使用Kinect v2等动作捕捉系统提供的groundtruth骨架注释。不幸的是,该系统不提供手部注释。
- 我们使用预训练的全身姿态估计网络,从视频中被检测的人估计出133个关键点。然后根据人体的自然连接,将相邻的空间维度关键点连接起来,在时间维度上将所有关键点与自身连接起来,就可以构建一个时空图。在这个graph中,节点集V={v_i,t|i=1,…,N,t=1,…,T}包括所有的面部 landmarks,身体、手、脚的keypoints。
- 那么空间维的邻矩阵A可以构造为:

其中 d(vi,vj) 计算骨架节点vi到vj之间的最小距离(最短路径上的最小节点数)。 - 但是,与动作识别中节点数量较少的图不同,全身骨架图中节点和边的数量较多,给模型引入了大量的噪声。另外,如果两个节点相距较远,中间节点较多,则很难了解节点之间的相互作用。
- 简单的使用包含133个全身节点的骨骼graph在实验中只能得到较低的准确率。
- 剩下的图中每只手有10个节点,上半身有7个节点,如图2 (b)。实验证明,该图包含了SLR所需要的基本信息。graph reduction 后的模型收敛速度更快,识别率显著提高。
3.1.2 图卷积(Graph Convolution)
- 为了捕捉嵌入在全身骨架图中的模式,我们采用了带有空间划分策略的spatio-temporal GCN对动态骨架进行建模。
- 空间GCN的实现可以表示为

其中邻矩阵A表示体内连接,单位矩阵I表示自连接,D表示(A+I)的对角度,W为卷积的可训练权矩阵。
3.1.3 SL-GCN Block
- 我们提出的SL-GCN Block 是由解耦空间卷积网络、自注意和图下降模块构成的.
- 如图2(d)所示,我们提出的SL-GCN网络的基本 GCN block 由一个解耦的空间卷积层(Decouple SCN),一个STC注意力模块(spatial, temporal and channelwise),一个时间卷积层(TCN)和一个DropGraph模块组成。
- Decouple SCN 在不增加额外成本的情况下提高GCN建模能力。
- DropGraph模块避免过拟合。
- STC注意机制由空间注意模块、时间注意模块和通道注意模块组成,以级联配置连接,如图2(e)所示。
3.1.4 Multi-stream Approach
- 在SLR中,1st-order表示(关节坐标),2nd-order表示(骨向量),和它们的运动向量都值得被研究。
- 如图2©所示,我们的多流SL-GCN使用关节、骨、关节运动和骨运动(joint, bone, joint motion, and bone motion)。
- Bone数据是通过按照人体的自然连接,将关节数据以向量形式表示,从源关节指向目标关节来生成的。鼻子节点被用作根关节,因此它的骨向量被赋值为零。
- 设源关节和目标关节表示为:


在(x;y;s)表示x-y坐标和置信度分数. - Bone向量计算为:

- 运动数据是通过计算关节和骨流中相邻帧之间的差异而生成的。
- Joint motion计算为:

- Bone motion计算为:

- 我们分别训练每个流,并通过使用3.4节中描述的相同的集成策略将它们与权重相加,从而组合它们的预测结果。
- 我们曾尝试采用ResGCN中提出的早期融合多流方法,通过多个输入块捕获多流特征,然后将它们连接在一起。然而,实验结果并没有提供更好的性能,所以我们坚持使用后期集成方法,并将其留待未来的工作中进行探索。
3.2 SSTCN
-
除了使用由全身姿势网络生成的关键点坐标,我们还提出了一个SSTCN模型来从全身特征识别手语。
-
我们从每个视频的60帧中提取33个关键点的特征作为模型的输入,其中鼻子1个landmark,嘴巴4个landmark,肩膀2个landmark,肘部2个landmark,手腕2个landmark,手上22个landmark。
-
所有的特征都使用最大池被下采样到24 × 24。
-
我们不使用三维卷积,而是使用二维卷积层对输入特征进行单独处理,减少了参数,更容易收敛。
-
Pipeline如图4所示

-
总共分为4个阶段:
(1)在第一阶段,我们将特征从60 × 33 × 24 × 24重塑为60 × 792 × 24,并将其输入到1 × 1的卷积层中,这意味着我们在这一阶段只处理时间信息。
(2)然后对特征进行洗牌,分成60组,利用分组3 × 3卷积从不同帧中提取相同关键点特征之间的时空信息。该阶段主要处理时间信息和部分空间信息。
(3)在第三阶段,特征再次洗牌,分成33组。我们仍然使用分组的3 × 3卷积,但只提取每一帧的空间信息。
(4)最后,使用几个3 × 3全连通层来生成预测特征。 -
在前3个阶段,所有的输出都加上一个残差。
-
此外,在每个模块中都部署了dropout层,以避免过拟合。
-
为了进一步提高性能,我们利用Swish激活函数,它可以写成:

-
采用标签平滑技术来缓解过拟合,在数学上,标签平滑可以表示为:

-
交叉熵损失(cross-entropy loss)可以被替换为:

3.3 3D CNNs
- 对动作识别的研究表明,多模态集成可以进一步提高每种模态的性能,因此我们使用3D cnn为其他模态:RGB frames, optical flows, depth HHA 和 depth flow构建了一个简单但有效的基线。
- 研究中,我们发现ResNet2+1D,它在三维空间和时间卷积解耦并逐个进行,提供了流行的3D CNN架构中最好的效果。
- 我们发现,增加体系结构深度并不会提高性能,反而会使网络更容易过拟合。
- 因此,在我们的实验中,我们选择在kinetics数据集上预训练权重的ResNet2+1D-18作为骨干网。
- 为了进一步提高RGB帧的识别率,我们在中国手语(CSL)数据集上对模型进行了预训练。
- 我们发现,在CSL上进行预训练可以提高模型的收敛性,最终精度提高约1%。
- 与SSTCN相同,我们将ReLU激活替换为Swish激活,并使用对应交叉熵损失的标签平滑技术,以避免过拟合。
3.4 Multi-modal Ensemble
- 我们使用一个简单的综合方法来综合上述四种模式。
- 具体来说,我们将每个模态的最后全连接层的输出保存在softmax层之前。这些输出的大小为n_c,其中n_c是类的数量。
- 我们根据每个模态在验证集上的准确性为它们分配权重,并将它们与权重相加作为我们最终的预测得分.

其中q表示每个模态的结果,α_1,2,3,4,5,6是超参数,根据验证集上的集合精度进行调优。我们使用argmax()操作符找到分数最高的索引作为最终预测类。 - 在我们的实验中,我们在RGB模式使用α = [1,0:9,0:4,0:4]和在RGB-D模式使用α = [1,0.9,0.4,0.4,0.4,0.1] 。
- 我们尝试了其他的集成方法,如早期融合或训练全连接层来集成最终的预测。尽管如此,我们发现我们上面提出的最简单的方法给了我们最好的精确度。
4. 实验
4.1 AUTSL Dataset
- AUTSL用于土耳其手语的一般SLR任务。
- 采集过程中使用Kinect V2传感器.
- 具体来说,43名有20个背景的签名者被分配执行226个不同的签名者动作。
- 它包含38336个视频剪辑,这些视频剪辑被分割为训练、验证和测试子集。
- 表1列出了挑战中使用的平衡数据集的统计摘要:

4.2 Baseline Methods
- 我们将AUTSL benchmark和SLR挑战排行榜中的最佳模型作为这里的基线模型(基线RGB和表6中的基线RGB-D)。
- 具体而言,baseline模型主要采用CNN + LSTM结构构建,其中利用2D-CNN模型提取每一帧视频的特征,并在这些二维CNN特征的基础上采用双向lstm (BLSTM)算法提取它们的时间关系。
- 在二维CNN模型之后插入一个特征池模型(feature pooling model,FPM),以获得特征的多尺度表示。
- 一个时空注意力模型建立在BLSTM的特征之上,以便更好地聚焦于SLR的重要时空信息。
4.3 Multi-modal Data Preparation
(1)Whole-body Pose Keypoints and Features:
- 我们使用一个经过预先训练的HRNet全身姿态估计器MMPose从RGB视频中估计133个点的全身关键点,并构建3.1.1节中的27个节点骨架图。
- 我们将图处理为四种流(关节、骨、关节运动和骨运动)。采用随机抽样、镜像、旋转、缩放、抖动和移位等方法进行数据增强。
- 我们在实验中使用的样本长度为150帧。如果一个视频的帧数少于150帧,我们会重复该视频,直到我们得到150帧。关键点的坐标归一化为[-1,1]。
- 对于3.2节中的骨架特征,我们为每帧选择33个关节特征。将从每个视频中统一采样60帧。
(2)RGB Frames and Optical Flow
- RGB视频的所有帧都被提取并保存为图像,以更快的并行加载和处理。
- 按照[64]的方法,通过OpenCV和CUDA实现的TVL1算法获得光流特征。
- 将x、y方向的输出流程图按通道尺寸拼接。
- 基于从全身姿态估计中获得的关键点,裁剪RGB帧和光流帧并调整大小为256×256。
- 在训练过程中,我们为每个视频随机采样32个连续帧。在测试时,我们从输入的视频中统一抽样5个这样的片段,并对其预测得分取平均值。
(3)Depth HHA and Depth Flow
- 我们从深度视频中提取HHA特征作为另一种方式。HHA功能将深度信息编码到rgb类的3通道输出中,其中HHA代表水平视差、高于地面的高度和角度法线。使用HHA代替直接使用灰度深度视频,可以更好地理解场景,提高识别率。
- 我们观察到提供的深度视频带有一个mask。因此,在生成HHA特征时,我们屏蔽这些区域,用零填充它们。我们提取的带有mask的HHA示例可以在图3©中找到。

- 我们对待HHA特性的方式与数据增强中的RGB帧相同。此外,我们遵循与RGB从深度模态中提取光流(命名为深度流)完全相同的过程。
- 与RGB流相比,深度流更清晰,并捕获不同的信息,如图3(e)所示。
4.4 SL-GCN的性能
- 根据Top-1和Top-5识别率,我们提出的SL-GCN的结果如表2所示。

- 这证明了我们提出的多流SL-GCN模型使用全身骨架图的有效性。
- 我们的SL-GCN在其他单模态模型中表现最好,如表6所示。

- 基于graph的方法的另一个主要优势是,与使用RGB帧的3D cnn相比,它的运行速度要快得多,因为数据不太复杂,需要更低的计算操作。
- 对提出的SL-GCN模型的消融研究见表3。

- 表3可知graph reduction技术是对性能最重要的贡献。
- 如果不进行graph reduction,GCN模型很难从节点和边太多的骨架图的复杂动态中学习。
- 数据增强技术(即随机采样、镜像、旋转、移动、抖动)在学习嵌入的动态方面也很关键,因为GCN模型很容易在数据上过拟合。
- 解耦GCN模块、DropGraph模块和STC注意机制都有助于我们最终的识别率。
4.5 SSTCN实验结果
- 对比结果如表4所示

- 从表中我们可以发现,在相同尺度的特征上,我们的SSTCN与ResNet3D和ResNet2+1D相比具有最高的精度。
- 通过更大的特征大小,我们的SSTCN可以实现更好的性能。
4.6 Other Modalities and Ensembles
- 我们在其他模式下的基线3D cnn结果见表6。

- 关键点方法代表了我们提出的多流SL-GCN,在其他单模态方法中,它的性能最好。
- 如果我们考虑使用SSTCN作为与SL-GCN相同的模态(都是基于骨架的)的基于特征的方法,它们的集成结果获得了更高的识别率,如表7所示。

- 我们观察到,由于引入的噪声较小,深度流比RGB流提供了稍好的精度。
- 表5中还提供了使用RGB帧对3D CNN架构的消融研究。

- 从消融研究中,我们发现标签平滑和swish激活都分别提高了1%和2%的识别率。
- 表7显示,RGB All和RGB- d All的集成结果表明,基于全身骨架的方法能够与其他方法协作,进一步提高最终识别率。