机器学习笔记(七)——初识逻辑回归、不同方法推导梯度公式
一、算法概述
逻辑回归(Logistic)虽带有回归二字,但它却是一个经典的二分类算法,它适合处理一些二分类任务,例如疾病检测、垃圾邮件检测、用户点击率以及上文所涉及的正负情感分析等等。
首先了解一下何为回归?假设现在有一些数据点,我们利用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合的过程就称作回归。利用逻辑回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。
线性回归算法后面的笔记会介绍,这里简单对比一下两者,逻辑回归和线性回归的本质相同,都意在拟合一条直线,但线性回归的目的是拟合输入变量的分布,尽可能让所有样本到该条直线的距离最短;而逻辑回归的目的是拟合决策边界,使数据集中不同的样本尽可能分开,所以两个算法的目的是不同的,处理的问题也不同。
二、Sigmoid函数与相关推导
我们想要的函数应该是,能接受所有的输入并且预测出类别,比如二分类中的0或者1、正或者负,这种性质的函数被称为海维赛德阶跃函数,图像如下:
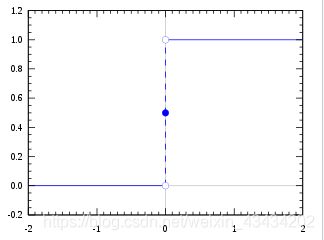
但这种函数的问题在于从0跳跃到1的过程非常难处理,比如我们常接触的多次函数,可能在某种条件下需要求导解决问题;而Sigmoid函数也具有类似的性质,并且在数学上更容易处理,其公式如下:

下图是Sigmoid函数在不同坐标尺度下的两条曲线图。当x为0时,Sigmoid函数值为0.5,随着x的增大,对应的Sigmoid值将逼近于1;而随着x的减小,Sigmoid值将逼近于0。如果横坐标刻度足够大,Sigmoid函数看起来就很像一个阶跃函数。
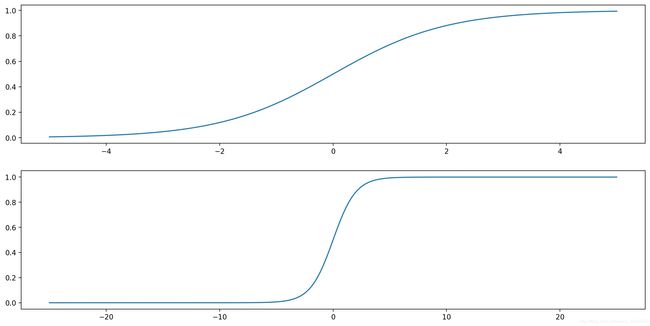
若我们将Sigmoid函数的输入记作z,可推出下面公式:
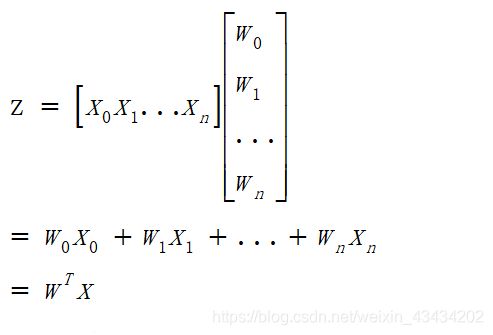
它表示将这两个数值向量对应元素相乘然后全部相加起来得到z值,其中向量x是分类器的输入数据,向量w就是我们要找到的能使分类器尽可能准确的最佳参数。
由上述公式就可得:
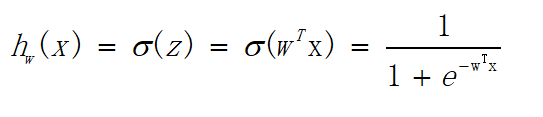
其中 h w ( x ) h_w(x) hw(x)的作用就是给定输入时,输出分类为正向类(1)的可能性。例如,对于一个给定的x, h w ( x ) h_w(x) hw(x)的值为0.8,则说明有80%的可能输出为正向类(1),有20%的可能输出为负向类(0),二者成补集关系。
对于一个二分类问题而言,我们给定输入,函数最终的输出只能有两类,0或者1,所以我们可以对其分类。
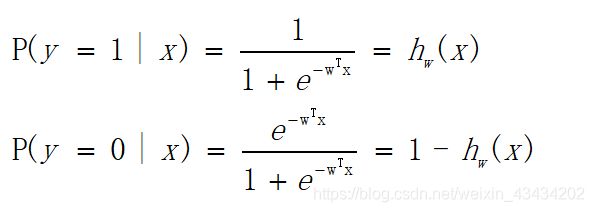
为了运算便捷,我们将其整合为一个公式,如下:
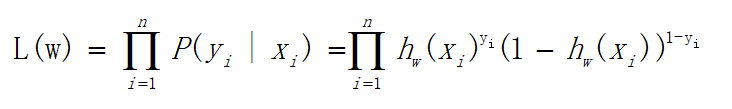
由于乘法计算量过大,所以可以将乘法变加法,对上式求对数,如下:
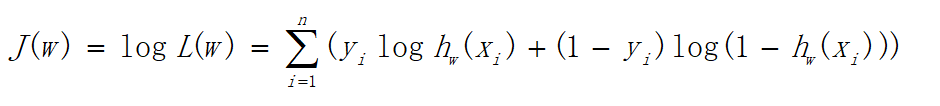
可以看出当y=1时,加号后面式子的值为0;当y=0时,加号前面式子的值为0,这与上文分类式子达到的效果是一样的。L(w)称为似然函数,J(w)称为对数似然函数,是依据最大似然函数推导而成。此时的应用是梯度上升求最大值,如果梯度下降求最小值,可在公式之前乘以 − 1 n -\frac{1}{n} −n1。
为了学习嘛,这里再介绍一下另一种方式,利用损失函数推导应用于梯度下降的公式;损失函数是衡量真实值与预测值之间差距的函数,所以损失函数值越小,对应模型的效果也越好,损失函数公式如下:
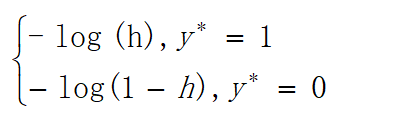
可能只看公式理解相对抽象,通过对应的函数图像足以理解上式,如下:
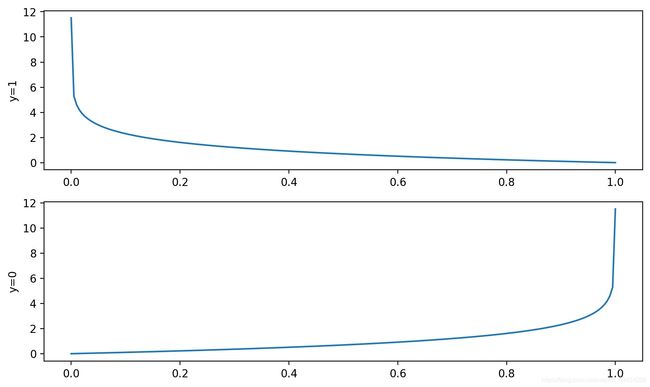
注意!!!公式后面的y*不代表纵坐标 !!!
当类标签y*=1时,对应的-log(x)图像越接近于1,其距离x轴越近,代表其损失越小;反之当类标签y*=0时,对应的-log(1-x)图像越接近于0,其距离x轴越近,代表其损失越小,也就是预测值越接近于真实值。
将两个损失函数综合起来得:

对于m个样本,总损失函数为:
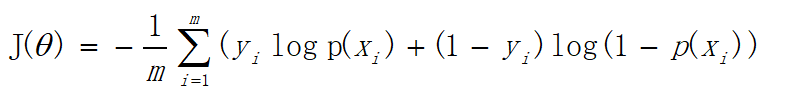
其中m为样本个数、yi为标签,可取0或1、i为第i个样本、 p ( x i ) p(x_i) p(xi)为预测输出。
三、梯度
3.1梯度上升
上面已经列出了一大堆的公式,难道这又要开始一连串的大公式?

心态放平,上文虽说公式有点多,但目的都是为了推出最后的对数似然函数或者总损失函数,掌握这两个是关键,梯度上升和梯度下降也会利用上面的公式做推导,所以二者之间存在关联。首先梯度上升你需要了解一下何为梯度?
如果将梯度记为▽,则函数f(x,y)的梯度可由下式表示:
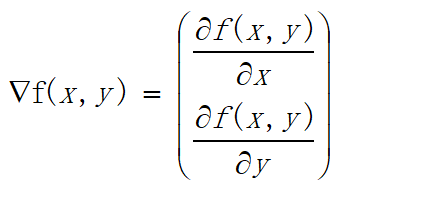
通俗的说,即对多元函数的参数求偏导,并把求得的各个参数的偏导以向量的形式写出来。或者你只要理解这个梯度要沿着x的方向移动 δ f ( x , y ) δ x \frac{\delta f(x,y)}{\delta x} δxδf(x,y),沿着y方向移动 δ f ( x , y ) δ y \frac{\delta f(x,y)}{\delta y} δyδf(x,y)足以,但f(x,y)必须要在待计算的点上有定义且可微。
下图为一个梯度上升的例子,梯度上升法在到达每一个点之后都会重新评估下一步将要移动的方向。从x0开始,在计算完该点的梯度,函数就会移动到下一个点x1。在x1点,梯度会重新计算,继而移动到x2点。如此循环迭代此过程,直到满足停止条件,每次迭代过程都是为了找出当前能选取到的最佳移动方向。
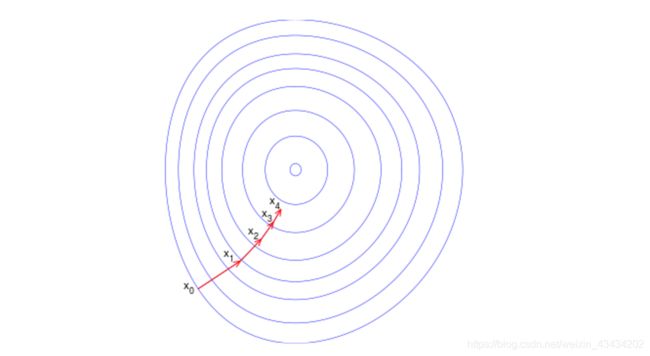
之前一直在讨论移动方向,而未提到过移动量的大小。该量值称为步长,记作 α \alpha α。那么就可以得出梯度上升法的迭代公式:
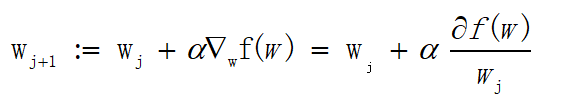
所以对于上文所提及的对数似然函数 J ( w ) J(w) J(w),我们也可以利用上述迭代的方式,一步一步移动到目标值或者无限接近于目标值, J ( w ) J(w) J(w)求偏导的公式如下:
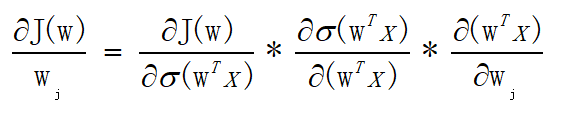
可能有的人看到这个偏导公式有点蒙,其实这里面用到的三个函数公式都是上文所提及的,来回顾一下。
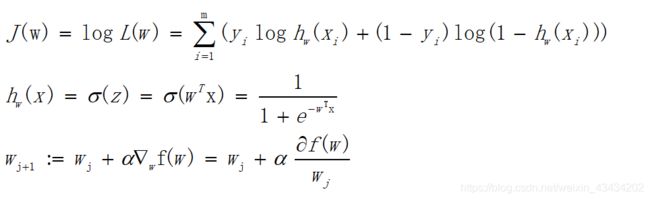
求偏导过程涉及到高数知识,即最外层函数对外层函数求偏导、外层函数对内层函数求偏导、内层函数对其元素求偏导,三者相乘可得出所需偏导。推导过程有些麻烦,这里只给出推导结果,在后面运用时我们也只会运用到最终结果,如下:
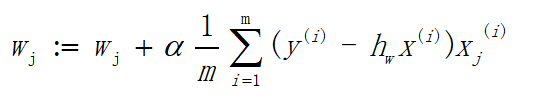
3.2梯度下降
如果利用将对数似然函数换成损失函数 J ( Θ ) J(\Theta) J(Θ),则得到的是有关计算梯度下降的公式,如下:
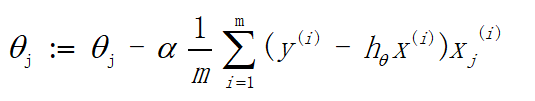
两个公式中的w和 Θ \Theta Θ的含义是一样的,都代表我们所求的最佳回归系数,两个公式对比可以看出梯度上升和梯度下降只有加减号区别之分。下面这个动图就可以很好的展示梯度下降法的过程:
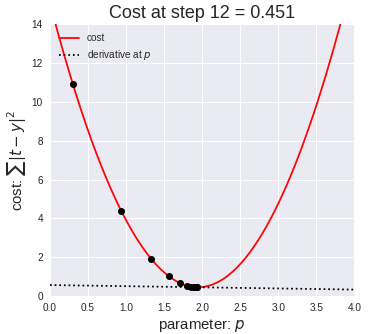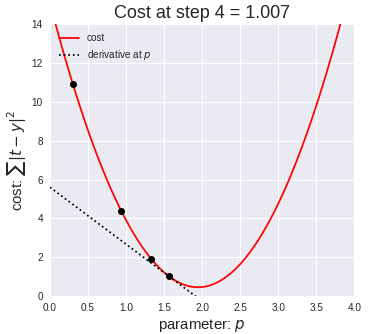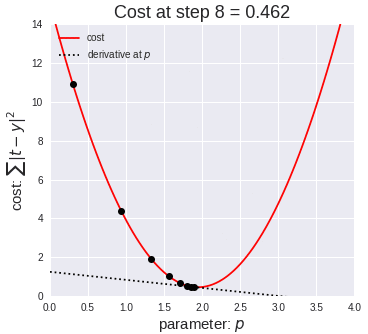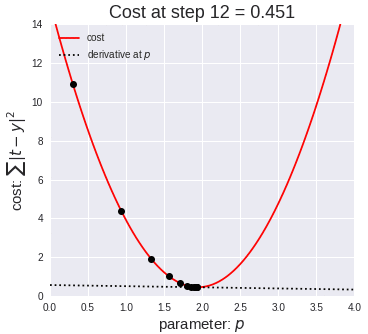
公式推导部分至此结束了,基础偏好的伙伴可能一遍就懂了,但基础偏弱理解起来比较困难,偶当时也是对着书、跟着视频啃了好久,多啃几遍终归会理解的。

四、算法应用
4.1数据概览
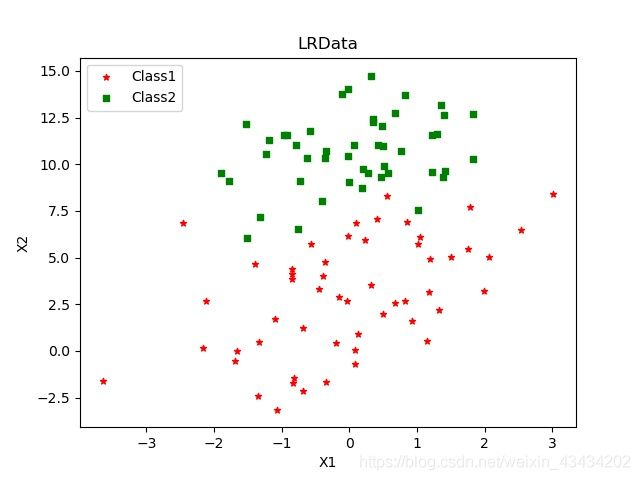
有这样一份数据集,共100个样本、两个特征(X1与X2)以及一个分类标签,部分数据和所绘制图像如下:
| X1 | X2 | 类别 |
|---|---|---|
| 0.197445 | 9.744638 | 0 |
| 0.078557 | 0.059736 | 1 |
| -1.099458 | 1.688274 | 1 |
| 1.319944 | 2.171228 | 1 |
| -0.783277 | 11.009725 | 0 |
在此数据集上,我们将通过梯度下降法找到最佳回归系数,也就是拟合出Logistic回归模型的最佳参数。
该算法的伪代码如下:
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用alpha*gradient更新回归系数的向量
返回回归系数
4.2加载数据集
def loadDataSet():
dataMat = [] # 创建数据列表
labelMat = [] # 创建标签列表
fr = open('LRData.txt','r',encoding='utf-8')
#逐行读取全部数据
for line in fr.readlines():
#将数据分割、存入列表
lineArr = line.strip().split()
#数据存入数据列表
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
#标签存入标签列表
labelMat.append(int(lineArr[2]))
fr.close()
return dataMat, labelMat
loadDataSet函数的作用是打开存储数据的文本文件并逐行读取。每行的前两个值分别对应X1和X2,第三个值是数据对应的类别标签。为了方便计算,函数还在X1和X2之前添加了一个值为1.0的X1,X1可以理解为偏置,即下图中的x0。
4.3训练算法
#sigmoid函数
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
sigmoid函数就是传入一个参数(这里是一个100x1的向量),通过公式计算并返回值。
def gradAscent(dataMatIn, classLabels):
# 将列表转换成numpy的matrix(矩阵)
dataMatrix = np.mat(dataMatIn)
# 将列表转换成numpy的mat,并进行转置
labelMat = np.mat(classLabels).T
# 获取dataMatrix的行数和列数。
m, n = np.shape(dataMatrix)
# 设置每次移动的步长
alpha = 0.001
# 设置最大迭代次数
maxCycles = 500
# 创建一个n行1列都为1的矩阵
weights = np.ones((n,1))
for k in range(maxCycles):
# 公式中hΘ(x)
h = sigmoid(dataMatrix * weights)
# 误差,即公式中y-hΘ(x)
error = labelMat - h
# 套入整体公式
weights = weights + alpha * dataMatrix.T * error
return weights
最后weights返回的是一个3x1的矩阵,运行截图如下:

gradAscent传入参数为loadDataSet的两个返回值,然后通过numpy的mat方法将dataMatrix和labelMat 分为转化为100x3和1x100的矩阵,但labelMat 经过T转置后变成100x1的矩阵。然后初始化权重,利用的方法就是创建一个n行1列的矩阵。整个算法的关键处于for循环中,我们先回顾一下上文的两个公式。
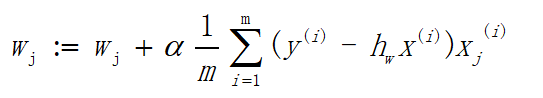
其中h的计算结果即 h w ( x ) h_w(x) hw(x),权重weight为W向量,输入矩阵dataMatrix为x向量。误差error代表 y ( i ) − h w x ( i ) y^{(i)}-h_w x^{(i)} y(i)−hwx(i),有人可能会发现 1 m \frac{1}{m} m1没有出现在代码中,因为 α \alpha α和 1 m \frac{1}{m} m1都为常数,二者相乘也为常数,所以只需要用 α \alpha α代替即可。
公式中的加和部分又怎么体现呢?如果学过线性代数或者了解numpy运算的伙伴应该都理解矩阵的乘法,不理解也没有关系,看下图这个例子,当两个矩阵相乘时,对应元素之间会求和作为最终元素。
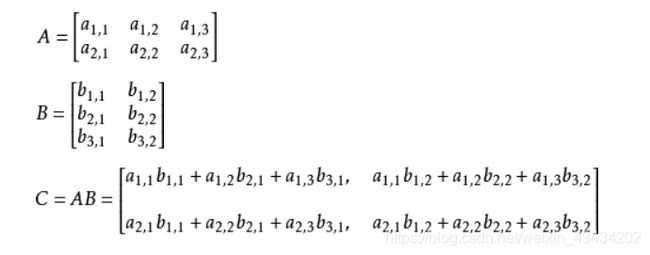
4.4绘制决策边界
def plotDataSet(weight):
#获取权重数组
weight = weight.getA()
# 加载数据和标签
dataMat, labelMat = loadDataSet()
# 将列表转换成numpy的array数组
dataArr = np.array(dataMat)
#获取样本个数
n = np.shape(dataMat)[0]
#创建4个空列表,1代表正样本、0代表负样本
xcord1 = []; ycord1 = []
xcord0 = []; ycord0 = []
# 遍历标签列表,根据数据的标签进行分类
for i in range(n):
if int(labelMat[i]) == 1:
# 如果标签为1,将数据填入xcord1和ycord1
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
# 如果标签为0,将数据填入xcord0和ycord0
xcord0.append(dataArr[i,1]); ycord0.append(dataArr[i,2])
#绘制图像
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s = 20, c = 'red', marker = '*',label = 'Class1')
ax.scatter(xcord0, ycord0, s = 20, c = 'green',marker = 's',label = 'Class2')
#绘制直线,sigmoid设置为0
x = np.arange(-3.0, 3.0, 0.1)
y = (-weight[0] - weight[1] * x) / weight[2]
ax.plot(x, y)
#标题、x标签、y标签
plt.title('LRData')
plt.legend(loc='upper left')
plt.xlabel('X1'); plt.ylabel('X2')
plt.savefig("E:\machine_learning\LR03.jpg")
plt.show()
这部分代码唯一需要注意的是,将sigmoid的值设置为0,可以回忆一下文章刚开始时的Sigmoid函数图像,0是两个分类的分界处。因此,我们设定 0 = w 0 x 0 + w 1 x 1 + w 2 x 2 0=w_0x_0+w_1x_1+w_2x_2 0=w0x0+w1x1+w2x2, x 0 x_0 x0的值为1,所以已知回归系数,就可求得 x 1 和 x 2 x_1和x_2 x1和x2的关系式,从而画出决策边界。
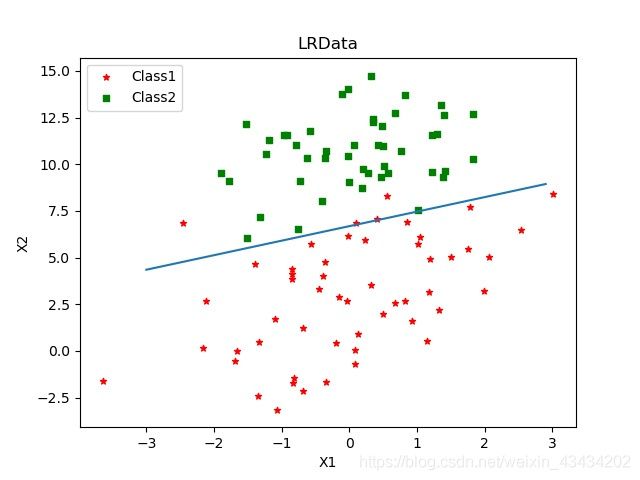
上图可以看出分类的效果还是不错的,根据函数绘制出的直线已经很大程度上将两类样本分隔开,100个样本中,只有五个样本分类错误,其中有三个还是位于回归线上。
五、文末总结
本文所讲的梯度上升公式,属于批量梯度上升,此外还有随机梯度上升、小批量梯度上升,而批量梯度上升每次计算都要计算所有的样本,所以程序计算过程是十分复杂的,并且容易收敛到局部最优,而随机梯度上升将会对算法进行调优,下一篇文章将会介绍随机梯度上升,并分析两者之间的区别。
欢迎关注公众号【喵说Python】,后台回复"逻辑回归"可获取数据和源码供参考,感谢阅读。