【论文阅读】强化学习与知识图谱结合实现序列推荐
前言
论文名称:KERL: A Knowledge-Guided Reinforcement Learning Model for Sequential Recommendation
时间:SIGIR 2020
【目录】
- 前言
- 摘要Abstract
- 1 引入 Introduction
- 2 相关工作 Related Work
- 3 准备工作 PRELIMINARY
- 4 本文方法 Approach
-
- 4.1 MDP公式
- 4.2 Learning Knowledge-Enhanced State Representation
-
- 4.2.1 Sequence-level State Representation
- 4.2.2 Knowledge-level State Representation
- 4.2.3 Deriving the Final State Representation
- 4.3 Setting the Reward with Knowledge Information
-
- 4.3.1 Reward Decomposition
- 4.3.2 Sequence-level Reward
- 4.3.3 Knowledge-level Reward
- 4.4 Learning and Discussion
- 5 实验Experiment
-
- 5.1 实验设置
- 5.2 对比试验
- 5.3 消融实验
-
- 5.3.1Analysis on Knowledge-Enhanced State Representation
- 5 结论与未来工作 Conclusion and Future Work
- 6 个人感悟
摘要Abstract
强化学习开发有效的顺序推荐可以提高预测能力,然而user-item的交互数据可能是稀疏的、复杂的和动态的,所以直接实现强化学习来提升效果并不容易。
-
-
受知识图谱可用性的启发,本文提出了一种新的knowledge-guided 强化学习模型(KERL),将KG信息融合到RL框架中,用于顺序推荐。具体而言,本文将序列推荐任务形式化为马尔可夫决策过程(Markov Decision Process, MDP),并对该框架进行了三个主要技术扩展,包括状态表示、奖励函数和学习算法。首先用KG信息增强状态的表示,同时考虑利用和探索。其次,设计一种能同时计算序列方面和知识方面的复合型奖励函数。第三,提出了新的学习算法训练模型。在下一个项目和下一个会话推荐任务上的大量实验结果表明,本文的模型在四个真实数据集上可以显著优于基线。
-
-
1 引入 Introduction
顺序推荐是指根据用户的顺序交互行为,依次推荐下一项或下几项产品[10,27]。人们提出了各种方法来解决这一任务,如经典的矩阵分解技术[15]和流行的递归神经网络方法[5,9,14]。通常,这些方法使用最大似然估计(MLE)进行训练,逐步拟合观察到的相互作用序列。然而,以往的研究并没有很好地描述优化目标的长期或整体有效性。强化学习(RL)[24]最近的显著进展为这个问题提供了一个有前途的解决方案,考虑最大化长期性能。
-
-
实践中的问题:1.用户物品交互数据可能是稀疏或有限的,不容易直接朝着一个更困难的优化目标学习。第二,RL模型的一个核心概念或机制是探索过程。采用盲目或随机的探索策略来捕捉用户兴趣的变化可能不可靠。从本质上讲,用户行为是复杂多变的,将RL算法应用于顺序推荐需要一个更可控的学习过程。
-
-
事实上,KG数据在推荐任务中被广泛使用[12,26,28]。以往的研究主要利用KG数据进行开发,很少考虑知识信息在勘探过程中的作用。因此,他们无法很好地把握未来用户偏好的潜在变化。
-
-
针对上述问题,本文提出了一种新的知识引导强化学习模型(KERL),将KG信息融合到RL框架中进行顺序推荐。具体地,本文将序列推荐任务形式化为马尔可夫决策过程(MDP),并在此框架中进行了三个主要的技术扩展。首先,本文提出用KG信息增强状态表示。通过学习序列级和知识级状态表示,本文的模型能够更准确地捕捉用户偏好。特别是,本文认为在勘探过程中利用KG信息是非常重要的。为此,本文构建了一个感应网络,旨在预测用户偏好的未来知识特征。这样就可以学习基于知识的用户偏好,同时考虑开发和探索。其次,本文精心设计了一个能够同时计算序列级和知识级奖励信号的复合奖励函数。
-
-
对于sequence-level,使用BLEU指标(ps:在代码中使用的DCG)评估推荐序列的质量。对于knowledge-level,使推荐的序列和ground true逼近。然后提出一个截断式策略梯度来训练模型。针对诱导网络训练的稀疏性和不稳定性,我们进一步引入了一种具有模拟子序列的两两学习机制来改进诱导网络的学习。
-
- 本文的贡献:
将顺序推荐任务形式化为马尔可夫决策过程(MDP),并融合KG信息来提高推荐性能。据作者所知,这是第一次在基于RL的顺序推荐中明确地探索和利用知识图谱数据,特别是在探索过程中。
对序列推荐的MDP框架进行了三个新的扩展,包括状态表示、奖励函数和学习策略。通过这三个主要的扩展,KG信息被有效地利用并集成到基于RL的顺序推荐中。
在四个真实数据集上的实证结果表明,本文的模型在不同指标下的下一个item和下一个会话推荐任务上都可以持续优于最先进的基线。
-
- 本文的贡献:
-
-
-
-
2 相关工作 Related Work
Sequential Recommendation: 序列推荐的目的是根据用户的历史交互数据来预测用户未来的行为。
早期利用马尔科夫链:Rendle等[22]设计了一个个性化的马尔可夫链来提供推荐。此外,Wang等人[27]利用表示学习度量对用户和物品之间的复杂交互进行建模,而Pasricha等人[19]结合翻译和基于度量的方法进行顺序推荐。
对多部序列行为进行建模:基于RNN (Recurrent Neural Networks)的模型在这一领域得到了广泛的应用[5,20,29]。与以往基于mc的模型相比,基于RNN的模型可以很好地捕捉较长的序列行为进行推荐。例如,Quadrana等人[20]利用门控循环单元(GRU)对点击序列进行建模,以实现基于会话的推荐。Li等[16]进一步将注意力机制引入RNN,捕捉用户的顺序行为和主要目的,实现基于会话的推荐。Kang等人[14]提出了一种新的自注意方法来建模用户序列中的成对物品交互。
-
Knowledge-based Recommendation: 随着知识图谱(KG)技术的发展[2,7,17,18],研究者也试图将知识图谱技术纳入推荐系统来提高推荐系统的性能
Huang等[12]利用Memory Network存储和表示知识库信息,提高了顺序推荐的有效性和可解释性。Huang等[11]设计了一种多跳推理体系结构,利用分类法信息改进条目推荐。Wang等人[26]引入偏好传播,在KG中自动传播用户的潜在偏好。Wang等人[28]通过从KG中提取路径,利用高阶关系来获取更多用户和物品之间的连接。尽管KG可以有效地提高性能,但这些工作并没有模拟用户的长期利益,因此性能可能会受到限制。
-
RL-based Recommendation :强化学习被引入推荐系统,其优点是可以考虑用户的长期反馈[34,36]。
[30]提出了一种策略梯度法在KG中搜索路径来解释推荐过程。[37]将排序过程表述为一个多代理马尔可夫决策过程,其中文档之间的相互交互被合并来计算排序列表。[1]探索了基于模型的RL框架上的对抗性训练,以提供建议。据作者所知,这是第一次在基于rl的顺序推荐中明确地讨论和利用KG信息,特别是在探索过程中。
-
3 准备工作 PRELIMINARY
Notation :U表示一组用户,I表示一组items。对每一个用户u, i j : k u = i j u → i j + 1 u → ⋯ → i k u i_{j: k}^{u}=i_{j}^{u} \rightarrow i_{j+1}^{u} \rightarrow \cdots \rightarrow i_{k}^{u} ij:ku=iju→ij+1u→⋯→iku表示用户u的一组交互序列,每个i代表用户在t时刻交互的item。当n=k时,代表着一条子序列。除了序列交互,知识图谱KG也可以用于该任务,每一条记录是一个三元组,分别是两个实体和一个之间的关系。本文假设item集可以与KG相对应,这样就可以获得与每个item对应的知识信息了。
Task Definition:基于交互历史和知识图谱KG,序列推荐的任务目标是用户将会去交互的下一个item。
Markov Decision Process:经典的五元组(状态,动作,转移函数,奖励,策略),不赘述了。
4 本文方法 Approach
本节详细介绍了知识引导强化学习模型,总体架构如图。该方法能够有效地将知识图(KG)信息融合到RL框架中进行顺序推荐。接下来从MDP公式开始,展示本文在状态表示、奖励函数和学习算法上的拓展。简单起见,本文只针对单用户u的方法。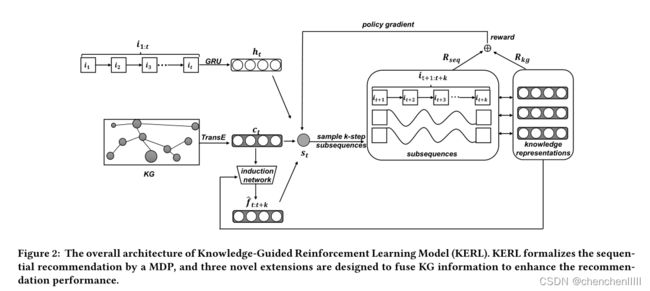
4.1 MDP公式
状态s由序列信息和知识图谱共同构成,可以认为环境的状态包含了所有用于顺序推荐的有用信息,包括交互历史和KG。初始状态设:s0 =[∅,G]。根据论文[6],本文使用一个embedding向量vst对状态st的信息进行编码。期望Vst对表示状态st的有用信息进行编码。
s t = [ i 1 : t , G ] s_{t}=\left[i_{1: t}, \mathcal{G}\right] st=[i1:t,G]
-
agent根据策略π(st)来选择输出的动作,在本文中,我们使用softmax函数来计算选择某项的概率:
-
π ( a t ∣ s t ) = exp { q i j ( a t ) ) W 1 v s t } ∑ i j ∈ I exp { q i j W 1 v s t } \pi\left(a_{t} \mid s_{t}\right)=\frac{\exp \left\{\mathbf{q}_{\left.i_{j\left(a_{t}\right)}\right)} \mathbf{W}_{1} \mathbf{v}_{s_{t}}\right\}}{\sum_{i_{j} \in I} \exp \left\{\mathbf{q}_{i_{j}} \mathbf{W}_{1} \mathbf{v}_{s_{t}}\right\}} π(at∣st)=∑ij∈Iexp{qijW1vst}exp{qij(at))W1vst}
4.2 Learning Knowledge-Enhanced State Representation
之前强化学习的方法主要集中在学习算法上,缺乏对外部知识信息的利用。本文提出引入知识信息来增强状态表示,并设置了两种状态表示,即序列级和知识级状态表示。这样,希望可以利用有信息性的KG数据来指导序列级RL学习算法。本节相当于是对4.1状态表示的一个具体实现,分别从序列信息和知识信息两个方面来表示状态。
4.2.1 Sequence-level State Representation
对于序列信息方面,直接用标准的RNN来对历史交互序列进行编码。GRU为门控循环单元。
h t = GRU ( h t − 1 , q i t ; Φ g r u ) \mathbf{h}_{t}=\operatorname{GRU}\left(\mathbf{h}_{t-1}, \mathbf{q}_{i_{t}} ; \Phi_{g r u}\right) ht=GRU(ht−1,qit;Φgru)
4.2.2 Knowledge-level State Representation
以前的方法主要用KG增强物品或用户表征,而很少用于长期目标的探索。为了在探索和利用之间取得良好的平衡,作者建模两种基于知识的偏好,即当前偏好和未来偏好。
Learning Current Preference:每个item与KG中的实体相关联。使用KG embedding method TransE 得到每一个item的向量,记为 。然后使用平均池化方法来聚合用户交互过的历史Iitem的KG embedding:
c t = ∑ i = 1 t Average ( v e i t ) \mathbf{c}_{t}=\sum_{i=1}^{t} \operatorname{Average}\left(\mathbf{v}_{e_{i_{t}}}\right) ct=i=1∑tAverage(veit)
![]()
注意,这里我们没有考虑上述公式中的时间信息或注意机制,因为它没有显示出比上述简单方法显著的性能改进。
Predicting Future Preference:作为实现有效探索的关键点,本文纳入未来偏好,捕获用户在之后的时间中可能产生的兴趣。直观地说,知道用户未来的偏好对顺序推荐很有用,特别是在RL模型中。基于当前的偏好,作者的想法是开发一个感应网络来直接预测未来的偏好。所以,本文利用多层感知构造了一个神经网络。在时间步t,我们以当前偏好表征ct(式5)为输入,预测一个k步未来偏好表征:
f t : t + k = MLP ( c t ; Φ m l p ) \mathbf{f}_{t: t+k}=\operatorname{MLP}\left(\mathbf{c}_{t} ; \Phi_{m l p}\right) ft:t+k=MLP(ct;Φmlp)
4.2.3 Deriving the Final State Representation
最终的状态表示输出为:
v S t = h t ⊕ c t ⊕ f t : t + k \mathbf{v}_{S_{t}}=\mathbf{h}_{t} \oplus \mathbf{c}_{t} \oplus \mathbf{f}_{t: t+k} vSt=ht⊕ct⊕ft:t+k

4.3 Setting the Reward with Knowledge Information
定义一个合适的奖励函数对于RL算法来说尤为重要。在顺序推荐中,最终的性能通常是基于item-id的精确匹配来度量的。而交互序列是由用户根据其对物品属性或配置文件的偏好(可以从KG中获得)生成的。因此,除了项目级的性能外,度量推断的知识级偏好的质量也很重要。
4.3.1 Reward Decomposition
本文设置的在t时刻的k步奖励为:
R ( s t , a t ) = R s e q ( i t : t + k , i ^ t : t + k ) + R k g ( i t : t + k , i ^ t : t + k ) , R\left(s_{t}, a_{t}\right)=R_{s e q}\left(i_{t: t+k}, \hat{i}_{t: t+k}\right)+R_{k g}\left(i_{t: t+k}, \hat{i}_{t: t+k}\right), R(st,at)=Rseq(it:t+k,i^t:t+k)+Rkg(it:t+k,i^t:t+k),
4.3.2 Sequence-level Reward
论文中使用BLEU指标来评价序列质量,在代码中使用的dcg:
![]()
4.3.3 Knowledge-level Reward
对于真实的和预测的子序列的知识表示,使用余弦相似度作为奖励函数:
R k g ( i t : t + k , i ^ t : t + k ) = c t : t + k ⋅ c ^ t : t + k ⊤ ∥ c t , t + k ∥ ⋅ ∥ c ^ t : t + k ∥ R_{k g}\left(i_{t: t+k}, \hat{i}_{t: t+k}\right)=\frac{\mathbf{c}_{t: t+k} \cdot \hat{\mathbf{c}}_{t: t+k}^{\top}}{\left\|\mathbf{c}_{t, t+k}\right\| \cdot\left\|\hat{\mathbf{c}}_{t: t+k}\right\|} Rkg(it:t+k,i^t:t+k)=∥ct,t+k∥⋅∥c^t:t+k∥ct:t+k⋅c^t:t+k⊤
![]()
作者说可以用任何相似性的度量来代替余弦相似度。
4.4 Learning and Discussion
RL使用截断式策略梯度(类似于PPO):
5 实验Experiment
5.1 实验设置
Dataset:
Amazon:Books,Beauty, and CD
LastFM:音乐收听数据集
Evaluation Metrics: Hit-Ratio@k 和 NDCG@k
5.2 对比试验
本节将模型与几个baseline进行对比,可以看出KERL与基于序列和基于知识的模型的对比中都有着更好的性能,在混合模型中也有着最好的效果。

5.3 消融实验
5.3.1Analysis on Knowledge-Enhanced State Representation
本文的状态表示有三部分组成,通过顺序对每个部分进行检查:

完整的KERL模型还是优于其他组合。
5 结论与未来工作 Conclusion and Future Work
在本文中,提出了一种新的知识引导的强化学习模型,称为KERL,将KG信息融合到RL框架中进行顺序推荐。具体而言,将序列推荐任务形式化为马尔可夫决策过程(Markov Decision Process, MDP),并对该框架进行了三个主要技术扩展,包括状态表示、奖励函数和学习算法。模型的一个主要新奇之处在于,KG信息在MDP框架中被有效地用于探索和利用。实证结果表明,模型在四个真实数据集上可以显著优于基线。作者还对KERL模型进行了详细的分析,以说明本文的扩展的有效性。目前,我们关注的重点是在RL框架中利用知识信息,而不是知识表示。我们采用现有的KG嵌入方法来学习项目的知识表示。作为未来的工作,我们将考虑如何在RL框架中自适应学习更好的顺序推荐知识表示。
6 个人感悟
和之前的那篇交互式的推荐系统相比,本文的模型更加全面。在状态表示方面,不仅使用知识图谱,还加入了序列信息(之前那篇只使用了知识图谱信息)。而且本文模型更加注重用知识图谱进行探索,抓取未来偏好。