Learning with Noisy Correspondence for Cross-modal Matching 文献翻译 & 代码简析
Learning with Noisy Correspondence for Cross-modal Matching
基于噪声对应的跨模态匹配学习

Learning with Noisy Correspondence for Cross-modal Matching
- 文献翻译
- Abstract 摘要
- 1 Intorduction 简介
- 2 Related works 相关工作
-
- 2.1 Cross-modal Matching 跨模态匹配
- 2.2 Learning with Noisy Labels 基于噪声标签学习
- 3 The Proposed Method 提出的方法
-
- 3.1 Co-divide 共划分
- 3.2 Co-Rectify 共校正
- 3.3 Robust Cross-modal Matching 鲁棒的跨模态匹配
- 3.3 Discussions on Matching Loss 关于匹配损失的探讨
- 4 Experiment 实验
-
- 4.1 Datasets and Performance Measurements 数据集和性能测量
- 4.2 Implementation Details 实现细节
- 4.3 Comparisons with State of The Arts 与其他工作的比较
- 4.4 Comparison to pre-trained model 与预训练模型的比较
- 4.5 Experimental Analysis 实验分析
-
- 4.5.1 Study on Robustness and Generalizability 鲁棒性和可泛化性研究
- 4.5.2 Visualization on the Co-divide and Co-rectify 共划分和共校正的可视化研究
- 4.5.3 Ablation Study 消融实验
- 4.5.4 Noisy Samples 噪声样本
- 5 Conclusion 总结
-
- Broader Impact Statement 更广泛的影响报告
- Acknowledgements 致谢
- References 参考文献
- 代码简析
-
- vocab.py
-
- class
- function
- run
- data.py
-
- class
- function
- utils.py
-
- class
- function
- model.py
-
- class
- function
- evaluation.py
- co_train.py
文献翻译
Abstract 摘要
跨模态匹配(Cross-modal Matching) 旨在建立两种不同模态之间的对应关系,是跨模态检索和视觉语言理解等多种任务的基础。尽管近年来提出了大量的跨模态匹配方法并取得了显著的进展,但这些方法几乎都隐含地假设了多模态训练数据是正确对齐的。然而,在实践中,这样的假设是非常昂贵的,甚至不可能满足。在此基础上,我们揭示并研究了跨模态匹配中一个潜在且具有挑战性的方向——噪声对应(Noisy Correspondence),它可以被视为噪声标签(noisy labels) 的一种新范式。不同于传统的噪声标签主要是指类别标签中的误差,我们的噪声对应是指不匹配的配对样本。为了解决这个新问题,我们提出了一种新的噪声对应学习方法,称为噪声对应校正器(Noisy Correspondence Rectifier . NCR)。简而言之,NCR是基于神经网络的记忆效应将数据分为干净分区和噪声分区,然后通过自适应预测模型(adaptive prediction model) 以共同学习(co-teaching) 的方式对相应的数据进行校正。为了验证该方法的有效性,我们以图像-文本匹配为例进行了实验。在Flickr30K、MS-COCO和Conceptual Captions上的大量实验验证了我们方法的有效性。该代码可以从www.pengxi.me访问。
1 Intorduction 简介
跨模态匹配是多模态学习中最基本的技术之一,旨在将不同模态连接起来。近年来,基于深度神经网络(Deep Neural Networks, DNNs)提出了一些跨模态匹配方法[19,11,7,26],并在聚类[29,24]、图像/视频字幕[1,44,22]、跨模态检索[40,19,13]和视觉问题回答[9]等各种应用中取得了显著进展。
一般来说,大多数现有的跨模态匹配方法都将不同的模态嵌入到一个公共空间中,其中正例交叉模态对(positive cross-modal pairs) 的相似性最大化,负例交叉模态对(negative cross-modal pairs) 的相似性最小化。尽管这些方法已经取得了很好的结果,但它们的成功依赖于一个隐含的数据假设,即训练数据在不同模态之间正确对齐。例如,在视觉和语言任务中,文本需要准确描述图像内容,反之亦然。然而,在实践中,注释或收集这样的数据对是非常昂贵且耗时的。特别是考虑到从互联网收集的数据[35,14],不可避免地会有一些不匹配的对(负例),这些对被错误地视为匹配的对(正例)。据我们所知,到目前为止,这种特殊的噪声标签(对应)问题被忽略了,这将显著降低匹配方法的性能,如我们的实验所示。
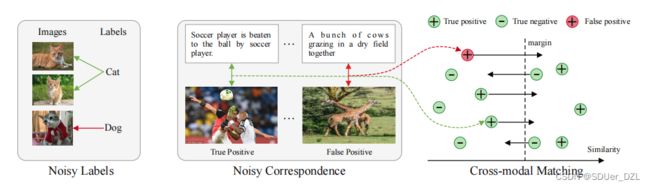
图1:噪声标签 vs. 噪声对应。我们用红线表示噪声样本,用绿线表示干净样本。传统的噪声标签主要是指类别标签中的误差,而噪声对应则是指成对数据中的对齐误差。对于跨模态匹配中的噪声对应,真正例对正确引导了跨模态匹配,而假正例对导致了对训练的不正确监督。
在此基础上,我们提出了一种新的噪声标签范式——噪声对应。与传统的噪声标签不同,噪声对应是成对数据中的对齐误差,而不是类别标注中的误差(见图1)。据我们所知,目前还没有人致力于研究这个新问题,最接近的范式可能是部分视点对齐问题(partially view-aligned problem . PVP)[12,41]。然而,PVP与噪声对应有明显的不同,后者比前者更实用。具体地说,PVP专注于交叉模态对齐是完全不可用的情况,而噪声对应则专注于某些对应是不正确的情况。此外,PVP假设有一些正确对齐的数据可用于训练,而我们的噪声对应假设干净数据和噪声数据是混合的。
为了解决跨模态匹配中的噪声对应问题,提出了一种新的方法——噪声对应校正器(NCR)。我们的方法是基于在[3,39]中观察到的DNNs的记忆效应,即DNNs倾向于在拟合噪声样本之前学习简单的模式。基于这一经验观察,NCR根据损失差异将数据划分为两个相对准确的数据分区,即“噪声”和“干净”子集。之后,NCR采用自适应预测函数进行标签校正,分别从“干净”子集和“噪声”子集中识别出假正例和真正例。此外,我们提出了一种新的三元损失(triplet loss),通过将校正的标签重铸为软间隔(soft margin) 来实现鲁棒的跨模态匹配。
本文的主要贡献和创新之处可以概括如下。i)我们揭示了跨模态分析中的一个新问题,这也是噪声标签的一个新范式,称为噪声对应。与传统的噪声标签不同,噪声对应是成对数据中的对齐误差,而不是分类标注中的误差。据我们所知,这项工作可能是对这个问题的第一次研究。ii)为了解决噪声对应问题,我们提出了一种新的基于噪声对应的学习方法,称为噪声对应校正器(NCR)。NCR的一个主要新颖之处在于,校正后的标签被优雅地重铸成三元损耗的软间隔,从而实现鲁棒的跨模态匹配。iii)为了验证我们方法的有效性,我们对图像-文本匹配任务进行了实验。在三个具有挑战性的数据集上的大量实验验证了我们的方法在合成噪声和真实噪声中的有效性。
2 Related works 相关工作
在这一节中,我们将简要介绍一些最近在带噪声标签的跨模态匹配和学习方面的进展。
2.1 Cross-modal Matching 跨模态匹配
大多数现有的跨模态匹配工作试图学习一个公共空间,其中不同的模态是可比较的。一般来说,现有的工作大致可以分为两类:1)粗粒度匹配(Coarse-grained Matching)。它通常利用多个神经网络来计算一个全局特征,每个网络用于特定的模态[17,37,8]。例如,Kiros等人[17]使用卷积神经网络(CNN) 和 门控循环单元(GRU) 来获取图像和文本特征,同时强制正例对的相似度大于负例对的相似度。为了进一步提高匹配性能,VSE++[8]使用了一些具有代表性的负例对来提高模型的辨别能力。2)细粒度匹配(Fine-grained Matching)。它旨在测量跨模态匹配的细粒度相似度[19,21,7]。例如,SCAN[19]提出学习图像区域和单词之间的潜在语义对应关系,它们分别由自下而上的注意力机制和 GRU 提取。VSRN[21]采用图卷积网络进行语义推理。SGRAF[7]提出构建相似度图对相似度进行推理,并采用注意过滤技术去除无意义的对齐。最近Chun等人介绍了一种新的跨模态匹配范式,即存在于图像和标题中的可能的多对多对应关系。为了实现这一点,他们建议使用概率表示来建模可能的一对多对应关系。
虽然近年来取得了良好的结果,但现有的方法严重依赖于正确对齐的数据。然而实际上收集这种匹配良好的数据既昂贵又耗时。此外,最近的一些研究[35,14]表明,从现实中收集的大规模数据集可以显著提高模型的性能。然而,这样的数据将不可避免地包含一些不匹配的对。因此,对于目前还没有研究过的噪声对应问题,开发一些鲁棒的方法具有很高的期望。不同于图像与字幕之间的多对多对应[6],NCR揭示了噪声对应问题,即图像-文本对的对齐错误,并提出消除噪声对对下游任务的负面影响。
2.2 Learning with Noisy Labels 基于噪声标签学习
为了处理训练数据中可能存在的噪声注释,人们提出了大量的方法,而且几乎都集中在分类任务上[36,27]。为了减少噪声标签的负面影响,现有的工作往往采用鲁棒架构设计、正则化、损失调整(loss adjustment) 或 样本选择(sample selection) 等方法。在这里,我们主要介绍与这项工作最相关的最后两种方法。具体来说,损失调整是通过调整干净和噪声样本对损失的贡献来实现鲁棒性的。例如,Reed等人[32]提出了基于模型预测的自举损失校正。Zhang等人[45]为标签校正提供了一些理论解释,并提出了一种新的标签校正算法。与损失调整方法不同的是,样本选择方法旨在从噪声数据集中选择干净的样本。例如,Arpit等人[3]表明DNNs在拟合噪声样本之前倾向于学习简单的模式,即记忆效应。基于此,Arazo等人[2]提出将损失小的样本作为干净样本处理。为了避免干净样本的选择偏差,共同学习方法[10,43]使用损失较小的样本迭代训练两个网络。最近,DivideMix[20]采用混合匹配(MixMatch)方法[4]对干净和噪声样本进行半监督学习。
与上述噪声标签研究不同,本文关注的是多模态数据对不匹配的噪声对应问题,而不是标注错误的数据点。除了问题的不同,本研究在方法上也与前面的研究有所不同。具体来说,在跨模态匹配中,由于以下两个原因,不可能直接采用这些噪声标签学习方法来解决噪声对应问题。首先,大多数噪声标签学习方法都提出在分类场景下使用模型的预测进行标签校正,而在匹配模型中直接预测给定对的对应关系是难以实现的。其次,即使我们能够以某种方式纠正有噪声的对应,纠正后的实值标签与现有的匹配方法是不兼容的,因为它们大多数假设给定的标签是二进制的。为了解决这些问题,NCR提出了一个自适应预测函数和一种新的三元损耗,将软标签重铸为软间隔。
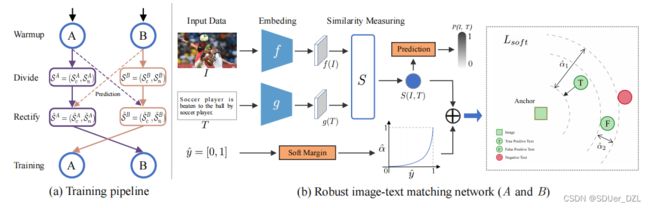
图2:提出的方法的概述。(a))NCR的训练通道(Training pipeline of NCR)。NCR由两个独立的网络(A、B)组成,以共同学习的方式工作。简而言之,NCR首先使用损失Lw在原始训练数据上对网络(A, B)进行预热(“训练热身” . warmup),损失Lw也用于每个样本损失的计算。然后,NCR根据DNNs的记忆效果,使用A或B将训练数据在每一轮训练都分为干净子集和噪声子集,即SA = (SAc, SAn)和SB = (SBc, SBn)。之后,NCR将共同校正{SA, SB}的对应,并使用自适应预测函数得到{ S ^ \widehat{S} S A, S ^ \widehat{S} S B}。最后,将使用 S ^ \widehat{S} S A和 S ^ \widehat{S} S B对网络B和网络A进行交换训练。(b)鲁棒的图像-文本匹配网络(Robust image-text matching network)。例如,网络A分别通过特定于模态的网络 f 和 g 投影图像和文本。然后根据提取的特征f(I)和g(T)计算相似度S(I, T)。为了实现鲁棒的图像-文本匹配,我们将校正后的软标签重铸为损失Lsoft的软间隔。如图所示,对于一个给定的锚点,Lsoft会使真正例比负例更接近它,且有一个较大的间隔 α ^ \widehat{α} α 1,而假正例则有较小的间隔 α ^ \widehat{α} α 2。
3 The Proposed Method 提出的方法
在本节中,我们详细阐述了所提出的方法,即噪声对应校正器(NCR),这可能是解决跨模态匹配中噪声对应问题的第一项工作。在3.1节中,我们引入了共划分(co-divide) 模块,将训练数据分为干净子集和噪声子集。之后,我们将在3.2节介绍如何使用自适应预测函数对标签进行校正。最后,我们在3.3节中详细介绍了如何结合共划分和共校正(co-rectify) 模块来实现鲁棒的跨模态匹配。
3.1 Co-divide 共划分
在不失通用性的前提下,我们首先以图像-文本匹配为例介绍跨模态匹配任务。给定训练数据D={(Ii, Ti, yi)} i=1N,其中N为数据大小,(Ii, Ti)为图像-文本对,yi∈{1,0}表示该对属于同一实例(正)或不属于同一实例(负)。对于有噪声对应的情况,它定义D的某些未知的部分不匹配,即(Ii, Ti)为负对,但错误地标记为yi = 1。为了解决这种噪声对应问题,我们提出了NCR来实现鲁棒的跨模态匹配。
首先,我们将视觉和文本模态分别通过两个特定于模态的网络 f 和 g 投射到公共空间中。然后通过S(f(I),g(T))计算给定图像-文本对的相似度。为简单起见,我们将S(f(I),g(T))表示为S(I, T)。早期的一些实证研究[3]表明,DNNs倾向于先学习简单样本,然后逐渐拟合噪声样本。这种所谓的DNNs记忆效应会导致干净样本的损失相对较低。基于此,我们利用干净样本与噪声样本之间损失分布的差异对训练数据进行划分,如[10,43,2,20]。具体来说,给定一个匹配模型(f, g, S),我们通过以下方法计算每个样本的损失:
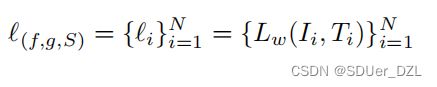 (Eq.1)
(Eq.1)
其中Lw定义为:
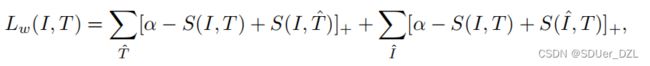 (Eq.2)
(Eq.2)
其中(I, T)是一个正例对,α >0表示给定的间隔,[x]+ = max(x, 0)。在损失中,第一个项将 I 视为覆盖所有负例文本 T ^ \widehat{T} T 的查询,第二个项将 T 视为覆盖所有负例图像 I ^ \widehat{I} I 的查询。然后,我们使用双分量高斯混合模型(Gaussian Mixture Model . GMM)[20,30]拟合所有训练数据的每个样本损失:
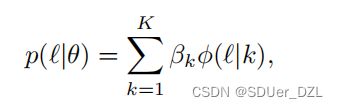 (Eq.3)
(Eq.3)
其中,βk和φ(l | k)分别为第k分量的混合系数和概率密度。基于DNNs的记忆效应,我们将均值较低(即损失较低)的分量作为干净集,将其他的分量作为噪声集。为了优化GMM,我们采用了期望最大化(Expectation-Maximization . EM) 算法。此外,我们计算后验概率wi = p(k| li) = p(k)p( li | k) / p( li)作为第i个样本的干净概率,其中k为均值较低的高斯分量。通过设置阈值{wi}Ni=1,我们将数据分为干净子集和噪声子集。为了简单起见,我们在所有实验中将阈值设置为0.5。
正如在[10]中观察到的那样,如果用自划分的方式训练神经网络,它可能会引入错误积累。为了避免这种情况,我们采用共同学习的方式。具体来说,我们用不同的初始化参数和批处理序列分别训练两个网络A = {f A, gA, SA}和B = {f B, gB, SB}。在每轮训练中,网络A或B将用GMM建模其每个样本的损失分布,并将数据集分为干净子集和噪声子集,然后用于训练另一个网络,即共划分。注意,在共划分之前,对所有训练数据进行warmup处理,以达到与Eq.2中定义的Lw的初始收敛。
3.2 Co-Rectify 共校正
对于A和B中的任意一个,数据D将被分为干净子集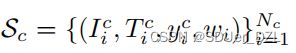
和噪声子集![]() 。然后,共校正模块将对标签进行校正,召回Sn中可能存在的真正例,消除Sc中可能存在的假正例的负面影响。形式上,网络k (k∈{A, B})会将{Sc, Sn}的标签纠正为{ S ^ \widehat{S} S c, S ^ \widehat{S} S n}。校正后的标签由以下公式决定:
。然后,共校正模块将对标签进行校正,召回Sn中可能存在的真正例,消除Sc中可能存在的假正例的负面影响。形式上,网络k (k∈{A, B})会将{Sc, Sn}的标签纠正为{ S ^ \widehat{S} S c, S ^ \widehat{S} S n}。校正后的标签由以下公式决定:
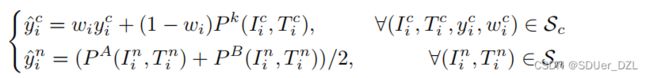 (Eq.4)
(Eq.4)
其中,P A(I, T)/P B(I, T)表示网络A/B给出的预测。Eq. 4的作用如下。一方面,由于大多数Sc对都是真正例,Eq. 4将使用原始的标签yci和模型的预测P (Ici, Tci)来校正对应关系。另一方面,由于大多数Sn对为假正例,Eq. 4将丢弃原始标签,并通过对网络A和B的预测P (Ini, Tni)求平均值来纠正标签。
Eq.4的另一个关键贡献是设计了预测函数P (I, T),它可以准确预测给定的对是正的还是负的。与分类等任务不同,图像-文本匹配的目标是计算相似度,而不是预测给定图像-文本对的标签。为此,一种直接的方法是通过在相似性上设置一个阈值来预测配对。但这种方法需要指定阈值,这是一项艰巨的任务,因为最优值实际上是正负对的相似边界,很难手动指定。或者,我们提出了以下自适应预测函数P (I, T),它可以以数据驱动的方式工作,
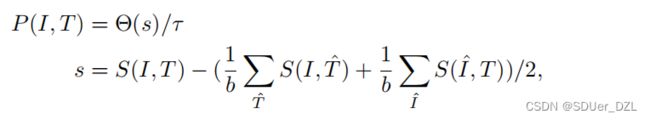 (Eq.5)
(Eq.5)
其中b为批大小,Θ(·)将元素夹在[0,α]的范围内,s是给定对(I, T)与小批中负数的平均值之间的相似间隔,τ是用s表示的最大的10%对的平均相似度间隔。这意味着数据至少有10%的干净对,可以作为相似性锚点进行预测。直观地说,相似性间隔大于τ的对将被预测为1,否则为[0,1)。

3.3 Robust Cross-modal Matching 鲁棒的跨模态匹配
现有的跨模态匹配方法只能处理与NCR校正的软标签不兼容的二进制标签。为了实现鲁棒的图像-文本匹配,我们提出了一种新的三元损失Lsoft,将校正后的标签重铸为软间隔。
![]() Eq.6
Eq.6
其中,对于一个类似于VSE++[8]的给定正对(Ii, Ti)来说,![]() 和
和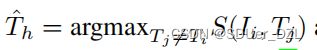 是小批量中最相似的负对。
是小批量中最相似的负对。
软间隔由以下公式自适应的决定:
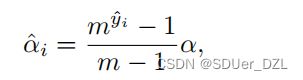 Eq.7
Eq.7
其中m为曲线参数, y ^ \widehat{y} y i为校正后的标签。上述提法是为了达到以下目的,即当 y ^ \widehat{y} y i逼近于0时, α ^ \widehat{α} α i会被分配一个较小值,否则会被分配一个较大值。由于Eq. 6-7,对(I, T)的相似度将比负对的相似度大一个自适应的间隔 α ^ \widehat{α} α i。
尽管有自适应裕度,Lw和Lsoft的另一个主要区别是Lsoft将使用最相似的负对,硬负对。虽然硬负对有助于提高性能,但由于噪声对应的存在,Lw不能从中受益。具体来说,只有真正例的相似度大于硬负例的相似度。但是,在有噪声对应的情况下,假正例的相似度也会大于硬负例的相似度,从而导致在共划分阶段Lw的硬负例不可用。Algorithm 1给出了NCR算法的详细内容。
3.3 Discussions on Matching Loss 关于匹配损失的探讨
为了基于经过改进的软标签实现鲁棒的跨模态匹配,我们通过将标签重铸为软间隔来设计软三元损失。近年来,在匹配模型中处理软标签的工作已经被提出。例如,Wray等人[38]通过直接在预测相似度上设置一个阈值,将软相似度重铸为二进制标签。Kim等人[15]提出了一种对数比匹配损失,其正则化由标签距离比定义,由连续标签计算。Liu等人[25]引入了图像-文本匹配中的huness问题,并提出在一个小批量中考虑所有样本,并根据局部和全局统计数据对它们进行加权。Wray等人[38]通过直接在预测的相似度上设置一个阈值,将软相似度重设为二进制标签。与之不同的是,NCR提出将校正后的软标签重设为三元损失中的软间隔,将大的间隔分配给真正例对,将小的间隔分配给假正例对。因此,更重要的是,我们的损失是专门设计来解决噪声对应问题,而现有的方法则不能。
4 Experiment 实验
在本节中,我们进行了实验来验证NCR在鲁棒图像-文本匹配中的有效性。在实验中,我们使用了三个基准数据集,包括Flickr30K[42]、MS-COCO[23]和Conceptual caption[35]。其中,Conceptual caption具有真实的噪声对应,Flickr30K和MS-COCO具有模拟的噪声对应。
4.1 Datasets and Performance Measurements 数据集和性能测量
实验中使用了三个数据集。具体来说,Flickr30K包含了31000张从Flickr网站收集的图片,每张图片有5个标题。根据[19],我们使用1000个图像进行验证,1000个图像进行测试,其余的用于训练。MS-COCO包含123,287张图片,每张图片有5个字幕。我们遵循[19]中的数据划分,该划分由113,287张训练图像、5,000张验证图像和5,000张测试图像组成。由于Flickr30K和MS-COCO都有很好的注释,我们通过随机打乱训练图像的标题,以特定的百分比(用噪声比表示)来模拟噪声对应。Conceptual caption是由3.3万张图片组成的大规模数据,每张图片都有一个标题。由于该数据集是从互联网上收集的,因此约有3% ~ 20%的对应是错误的[35]。在我们的实验中,我们使用一个名为CC152K的Conceptual caption的子集进行评估。具体地说,我们从训练分割中随机选择150,000个样本用于训练,从验证分割中随机选择1,000个样本用于验证,从验证分割中随机选择1,000个样本用于测试。
根据[19],对于所有图像,我们使用[1]提供的fast - rcnn[33]检测器提取出前36个区域建议,每个区域建议被编码为2048维特征。为了进行评价,我们以K点(R@K)的召回量作为度量。简而言之,R@K是在与查询最近的K点中检索到正确项的查询的百分比。在实验中,我们报告R@1, R@5和R@10进行综合评价。
4.2 Implementation Details 实现细节
NCR是一个通用的框架,它可以使几乎所有现有的跨模态匹配方法对噪声对应都具有鲁棒性。为了验证我们的框架的有效性,我们选择SGR[7]来保证鲁棒性,因为它是图像-文本匹配的最新技术。简单地说,图像区域和文字分别通过一个全连接层(即f)和一个Bi-GRU[34](即g)投影到一个公共嵌入空间。对于相似度函数S,它将结合局部和全局特征,借助[18]中提出的图推理技术,计算给定图像和文本之间的相似度。由于篇幅所限,我们在补充材料中留下了更多的细节和结果。
我们使用默认参数的Adam优化器[16]训练我们的网络,批处理大小为128。为了便于比较,网络f和g与SGR相同,即字嵌入大小为300,联合嵌入空间大小为2048。此外,我们通过实验确定了软间隔α = 0.2和m = 10。在推理阶段,将网络A和网络B预测的相似度取平均值进行检索评价。为了避免过拟合,我们根据验证集上的召回总和选择最佳检查点。
4.3 Comparisons with State of The Arts 与其他工作的比较
在本节中,我们对三个数据集进行比较。基线包括SCAN[19]、VSRN[21]、IMRAM[5]、SGRAF、SGR和SAF[7]。对于Flickr30K和MS-COCO,我们报告了三种不同噪声比的结果,即0%、20%和50%。此外,我们还报告了SGR在干净的Flickr30K和MS-COCO上的结果,通过丢弃用SGR- c表示的噪声对。显然,SGR-C是一个相当强的基线,因为使用的数据不包含有噪声的对应。我们没有报道SGRAF和SAF在干净数据集上的结果,因为我们的框架在本文中只是扩展了SGR。
当噪声率为0%时,我们直接参考相应文献报道的结果。对于有噪声的情况,我们用推荐设置训练基线模型三次,并报告最佳结果。注意,对于SGR,我们发现它对噪声对应非常敏感,如表2所示。为了得到理想的结果,我们在实验上对SGR采用了一个预训练过程(记为SGR*),即在没有硬负例的情况下,对具有普通三元组损失的模型进行训练,然后按照SGR的标准流程进行训练。
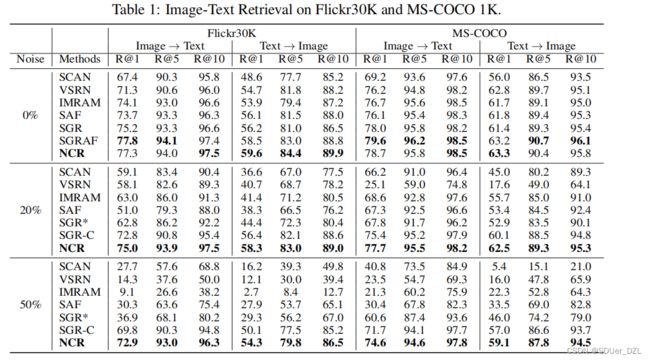
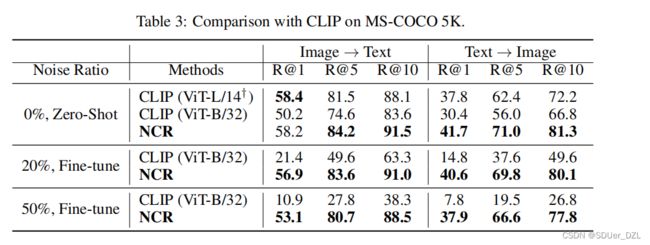
Flickr30K和MS-COCO上的结果。表1显示了Flickr30K和MS-COCO的定量结果。注意,对于MS-COCO,由于空间限制,我们只报告1K测试图像超过5倍的平均结果,并在补充材料中保留完整的5K测试图像上的结果。从结果中可以观察到,在无噪声情况下,NCR与SGRAF具有竞争力,也就是说,尽管NCR被提议实现鲁棒性,但它可以实现最先进的性能。当数据被噪声对应污染时,NCR显著优于所有基线。即使与基于干净数据训练的SGR-C相比,NCR在这四种估值中提高了2.2%、3.1%、2.3%和2.9% R@1。
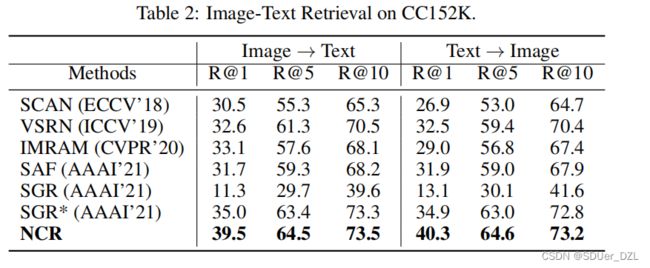
结果CC152K。表2给出了在CC152K上有真实噪声对应的定量结果。从结果中,可以看到我们的NCR在所有指标方面都以相当大的优势持续优于评估的模型。具体而言,NCR分别比文本检索和图像检索中R@1方面的最佳基线高4.5%和5.4%。此外,SGR与SGR*之间的较大性能差距说明了原SGR对噪声的敏感性。
4.4 Comparison to pre-trained model 与预训练模型的比较
在本节中,我们将与预训练的大型模型CLIP[31]进行比较。简而言之,CLIP是在从互联网上获取的大量数据集上进行训练的,因此估计有很多噪声图像-文本对。这样的比较有助于理解,基于大数据的模型(CLIP)和噪声对应建模技术(NCR)哪一种更有利于处理不匹配问题。更具体地说,CLIP声称使用数亿个数据可以忽略可能存在的噪声,而我们相信一个设计良好的算法对于解决噪声对应是必不可少的。注意到,虽然已有的包括CLIP在内的一些作品已经轻微/间接地意识到噪声的存在,但都没有明确给出解决这一问题的解决方案,也没有探索噪声对应的特性。
在实验中,我们在Zero-shot和Fine-tune两种设置下对MS-COCO数据集进行了CLIP。简而言之,第一个设置直接使用释放的预训练CLIP对MS-COCO进行推理,第二个设置使用MS-COCO的有噪声训练数据对预训练模型进行微调。由于CLIP只发布了一些预训练的模型和推理代码3,我们使用非官方代码4对模型进行了32代的微调设置。请注意,CLIP (vitl /14†)尚未发布,我们报告的结果来自原始论文[31]。可以观察到,尽管CLIP使用4亿图像-文本对进行预训练,但在微调期间其性能不可避免地会下降。相比之下,NCR在有噪声对应的情况下实现了匹配性能,说明了算法设计的必要性。
4.5 Experimental Analysis 实验分析
在本节中,我们首先通过实验来证明所提方法的鲁棒性和可泛化性。然后,结合可视化结果,研究了共划分和共校正的效果。之后,我们进行消融研究,验证NCR的不同成分。最后,我们可视化地演示了NCR检测到的一些噪声情况。
4.5.1 Study on Robustness and Generalizability 鲁棒性和可泛化性研究
为了显示NCR的鲁棒性,我们在Flickr30K上进行了实验,将噪声比从0%增加到60%,间隔为10%。此外,为了验证NCR对其他图像-文本匹配方法的可泛化性,我们将SCAN[19]扩展为NCR-SCAN。从图4可以看出,随着噪声比的增加,NCR和NCR-SCAN比SGR和SCAN性能更稳定。NCR (NCR-SCAN)在所有测试中均显著优于SGR (SCAN),说明NCR具有泛化性。
4.5.2 Visualization on the Co-divide and Co-rectify 共划分和共校正的可视化研究
为了进一步研究我们方法中共划分和共校正模块的影响,我们在Flickr30K数据集上进行了实验,通过可视化的每个样本损失分布和模型预测对噪声数据的影响,其中噪声比为20%。为了更好的可视化,我们在这里显示NCR- scan的结果,并将NCR的结果留在补充材料中。如图3(b)所示,大多数噪声样本的损失都大于干净样本损失,验证了DNNs的记忆效果。通过用GMM拟合各样本损失,NCR可以有效地将数据分为干净的和有噪声的两部分。对于共校正的分析,由图3©可知,大部分干净对的校正后软标签范围为[0.3,1],大部分噪声对的校正后软标签范围为[0,0.5]。换句话说,在训练过程中,可以强制真正例的相似度大于负例的相似度,从而消除噪声对应的负面影响。
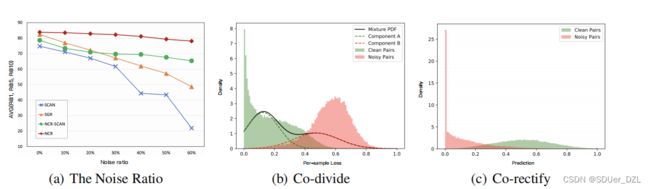
图3 (a) NCR和NCR- scan在不同噪声比下对Flickr30K的检索性能。(b)预热warmup后各样本损失分布及GMM拟合可视化。©对噪声子集建模预测。
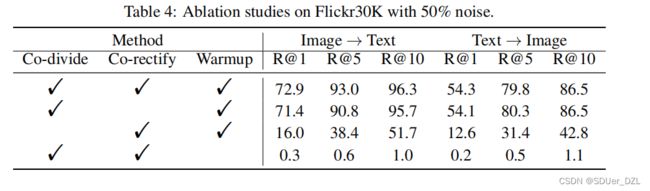
4.5.3 Ablation Study 消融实验
在本节中,我们对噪声比为50%的Flickr30K进行消融研究。如表4所示,要取得令人鼓舞的结果,这三个组成部分都很重要。
4.5.4 Noisy Samples 噪声样本
图4显示了一些由NCR识别的CC152K噪声实例。如图所示,前四对图像-文本是完全不相关的,NCR将成功检测到。对于最后一对,它也将被检测为有噪声的对应,即使视觉和文本形式在粗粒度级别上是相关的,例如,图像和文本都涉及“海滩”。

图4:用NCR正确划分的一些有噪声的例子。
5 Conclusion 总结
本文首次尝试研究跨模态匹配中的一个新问题,即噪声对应,这可能是噪声标签的一个潜在的新方向。为了解决这一问题,我们提出了一种自适应预测函数和一种新的具有软间隔的三元损失来校正噪声对应,从而实现鲁棒的跨模态匹配。大量的实验验证了该方法在处理合成和真实噪声对应时的有效性。
Broader Impact Statement 更广泛的影响报告
跨模态匹配是多模态学习中的一个基础课题,可广泛应用于数据检索、推荐系统和视觉语言理解等领域。这项工作可能是第一个意识到噪声对应问题在众多应用中的重要性和存在性的工作之一。解决噪声对应问题有很多好处,例如,减少人工注释和对齐数据的成本;可以收集和使用更多的数据,即使其中一些数据排列不正确。除了这些好处之外,还应注意潜在的负面影响,包括但不限于:1)数据偏差对决策的自动化偏差风险[28],特别是在航空、医疗保健和自动驾驶汽车领域。2) NCR带来的工作损失,因为它使自动纠正噪声对应成为可能,从而显著降低了人力成本。我们鼓励进一步的工作,以理解和减少上述偏见和风险。
Acknowledgements 致谢
作者将感谢匿名审稿人,他们的宝贵建议和建设性意见显著改进了这一工作。本工作得到国家重点研发计划项目2020AAA0104500的部分支持;四川省重点研究与发展计划项目(资助号:2019YFG0497);部分由NFSC授权U21B2040, 62176171, U19A2078, 61625204和61836006;部分资金来自四川大学未来人生促进会。
References 参考文献
[1] Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6077–6086, 2018.
[2] Eric Arazo, Diego Ortego, Paul Albert, Noel O’Connor, and Kevin McGuinness. Unsupervised label noise modeling and loss correction. In International Conference on Machine Learning, pages 312–321. PMLR, 2019.
[3] Devansh Arpit, Stanisław Jastrz˛ ebski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Y oshua Bengio, et al.
A closer look at memorization in deep networks. In International Conference on Machine Learning, pages 233–242. PMLR, 2017.
[4] David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin Raffel. Mixmatch: A holistic approach to semi-supervised learning. arXiv preprint arXiv:1905.02249, 2019.
[5] Hui Chen, Guiguang Ding, Xudong Liu, Zijia Lin, Ji Liu, and Jungong Han. Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12655–12663, 2020.
[6] Sanghyuk Chun, Seong Joon Oh, Rafael Sampaio de Rezende, Yannis Kalantidis, and Diane Larlus. Probabilistic embeddings for cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8415–8424, 2021.
[7] Haiwen Diao, Ying Zhang, Lin Ma, and Huchuan Lu. Similarity reasoning and filtration for image-text matching. In AAAI, 2021.
[8] Fartash Faghri, David J Fleet, Jamie Ryan Kiros, and Sanja Fidler. Vse++: Improving visualsemantic embeddings with hard negatives. arXiv preprint arXiv:1707.05612, 2017.
[9] Dalu Guo, Chang Xu, and Dacheng Tao. Image-question-answer synergistic network for visual dialog. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10434–10443, 2019.
[10] Bo Han, Quanming Y ao, Xingrui Y u, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels.
arXiv preprint arXiv:1804.06872, 2018.
[11] Yi Hao, Nannan Wang, Xinbo Gao, Jie Li, and Xiaoyu Wang. Dual-alignment feature embedding for cross-modality person re-identification. In Proceedings of the 27th ACM International Conference on Multimedia, pages 57–65, 2019.
[12] Zhenyu Huang, Peng Hu, Joey Tianyi Zhou, Jiancheng Lv, and Xi Peng. Partially view-aligned clustering. In Proceedings of the 34th Conference on Neural Information Processing Systems, NeurIPS’2020, volume 33, Virtual-only Conference, Dec 2020.
[13] Zhenyu Huang, Joey Tianyi Zhou, Hongyuan Zhu, Changqing Zhang, Jiancheng Lv, and Xi Peng. Deep spectral representation learning from multi-view data. IEEE Transactions on Image Processing, 30:5352–5362, 2021.
[14] Chao Jia, Yinfei Y ang, Y e Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V Le, Y unhsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. arXiv preprint arXiv:2102.05918, 2021.
[15] Sungyeon Kim, Minkyo Seo, Ivan Laptev, Minsu Cho, and Suha Kwak. Deep metric learning beyond binary supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2288–2297, 2019.
[16] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
[17] Ryan Kiros, Ruslan Salakhutdinov, and Richard S Zemel. Unifying visual-semantic embeddings with multimodal neural language models. arXiv preprint arXiv:1411.2539, 2014.
[18] Zhanghui Kuang, Yiming Gao, Guanbin Li, Ping Luo, Yimin Chen, Liang Lin, and Wayne Zhang. Fashion retrieval via graph reasoning networks on a similarity pyramid. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3066–3075, 2019.
[19] Kuang-Huei Lee, Xi Chen, Gang Hua, Houdong Hu, and Xiaodong He. Stacked cross attention for image-text matching. In Proceedings of the European Conference on Computer Vision (ECCV), pages 201–216, 2018.
[20] Junnan Li, Richard Socher, and Steven CH Hoi. Dividemix: Learning with noisy labels as semi-supervised learning. arXiv preprint arXiv:2002.07394, 2020.
[21] Kunpeng Li, Y ulun Zhang, Kai Li, Y uanyuan Li, and Y un Fu. Visual semantic reasoning for image-text matching. In ICCV, 2019.
[22] Sheng Li, Zhiqiang Tao, Kang Li, and Y un Fu. Visual to text: Survey of image and video captioning. IEEE Transactions on Emerging Topics in Computational Intelligence, 3(4):297– 312, 2019.
[23] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
[24] Yijie Lin, Y uanbiao Gou, Zitao Liu, Boyun Li, Jiancheng Lv, and Xi Peng. Completer: Incomplete multi-view clustering via contrastive prediction. In CVPR, June 2021.
[25] Fangyu Liu, Rongtian Y e, Xun Wang, and Shuaipeng Li. Hal: Improved text-image matching by mitigating visual semantic hubs. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11563–11571, 2020.
[26] Risheng Liu, Jinyuan Liu, Zhiying Jiang, Xin Fan, and Zhongxuan Luo. A bilevel integrated model with data-driven layer ensemble for multi-modality image fusion. IEEE Transactions on Image Processing, 30:1261–1274, 2020.
[27] Tongliang Liu and Dacheng Tao. Classification with noisy labels by importance reweighting.
IEEE Transactions on pattern analysis and machine intelligence, 38(3):447–461, 2015.
[28] Kathleen L Mosier, Linda J Skitka, Susan Heers, and Mark Burdick. Automation bias: Decision making and performance in high-tech cockpits. The International journal of aviation psychology, 8(1):47–63, 1998.
[29] Xi Peng, Zhenyu Huang, Jiancheng Lv, Hongyuan Zhu, and Joey Tianyi Zhou. Comic: Multiview clustering without parameter selection. In International conference on machine learning, pages 5092–5101. PMLR, 2019.
[30] Haim Permuter, Joseph Francos, and Ian Jermyn. A study of gaussian mixture models of color and texture features for image classification and segmentation. Pattern Recognition, 39(4):695–706, 2006.
[31] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
[32] Scott Reed, Honglak Lee, Dragomir Anguelov, Christian Szegedy, Dumitru Erhan, and Andrew Rabinovich. Training deep neural networks on noisy labels with bootstrapping. arXiv preprint arXiv:1412.6596, 2014.
[33] Shaoqing Ren, Kaiming He, Ross B Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NIPS, 2015.
[34] Mike Schuster and Kuldip K Paliwal. Bidirectional recurrent neural networks. IEEE transactions on Signal Processing, 45(11):2673–2681, 1997.
[35] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 2556–2565, 2018.
[36] Hwanjun Song, Minseok Kim, Dongmin Park, Y ooju Shin, and Jae-Gil Lee. Learning from noisy labels with deep neural networks: A survey. arXiv preprint arXiv:2007.08199, 2020.
[37] Liwei Wang, Yin Li, and Svetlana Lazebnik. Learning deep structure-preserving image-text embeddings. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5005–5013, 2016.
[38] Michael Wray, Hazel Doughty, and Dima Damen. On semantic similarity in video retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3650–3660, 2021.
[39] Xiaobo Xia, Tongliang Liu, Bo Han, Chen Gong, Nannan Wang, Zongyuan Ge, and Yi Chang.
Robust early-learning: Hindering the memorization of noisy labels. In International Conference on Learning Representations, 2021.
[40] Erkun Y ang, Cheng Deng, Wei Liu, Xianglong Liu, Dacheng Tao, and Xinbo Gao. Pairwise relationship guided deep hashing for cross-modal retrieval. In proceedings of the AAAI Conference on Artificial Intelligence, volume 31, 2017.
[41] Mouxing Yang, Y unfan Li, Zhenyu Huang, Zitao Liu, Peng Hu, and Xi Peng. Partially view-aligned representation learning with noise-robust contrastive loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1134–1143, 2021.
[42] Peter Y oung, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions.
Transactions of the Association for Computational Linguistics, 2:67–78, 2014.
[43] Xingrui Y u, Bo Han, Jiangchao Y ao, Gang Niu, Ivor Tsang, and Masashi Sugiyama. How does disagreement help generalization against label corruption? In International Conference on Machine Learning, pages 7164–7173. PMLR, 2019.
[44] Zhou Zhao, Qifan Y ang, Deng Cai, Xiaofei He, and Y ueting Zhuang. Video question answering via hierarchical spatio-temporal attention networks. In IJCAI, pages 3518–3524, 2017.
[45] Songzhu Zheng, Pengxiang Wu, Aman Goswami, Mayank Goswami, Dimitris Metaxas, and Chao Chen. Error-bounded correction of noisy labels. In International Conference on Machine Learning, pages 11447–11457. PMLR, 2020.
代码简析
vocab.py
加载词表
class
- Vocabulary 词表类
简单的词汇包装器
(1)内部成员
①word2idx = {} 字典 根据单词获取索引
word2idx[word] = idx
②idx2word = {} 字典 根据索引值获取单词
idx2word[idx] = word
③idx 应该是指字典中单词-索引值对的长度
(2)function
①__init__(self)
②add_word(self, word) 向词表中添加单词,两个字典同时添加,同时idx+1
③__call__(self, word)
如果类中定义了__call__()方法,那么该类的实例对象也将成为可调用对象;该对象被调用时,将执行__call__()方法中的代码
例如定义实例对象 vocab = Vocabulary()
vocab(word) 就返回 vocab.word2idx[word]
④__len__(self) 返回idx的值,也就是字典中单词-索引值对的长度
function
-
serialize_vocab(vocab, dest)
序列化词表,vocab是一个Vocabulary类对象,dest是一个文件路径,把vocab整成json数据
json.dump():编码,用于将dict类型的数据转成str类型,并写入到json文件 -
deserialize_vocab(src)
解序列化词表,src是json文件的路径,把导入的json数据转成一个Vocabulary类对象vocab并返回它
json.load():解码,用于从json文件中读取数据 -
from_txt(txt)
就是从txt文件中读取数据,读取txt中的每行,并存在一个list中,返回这个list,它叫captions -
from_tsv(tsv)
就是从txt文件中读取数据,也是读取每行,用到两个list,分别是captions和img_ids,captions存放文本数据,跟上边一样,img_ids存放的是图像的ids(暂时不知道什么意思),函数返回的是captions -
build_vocab(data_path, data_name, caption_file, threshold)
构建一个简单的词表包装器,data_path是词表json文件的路径吧,data_path就是文件名了,三个文件名存在一个annotations字典中,caption_file就是那个字典,threshold是个阈值
counter = Counter()是个计数器
①对train_caps和dev_caps分别,首先获取到full_path和captions,使用enumerate遍历captions,对每个caption,通过nltk.tokenize.word_tokenize来分词获取单词列表tokens,使用update可以往counter新增内容
每1000个caption都输出 [i/len] tokenized the captions.
所以这个大for循环好像是为了统计单词在train_caps.txt和dev_caps中出现次数
②如果单词的出现次数小于min_word_cnt,则丢弃,这样得到一个words列表
③创建一个词汇表包装器并添加一些特殊的标记,vocab = Vocabulary(),几个特殊标记< pad>、< start>、< end>、< unk>
④增加词汇量,就是把words里的每个word添加到vocab
最后返回vocab -
main(data_path, data_name)
就是主函数了,根据train_caps和dev_caps建立一个词表,阈值threshold设为4,然后序列化词表并保存为json文件,然后打印保存的路径
run
parser = argparse.ArgumentParser() 创建解析器
添加参数data_path和data_name
解析参数
调用main函数
data.py
数据加载器,用于加载数据集
class
- PrecompDataset 预先计算的数据集类
加载预先计算的标题和图像特征,可能的选项:f30k_precomp, coco_precomp
(1)内部成员
①captions 应该是文本数据的list
②images 图像数据的list
③noise_ratio 噪声率
④data_split 数据集类型 dev or train
⑤mode 模型?
⑥length captions的长度
⑦im_div Rkiros数据在图像中有冗余,我们除以5,10crop没有
⑧t2i_index , t2i_index
⑨_labels
⑩probability
(2)function
①__init_(self, captions, images, data_split, noise_ratio=0, noise_file=“”, mode=“”, pred=[], probability=[])
是为了初始化上述成员,但是方式各有不同
首先assert噪声率在0-1之间
captions, images, data_split, noise_ratio, mode直接根据参数初始化,length初始化为captions的长度
im_div是如果images长度不等于length就初始化为5,否则就是1,原因暂且不明
如果data_split是dev验证集,length就等于1000*im_div,说是coco的开发集很大,因此验证会很慢
t2i_index = np.arange(0, self.length) // self.im_div 说是一张图片有五个标题
下面处理噪声标签,如果data_split是train训练集
t2i_index的值copy到_t2i_index
如果噪声率不是0且存在noise_file的path,就将noise_file导入到t2i_index
如果噪声率不是0但不存在noise_file的path,就自己搞一个有噪声的t2i_index保存到noise_file
保存干净标签到_labels,不正确的为0,正确为1
这里真没看懂
②__getitem__(self, index)
根据index获取image、text、index
③__len__(self) 返回length
function
-
collate_fn(data)
从(图像,标题)元组列表中构建小批张量
参数:
data: (image, caption) 元组列表
image: torch tensor of shape (3, 256, 256).
caption: torch tensor of shape (?) 可变长的
返回:
images: torch tensor of shape (batch_size, 3, 256, 256).
text: torch tensor of shape (batch_size, padded_length).
lengths: list 每个填充标题的有效长度 -
get_dataset(data_path, data_name, data_split, vocab, return_id_caps=False)
获取数据集
对于captions,如果是cc152k_precomp就从tsv文件获取,否则就从txt文件获取,将captions中的每个caption分词后存入captions_token
对于images,就从相应的npy文件中获取
最后返回captions_token和images -
get_loader(captions, images, data_split, batch_size, workers, noise_ratio=0, noise_file=“”, pred=[], prob=[])
获取数据加载器
data_split分为warmup、train和dev,还有[“test”, “testall”, “test5k”]
如果是train,返回labeled_trainloader, unlabeled_trainloader
如果是验证或测试,都是建立相应的data_loader 然后返回它
utils.py
定义了一些工具
class
-
AverageMeter
计算并存储平均值和当前值
(1)内部成员
name、fmt、val、avg、sum、count
(2)function
①__init__(self, name=“”, fmt=“:f”) 根据参数初始化name和fmt,并执行reset
②reset(self) 把val、avg、sum、count都初始化为0
③update(self, val, n=1) 更新各值 val更新为参数val,sum += val * n,count += n,avg=sum/count
④__str__(self) 通过__str__( )函数可以打印对象的属性信息,打印了name、val、avg -
ProgressMeter
意思好像是过程表
(1)内部成员
batch_fmtstr、meters 表?、prefix 前缀?
(2)function
①__init__(self, num_batches, meters, prefix=“”)
根据相应参数初始化meters和prefix,通过_get_batch_fmtstr(num_batches)初始化batch_fmtstr
②display(self, batch)
展示prefix和meters中的每个meter?
③_get_batch_fmtstr(self, num_batches)
真看不懂。。。
function
-
save_config(opt, file_path) 保存配置
将opt的__dict__所有属性存到file_path -
load_config(opt, file_path) 载入配置
将file_path内容载入opt的__dict__ -
save_checkpoint(state, is_best, filename=“checkpoint.pth.tar”, prefix=“”)
处理不稳定的I/O;通常没有必要 暂时不管 -
adjust_learning_rate(opt, optimizer, epoch) 调整学习率
将学习率设置为每30个epoch衰减10的初始LR
动态衰减学习率,具体怎么衰减没太明白
model.py
SGRAF model ?
class
-
EncoderImage 投影图像的网络
通过常用的fc层构建局部区域表示
参数:
images:原始本地检测区域
shape:(batch_size, 36,2048)
返回:
img_emb:最后局部区域嵌入
shape:(batch_size, 36, 1024)
就是通过一些线性层来投影图像数据
(1)内部成员
embed_size 嵌入大小?、no_imgnorm、 fc
(2)function
①__init__(self, img_dim, embed_size, no_imgnorm=False)
初始化embed_size 和no_imgnorm,fc = nn.Linear(img_dim, embed_size),然后调用init_weights()初始化权重
②init_weights(self) 初始化权重
全连接层的Xavier初始化,weight初始化为-r到r,r是个很小的数,偏置b初始化为0
③forward(self, images) 前馈
提取图像特征向量
假设预先计算的特征已经L2标准化
调用线性层得到img_emb,然后在关节嵌入空间中归一化(进行L2归一化),最后返回img_emb
④load_state_dict(self, state_dict)
在pytorch中,torch.nn.Module模块中的state_dict变量存放训练过程中需要学习的权重和偏置系数
覆盖默认的以接受整个模型的state_dict,好像是把state_dict改成有序字典

-
EncoderText 投影文本的网络
使用常用的Bi-GRU或GRU构建局部词表示
参数:
images:原始本地单词id
shape:(batch_size, L)
返回:
img_emb:最终的本地单词嵌入
shape:(batch_size, L, 1024)
(1)内部成员
embed_size、no_txtnorm、embed 嵌入层?、dropout、use_bi_gru、cap_rnn
(2)function
①__init__(self, vocab_size, word_dim, embed_size, num_layers, use_bi_gru=False, no_txtnorm=False )
根据参数初始化embed_size、no_txtnorm,定义嵌入层embed,定义Dropout,定义cap_rnn为使用GRU,然后调用init_weights()初始化权重
②init_weights(self) 初始化权重
把权重初始化为-0.1-0.1
③forward(self, captions, lengths)
处理可变大小的标题
将单词id嵌入到向量中,再通过RNN传播,将输出重塑为(batch_size, hidden_size),最后进行L2归一化
什么玩意 -
VisualSA
通过自我关注建立全局形象表征。
参数:
local:本地区域嵌入,shape:(batch_size, 36,1024)
raw_global:平均区域的原始图像,shape:(batch_size, 1024)
返回:
new_global:自关注的最终图像,shape:(batch_size, 1024)
烦,好像就是投影后的图像数据继续处理 -
TextSA
通过自我注意构建全局文本表示。
参数:
local:本地字嵌入,shape:(batch_size, L, 1024)
raw_global:通过平均单词的原始文本,shape:(batch_size, 1024)
返回:
new_global:自注意的最终文本,shape:(batch_size, 1024)
好像就是投影后的文本数据继续处理 -
GraphReasoning
使用全连通图进行相似图推理
参数:
sim_emb:全局和局部对齐,shape: (batch_size, L+ 1,256)
返回:
sim_sgr:经过几个步骤的推理图节点,shape:(batch_size, L+ 1,256)
真滴看不懂了 -
AttentionFiltration
使用基于门的注意执行相似注意过滤
参数:
sim_emb:全局和局部对齐,shape: (batch_size, L+ 1,256)
返回:
sim_saf:聚合对齐后注意过滤,形状:(batch_size, 256) -
EncoderSimilarity
计算相似度?
通过SGR, SAF, AVE计算图像文本相似度
参数:
img_emb:本地区域嵌入,形状:(batch_size, 36, 1024)
cap_emb:本地字嵌入,形状:(batch_size, L, 1024)
返回:
sim_all:最终的图像文本相似性,形状:(batch_size, batch_size) -
ContrastiveLoss
计算对比损失 -
SGRAF
相似推理与过滤(SGRAF)网络
哎,感觉得先看SGRAF那篇论文,太难了,真看不懂,烦烦烦
总体结构就是图像数据和文本数据分别通过 EncoderImage 和 EncoderText 进行投影,然后通过 EncoderSimilarity 计算相似度,而 EncoderSimilarity 中包含了其他四种网络,所以真的很复杂。。。
function
-
l1norm(X, dim, eps=1e-8) L1归一化X的列
返回归一化之后的X -
l2norm(X, dim=-1, eps=1e-8) L2归一化X的列
返回归一化之后的X -
cosine_sim(x1, x2, dim=-1, eps=1e-8) 返回x1和x2之间的余弦相似度,沿dim计算
咋计算的呢,w12是x1和x2沿dim逐个相乘之和,w1是x1沿dim的L2范数,w2是x2沿dim的L2范数,然后w12/ w1*w2 -
SCAN_attention(query, context, smooth, eps=1e-8
已经完全不知道这是要干嘛了
evaluation.py
验证
-
encode_data(model, data_loader, log_step=10, logging=print)
编码所有可由’ data_loader '加载的图像和标题,估计参数model也会是SGRAF
return img_embs, cap_embs, cap_lens -
shard_attn_scores(model, img_embs, cap_embs, cap_lens, opt, shard_size=1000)
不知道干什么
最后返回的是im-cap相似度矩阵sims,就是计算图像文本相似度吧,估计参数model会是SGRAF -
i2t(npts, sims, per_captions=1, return_ranks=False)
图片->文字(图片注释)
Images:(N, n_region, d)图像矩阵
Captions:(per_captions * N, max_n_word, d)字幕矩阵
CapLens:(per_captions * N)标题长度数组
sims:(N, per_captions * N)相似度矩阵im-cap
return五项指标(r1, r5, r10, medr, meanr) -
t2i(npts, sims, per_captions=1, return_ranks=False)
文字->图像(图像搜索)
Image:(N, n_region, d)图像矩阵
Captions:(per_captions * N, max_n_word, d)字幕矩阵
CapLens:(per_captions * N)标题长度数组
sims:(N, per_captions * N)相似度矩阵im-cap
也是return五项指标(r1, r5, r10, medr, meanr)
co_train.py
训练脚本,这应该才算是核心部分了
按照main函数中执行顺序来看
-
装载词汇包装器 Vocabulary Wrapper
使用vocab.py中的deserialize_vocab方法通过opt的两个变量vocab_path和data_name获取词表vocab,然后将词表长度赋值给opt的变量vocab_size -
加载数据集
使用data.py中的get_dataset方法通过opt的两个变量data_path和data_name还有vocab获取train数据集和dev数据集,分别为captions_train, images_train 和 captions_dev, images_dev -
数据加载器
使用data.py中的get_loader方法通过opt的变量batch_size,workers,noise_ratio,noise_file 还有先前的captions_train, images_train 获取warmup加载器noisy_trainloader以及data_size, clean_labels,还有获取dev加载器val_loader -
建立模型
新建两个SGRAF网络model_A 和 model_B,将best_rsum 与 start_epoch初始化为0,将两个网络的历史损失保存到all_loss中 -
Warmup
如果opt的warmup_model_path变量存在的话,就将warmup模型载入到checkpoint中,并将相应参数分别载入到model_A和B,然后通过validate进行验证
否则就自行进行warmup,通过warmup函数分别对A和B进行warmup,通过save_checkpoint把warmup的结果保存到checkpoint之中,最后也对验证集进行评估
最后将两个网络的历史损失保存到all_loss中 -
训练模型
对于每一轮训练,首先对model_A和B通过adjust_learning_rate进行学习率衰减的操作
然后就是数据集分割,对应论文中的co-divide部分,是通过eval_train进行的
最后通过split_prob得到pred_A和pred_B
接下来分别训练model A和B
以model_A为例,首先通过get_loader获得labeled_trainloader, unlabeled_trainloader,然后就通过train进行训练
之后对验证集进行评估,记住最好的R@ sum和保存检查点
其他function:
-
validate(opt, val_loader, models=[])
计算所有验证图像和标题的编码
如果是cc152k_precomp,per_captions = 1,就是一个图片有一个对应标题,如果是另外两个per_captions = 5
对于models中的每个model(应该就是A和B),通过encode_data获取img_embs, cap_embs, cap_lens,然后清除重复的5图像和保留1图像,然后记录验证的计算时间
然后平均相似度,然后进行文本检索与图像检索,计算用于早期停止的召回的总和
总之就是验证各项指标。。。具体没太看懂 -
warmup(opt, train_loader, model, epoch)
平均记录训练数据
warmup操作,看不太懂啊。。。 -
eval_train(opt, model_A, model_B, data_loader, data_size, all_loss, clean_labels, epoch)
计算每个样本的损失和prob
对于dataloader中的每一项
torch.no_grad()是不需要反向传播的意思,计算损失loss_A和loss_B,然后根据损耗拟合双分量GMM,得到prob_A, prob_B
最后返回的是prob_A, prob_B, all_loss -
split_prob(prob, threshld)
如果prob都大于阈值,即没有噪声数据,我们强制1/100未标记数据,然后pred = prob > threshld,返回pred -
train(opt, net, net2, labeled_trainloader, unlabeled_trainloader=None, epoch=None)
一次训练过程,应该是最最核心的部分了,
修正一个网络用于训练另一个,
labeled_trainloader和unlabeled_trainloader分别代表有标签数据和无标签的加载器,干净集是有标签,噪声集是无标签,分别用pred_labels_l和pred_labels_u保存修正后的标签,好像是要把原始标签分别存入labels_l和labels_u
然后进行标签优化,就是对于labeled,将使用原始的标签yci和模型的预测P (Ici, Tci)来校正对应关系,而对于unlabeled,将丢弃原始标签,并通过对网络A和B的预测P (Ini, Tni)求平均值来纠正标签
然后就训练有标记+无标记的数据,有点看不懂了